 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid quantum-classical graph neural networks for tumor classification in digital pathology
Oct 17, 2023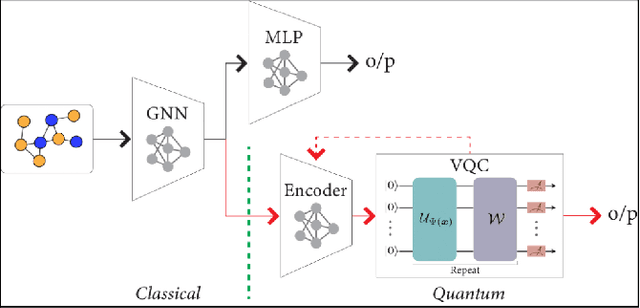
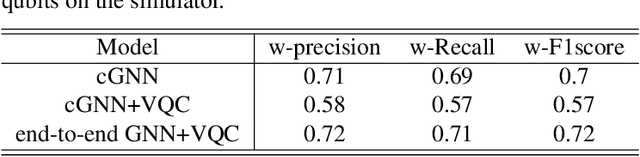
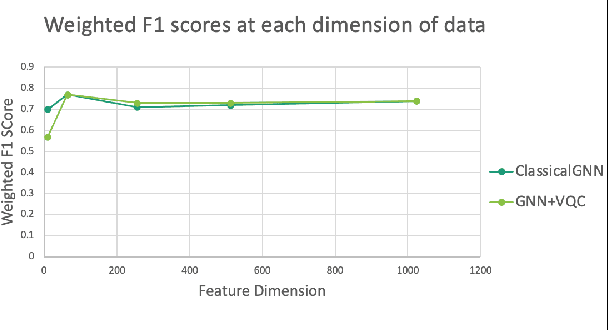
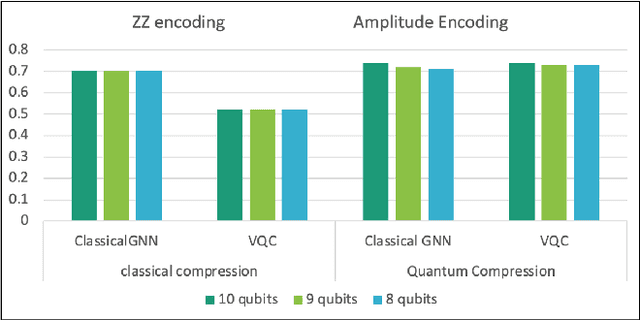
Advances in classical machine learning and single-cell technologies have paved the way to understand interactions between disease cells and tumor microenvironments to accelerate therapeutic discovery. However, challenges in these machine learning methods and NP-hard problems in spatial Biology create an opportunity for quantum computing algorithms. We create a hybrid quantum-classical graph neural network (GNN) that combines GNN with a Variational Quantum Classifier (VQC) for classifying binary sub-tasks in breast cancer subtyping. We explore two variants of the same, the first with fixed pretrained GNN parameters and the second with end-to-end training of GNN+VQC. The results demonstrate that the hybrid quantum neural network (QNN) is at par with the state-of-the-art classical graph neural networks (GNN) in terms of weighted precision, recall and F1-score. We also show that by means of amplitude encoding, we can compress information in logarithmic number of qubits and attain better performance than using classical compression (which leads to information loss while keeping the number of qubits required constant in both regimes). Finally, we show that end-to-end training enables to improve over fixed GNN parameters and also slightly improves over vanilla GNN with same number of dimensions.
Classical ensemble of Quantum-classical ML algorithms for Phishing detection in Ethereum transaction networks
Oct 30, 2022Ethereum is one of the most valuable blockchain networks in terms of the total monetary value locked in it, and arguably been the most active network where new blockchain innovations in research and applications are demonstrated. But, this also leads to Ethereum network being susceptible to a wide variety of threats and attacks in an attempt to gain unreasonable advantage or to undermine the value of the users. Even with the state-of-art classical ML algorithms, detecting such attacks is still hard. This motivated us to build a hybrid system of quantum-classical algorithms that improves phishing detection in financial transaction networks. This paper presents a classical ensemble pipeline of classical and quantum algorithms and a detailed study benchmarking existing Quantum Machine Learning algorithms such as Quantum Support Vector Machine and Variational Quantum Classifier. With the current generation of quantum hardware available, smaller datasets are more suited to the QML models and most research restricts to hundreds of samples. However, we experimented on different data sizes and report results with a test data of 12K transaction nodes, which is to the best of the authors knowledge the largest QML experiment run so far on any real quantum hardware. The classical ensembles of quantum-classical models improved the macro F-score and phishing F-score. One key observation is QSVM constantly gives lower false positives, thereby higher precision compared with any other classical or quantum network, which is always preferred for any anomaly detection problem. This is true for QSVMs when used individually or via bagging of same models or in combination with other classical/quantum models making it the most advantageous quantum algorithm so far. The proposed ensemble framework is generic and can be applied for any classification task
A Multimodal Corpus for Emotion Recognition in Sarcasm
Jun 05, 2022
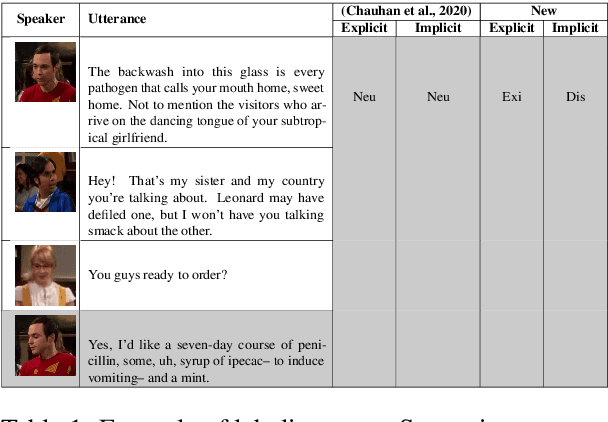
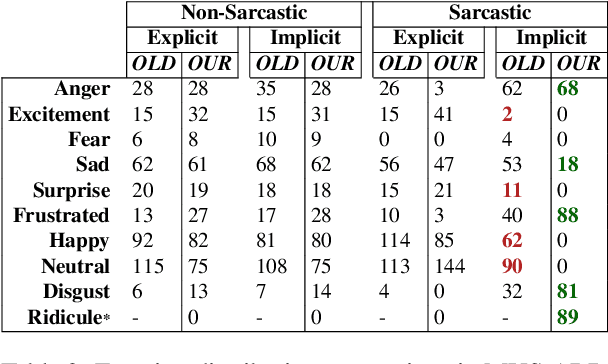
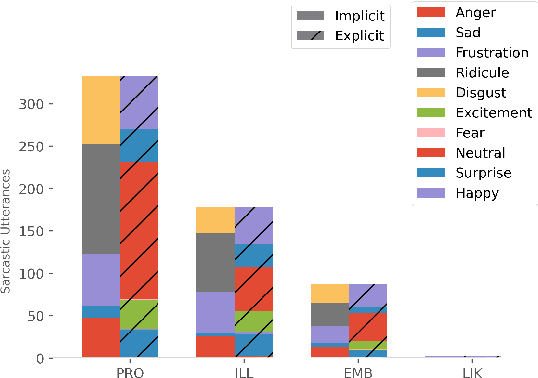
While sentiment and emotion analysis have been studied extensively, the relationship between sarcasm and emotion has largely remained unexplored. A sarcastic expression may have a variety of underlying emotions. For example, "I love being ignored" belies sadness, while "my mobile is fabulous with a battery backup of only 15 minutes!" expresses frustration. Detecting the emotion behind a sarcastic expression is non-trivial yet an important task. We undertake the task of detecting the emotion in a sarcastic statement, which to the best of our knowledge, is hitherto unexplored. We start with the recently released multimodal sarcasm detection dataset (MUStARD) pre-annotated with 9 emotions. We identify and correct 343 incorrect emotion labels (out of 690). We double the size of the dataset, label it with emotions along with valence and arousal which are important indicators of emotional intensity. Finally, we label each sarcastic utterance with one of the four sarcasm types-Propositional, Embedded, Likeprefixed and Illocutionary, with the goal of advancing sarcasm detection research. Exhaustive experimentation with multimodal (text, audio, and video) fusion models establishes a benchmark for exact emotion recognition in sarcasm and outperforms the state-of-art sarcasm detection. We release the dataset enriched with various annotations and the code for research purposes: https://github.com/apoorva-nunna/MUStARD_Plus_Plus
Multi-level Attention network using text, audio and video for Depression Prediction
Sep 03, 2019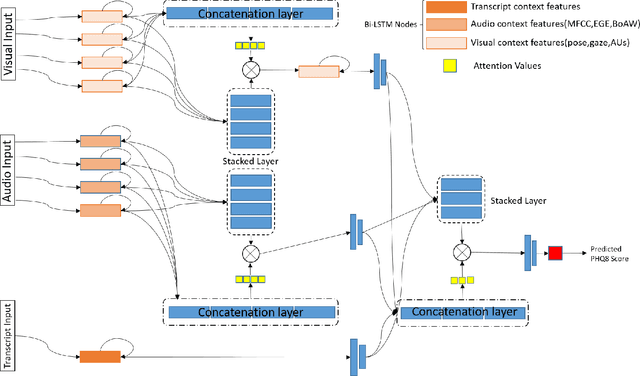


Depression has been the leading cause of mental-health illness worldwide. Major depressive disorder (MDD), is a common mental health disorder that affects both psychologically as well as physically which could lead to loss of lives. Due to the lack of diagnostic tests and subjectivity involved in detecting depression, there is a growing interest in using behavioural cues to automate depression diagnosis and stage prediction. The absence of labelled behavioural datasets for such problems and the huge amount of variations possible in behaviour makes the problem more challenging. This paper presents a novel multi-level attention based network for multi-modal depression prediction that fuses features from audio, video and text modalities while learning the intra and inter modality relevance. The multi-level attention reinforces overall learning by selecting the most influential features within each modality for the decision making. We perform exhaustive experimentation to create different regression models for audio, video and text modalities. Several fusions models with different configurations are constructed to understand the impact of each feature and modality. We outperform the current baseline by 17.52% in terms of root mean squared error.
Improving IT Support by Enhancing Incident Management Process with Multi-modal Analysis
Aug 04, 2019
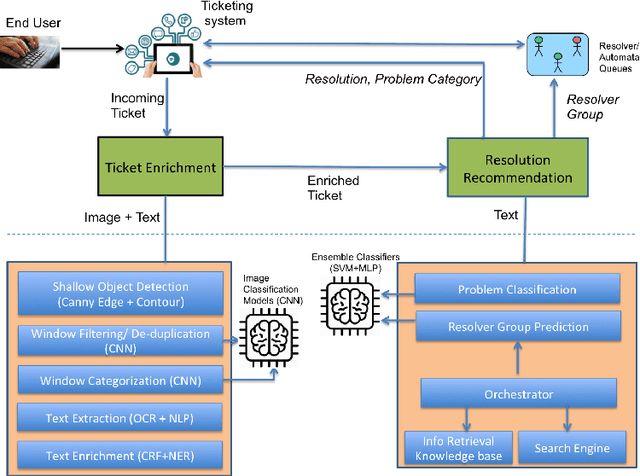
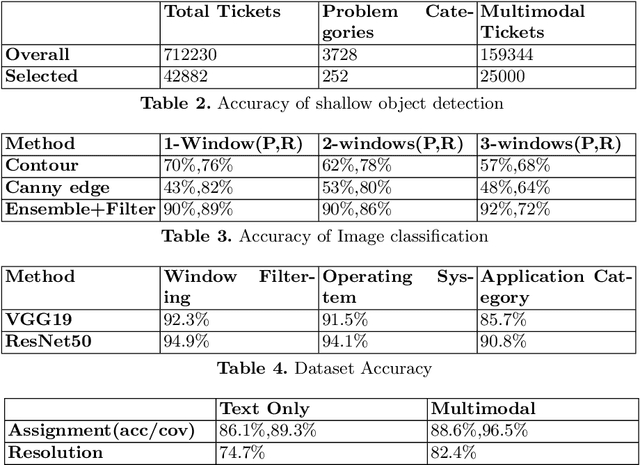
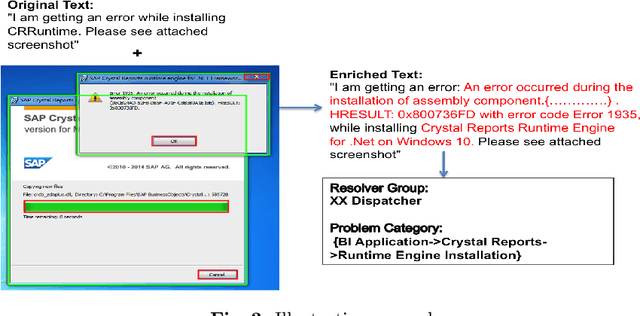
IT support services industry is going through a major transformation with AI becoming commonplace. There has been a lot of effort in the direction of automation at every human touchpoint in the IT support processes. Incident management is one such process which has been a beacon process for AI based automation. The vision is to automate the process from the time an incident/ticket arrives till it is resolved and closed. While text is the primary mode of communicating the incidents, there has been a growing trend of using alternate modalities like image to communicate the problem. A large fraction of IT support tickets today contain attached image data in the form of screenshots, log messages, invoices and so on. These attachments help in better explanation of the problem which aids in faster resolution. Anybody who aspires to provide AI based IT support, it is essential to build systems which can handle multi-modal content. In this paper we present how incident management in IT support domain can be made much more effective using multi-modal analysis. The information extracted from different modalities are correlated to enrich the information in the ticket and used for better ticket routing and resolution. We evaluate our system using about 25000 real tickets containing attachments from selected problem areas. Our results demonstrate significant improvements in both routing and resolution with the use of multi-modal ticket analysis compared to only text based analysis.
Cognitive system to achieve human-level accuracy in automated assignment of helpdesk email tickets
Aug 09, 2018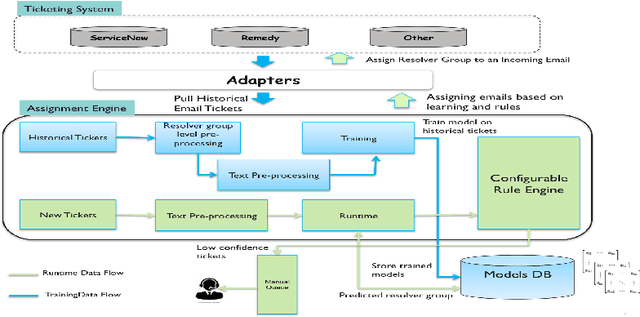
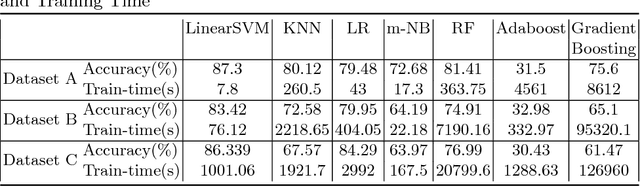
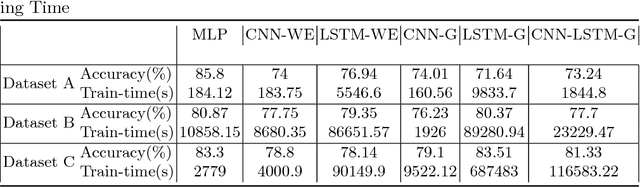
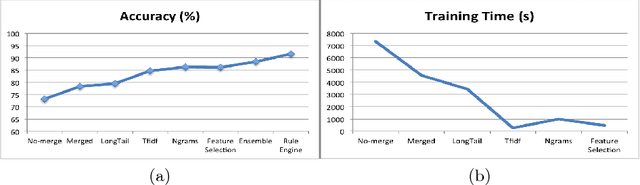
Ticket assignment/dispatch is a crucial part of service delivery business with lot of scope for automation and optimization. In this paper, we present an end-to-end automated helpdesk email ticket assignment system, which is also offered as a service. The objective of the system is to determine the nature of the problem mentioned in an incoming email ticket and then automatically dispatch it to an appropriate resolver group (or team) for resolution. The proposed system uses an ensemble classifier augmented with a configurable rule engine. While design of classifier that is accurate is one of the main challenges, we also need to address the need of designing a system that is robust and adaptive to changing business needs. We discuss some of the main design challenges associated with email ticket assignment automation and how we solve them. The design decisions for our system are driven by high accuracy, coverage, business continuity, scalability and optimal usage of computational resources. Our system has been deployed in production of three major service providers and currently assigning over 40,000 emails per month, on an average, with an accuracy close to 90% and covering at least 90% of email tickets. This translates to achieving human-level accuracy and results in a net saving of about 23000 man-hours of effort per annum.
A hypothesize-and-verify framework for Text Recognition using Deep Recurrent Neural Networks
Feb 26, 2015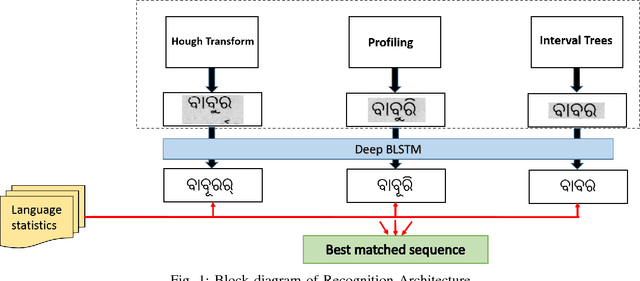
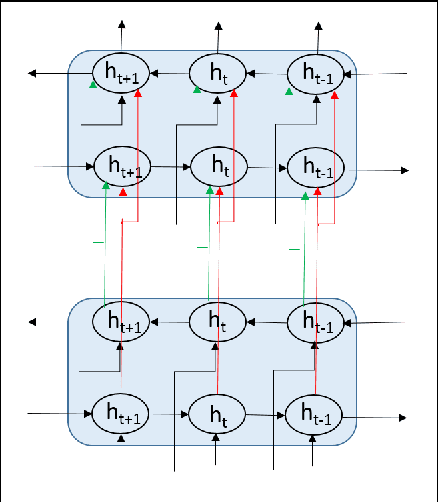


Deep LSTM is an ideal candidate for text recognition. However text recognition involves some initial image processing steps like segmentation of lines and words which can induce error to the recognition system. Without segmentation, learning very long range context is difficult and becomes computationally intractable. Therefore, alternative soft decisions are needed at the pre-processing level. This paper proposes a hybrid text recognizer using a deep recurrent neural network with multiple layers of abstraction and long range context along with a language model to verify the performance of the deep neural network. In this paper we construct a multi-hypotheses tree architecture with candidate segments of line sequences from different segmentation algorithms at its different branches. The deep neural network is trained on perfectly segmented data and tests each of the candidate segments, generating unicode sequences. In the verification step, these unicode sequences are validated using a sub-string match with the language model and best first search is used to find the best possible combination of alternative hypothesis from the tree structure. Thus the verification framework using language models eliminates wrong segmentation outputs and filters recognition errors.