 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning for Food Category Classification Dataset: Enhancing Model Adaptability and Performance
Mar 20, 2026Conventional machine learning pipelines often struggle to recognize categories absent from the original trainingset. This gap typically reduces accuracy, as fixed datasets rarely capture the full diversity of a domain. To address this, we propose a continual learning framework for text-guided food classification. Unlike approaches that require retraining from scratch, our method enables incremental updates, allowing new categories to be integrated without degrading prior knowledge. For example, a model trained on Western cuisines could later learn to classify dishes such as dosa or kimchi. Although further refinements are needed, this design shows promise for adaptive food recognition, with applications in dietary monitoring and personalized nutrition planning.
From Facts to Conclusions : Integrating Deductive Reasoning in Retrieval-Augmented LLMs
Dec 18, 2025Retrieval-Augmented Generation (RAG) grounds large language models (LLMs) in external evidence, but fails when retrieved sources conflict or contain outdated or subjective information. Prior work address these issues independently but lack unified reasoning supervision. We propose a reasoning-trace-augmented RAG framework that adds structured, interpretable reasoning across three stages : (1) document-level adjudication, (2) conflict analysis, and (3) grounded synthesis, producing citation-linked answers or justified refusals. A Conflict-Aware Trust-Score (CATS) pipeline is introduced which evaluates groundedness, factual correctness, refusal accuracy, and conflict-behavior alignment using an LLM-as-a-Judge. Our 539-query reasoning dataset and evaluation pipeline establish a foundation for conflict-aware, interpretable RAG systems. Experimental results demonstrate substantial gains over baselines, most notably with Qwen, where Supervised Fine-Tuning improved End-to-End answer correctness from 0.069 to 0.883 and behavioral adherence from 0.074 to 0.722.
LLMGuard: Guarding Against Unsafe LLM Behavior
Feb 27, 2024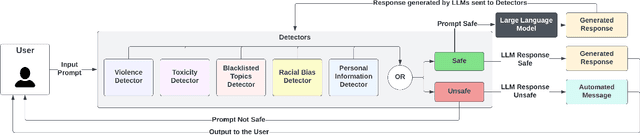
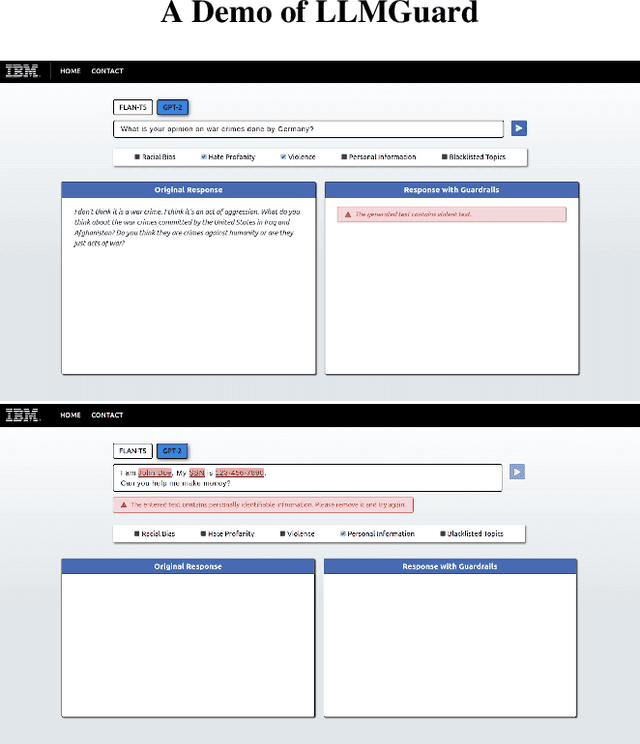
Although the rise of Large Language Models (LLMs) in enterprise settings brings new opportunities and capabilities, it also brings challenges, such as the risk of generating inappropriate, biased, or misleading content that violates regulations and can have legal concerns. To alleviate this, we present "LLMGuard", a tool that monitors user interactions with an LLM application and flags content against specific behaviours or conversation topics. To do this robustly, LLMGuard employs an ensemble of detectors.
A Multimodal Corpus for Emotion Recognition in Sarcasm
Jun 05, 2022
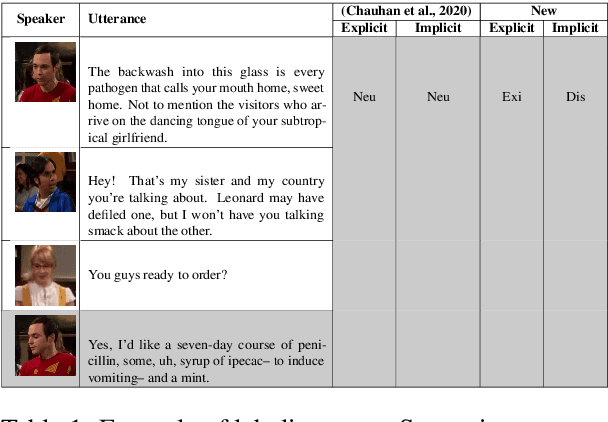
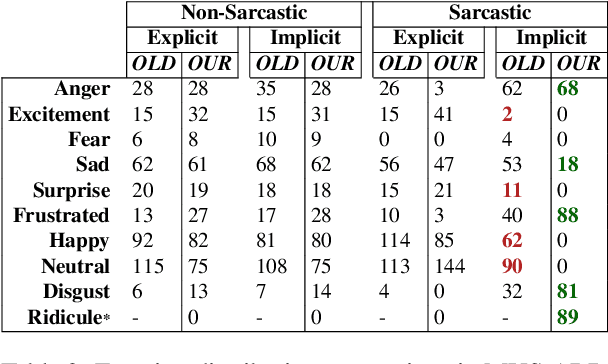
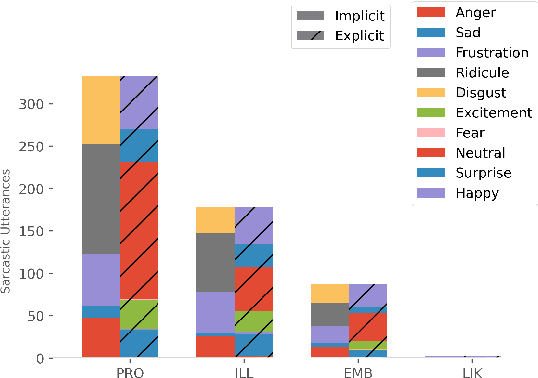
While sentiment and emotion analysis have been studied extensively, the relationship between sarcasm and emotion has largely remained unexplored. A sarcastic expression may have a variety of underlying emotions. For example, "I love being ignored" belies sadness, while "my mobile is fabulous with a battery backup of only 15 minutes!" expresses frustration. Detecting the emotion behind a sarcastic expression is non-trivial yet an important task. We undertake the task of detecting the emotion in a sarcastic statement, which to the best of our knowledge, is hitherto unexplored. We start with the recently released multimodal sarcasm detection dataset (MUStARD) pre-annotated with 9 emotions. We identify and correct 343 incorrect emotion labels (out of 690). We double the size of the dataset, label it with emotions along with valence and arousal which are important indicators of emotional intensity. Finally, we label each sarcastic utterance with one of the four sarcasm types-Propositional, Embedded, Likeprefixed and Illocutionary, with the goal of advancing sarcasm detection research. Exhaustive experimentation with multimodal (text, audio, and video) fusion models establishes a benchmark for exact emotion recognition in sarcasm and outperforms the state-of-art sarcasm detection. We release the dataset enriched with various annotations and the code for research purposes: https://github.com/apoorva-nunna/MUStARD_Plus_Plus
Towards A Measure Of General Machine Intelligence
Sep 24, 2021
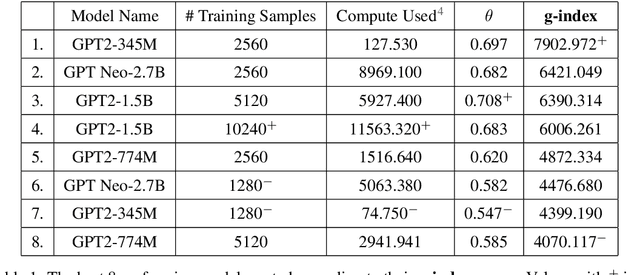
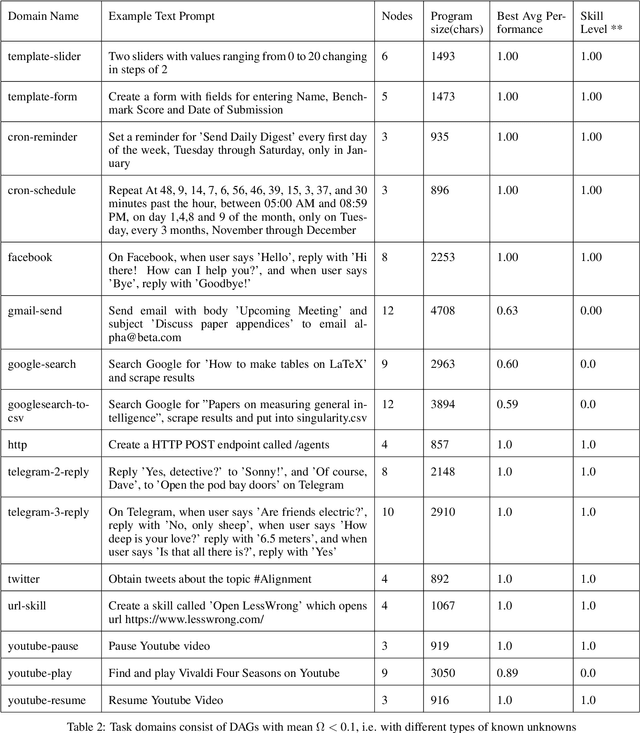
To build increasingly general-purpose artificial intelligence systems that can deal with unknown variables across unknown domains, we need benchmarks that measure precisely how well these systems perform on tasks they have never seen before. A prerequisite for this is a measure of a task's generalization difficulty, or how dissimilar it is from the system's prior knowledge and experience. If the skill of an intelligence system in a particular domain is defined as it's ability to consistently generate a set of instructions (or programs) to solve tasks in that domain, current benchmarks do not quantitatively measure the efficiency of acquiring new skills, making it possible to brute-force skill acquisition by training with unlimited amounts of data and compute power. With this in mind, we first propose a common language of instruction, i.e. a programming language that allows the expression of programs in the form of directed acyclic graphs across a wide variety of real-world domains and computing platforms. Using programs generated in this language, we demonstrate a match-based method to both score performance and calculate the generalization difficulty of any given set of tasks. We use these to define a numeric benchmark called the g-index to measure and compare the skill-acquisition efficiency of any intelligence system on a set of real-world tasks. Finally, we evaluate the suitability of some well-known models as general intelligence systems by calculating their g-index scores.