 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Enterprise Systems Need Learned World Models? The Importance of Context to Infer Dynamics
May 12, 2026World models enable agents to anticipate the effects of their actions by internalizing environment dynamics. In enterprise systems, however, these dynamics are often defined by tenant-specific business logic that varies across deployments and evolves over time, making models trained on historical transitions brittle under deployment shift. We ask a question the world-models literature has not addressed: when the rules can be read at inference time, does an agent still need to learn them? We argue, and demonstrate empirically, that in settings where transition dynamics are configurable and readable, runtime discovery complements offline training by grounding predictions in the active system instance. We propose enterprise discovery agents, which recover relevant transition dynamics at runtime by reading the system's configuration rather than relying solely on internalized representations. We introduce CascadeBench, a reasoning-focused benchmark for enterprise cascade prediction that adopts the evaluation methodology of World of Workflows on diverse synthetic environments, and use it together with deployment-shift evaluation to show that offline-trained world models can perform well in-distribution but degrade as dynamics change, whereas discovery-based agents are more robust under shift by grounding their predictions in the current instance. Our findings suggest that, in configurable enterprise environments, agents should not rely solely on fixed internalized dynamics, but should incorporate mechanisms for discovering relevant transition logic at runtime.
Multi-scale Predictive Representations for Goal-conditioned Reinforcement Learning
May 10, 2026This paper investigates robust representation learning in offline goal-conditioned reinforcement learning (GCRL). Particularly in sparse reward scenarios, learning representations that align state and goal latents is a challenge that frequently culminates in representation divergence where the encoder drifts toward a low-dimensional, goal-agnostic subspace that destabilizes policy learning. We address this issue by showing that an agent must acquire a fundamental understanding of its environment across multiple scales, from local physical dynamics to long-horizon goal-directed structure. Building on this insight, we propose Ms.PR, a framework that leverages multi-scale predictive supervision to enforce goal-directed alignment within the latent space. We demonstrate that Ms.PR leads to improved representation quality and strong performance on both vision and state-based tasks. Furthermore, we show that our approach is exceptionally resilient under realistic, challenging data regimes, maintaining state-of-the-art performance across a wide variety of tasks, trajectory stitching scenarios, and extreme noise conditions.
Therefore I am. I Think
Apr 02, 2026We consider the question: when a large language reasoning model makes a choice, did it think first and then decide to, or decide first and then think? In this paper, we present evidence that detectable, early-encoded decisions shape chain-of-thought in reasoning models. Specifically, we show that a simple linear probe successfully decodes tool-calling decisions from pre-generation activations with very high confidence, and in some cases, even before a single reasoning token is produced. Activation steering supports this causally: perturbing the decision direction leads to inflated deliberation, and flips behavior in many examples (between 7 - 79% depending on model and benchmark). We also show through behavioral analysis that, when steering changes the decision, the chain-of-thought process often rationalizes the flip rather than resisting it. Together, these results suggest that reasoning models can encode action choices before they begin to deliberate in text.
Terminal Agents Suffice for Enterprise Automation
Mar 31, 2026There has been growing interest in building agents that can interact with digital platforms to execute meaningful enterprise tasks autonomously. Among the approaches explored are tool-augmented agents built on abstractions such as Model Context Protocol (MCP) and web agents that operate through graphical interfaces. Yet, it remains unclear whether such complex agentic systems are necessary given their cost and operational overhead. We argue that a coding agent equipped only with a terminal and a filesystem can solve many enterprise tasks more effectively by interacting directly with platform APIs. We evaluate this hypothesis across diverse real-world systems and show that these low-level terminal agents match or outperform more complex agent architectures. Our findings suggest that simple programmatic interfaces, combined with strong foundation models, are sufficient for practical enterprise automation.
CUA-Suite: Massive Human-annotated Video Demonstrations for Computer-Use Agents
Mar 25, 2026Computer-use agents (CUAs) hold great promise for automating complex desktop workflows, yet progress toward general-purpose agents is bottlenecked by the scarcity of continuous, high-quality human demonstration videos. Recent work emphasizes that continuous video, not sparse screenshots, is the critical missing ingredient for scaling these agents. However, the largest existing open dataset, ScaleCUA, contains only 2 million screenshots, equating to less than 20 hours of video. To address this bottleneck, we introduce CUA-Suite, a large-scale ecosystem of expert video demonstrations and dense annotations for professional desktop computer-use agents. At its core is VideoCUA, which provides approximately 10,000 human-demonstrated tasks across 87 diverse applications with continuous 30 fps screen recordings, kinematic cursor traces, and multi-layerfed reasoning annotations, totaling approximately 55 hours and 6 million frames of expert video. Unlike sparse datasets that capture only final click coordinates, these continuous video streams preserve the full temporal dynamics of human interaction, forming a superset of information that can be losslessly transformed into the formats required by existing agent frameworks. CUA-Suite further provides two complementary resources: UI-Vision, a rigorous benchmark for evaluating grounding and planning capabilities in CUAs, and GroundCUA, a large-scale grounding dataset with 56K annotated screenshots and over 3.6 million UI element annotations. Preliminary evaluation reveals that current foundation action models struggle substantially with professional desktop applications (~60% task failure rate). Beyond evaluation, CUA-Suite's rich multimodal corpus supports emerging research directions including generalist screen parsing, continuous spatial control, video-based reward modeling, and visual world models. All data and models are publicly released.
EnterpriseOps-Gym: Environments and Evaluations for Stateful Agentic Planning and Tool Use in Enterprise Settings
Mar 13, 2026Large language models are shifting from passive information providers to active agents intended for complex workflows. However, their deployment as reliable AI workers in enterprise is stalled by benchmarks that fail to capture the intricacies of professional environments, specifically, the need for long-horizon planning amidst persistent state changes and strict access protocols. In this work, we introduce EnterpriseOps-Gym, a benchmark designed to evaluate agentic planning in realistic enterprise settings. Specifically, EnterpriseOps-Gym features a containerized sandbox with 164 database tables and 512 functional tools to mimic real-world search friction. Within this environment, agents are evaluated on 1,150 expert-curated tasks across eight mission-critical verticals (including Customer Service, HR, and IT). Our evaluation of 14 frontier models reveals critical limitations in state-of-the-art models: the top-performing Claude Opus 4.5 achieves only 37.4% success. Further analysis shows that providing oracle human plans improves performance by 14-35 percentage points, pinpointing strategic reasoning as the primary bottleneck. Additionally, agents frequently fail to refuse infeasible tasks (best model achieves 53.9%), leading to unintended and potentially harmful side effects. Our findings underscore that current agents are not yet ready for autonomous enterprise deployment. More broadly, EnterpriseOps-Gym provides a concrete testbed to advance the robustness of agentic planning in professional workflows.
Grammar Search for Multi-Agent Systems
Dec 16, 2025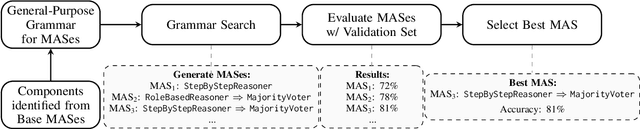
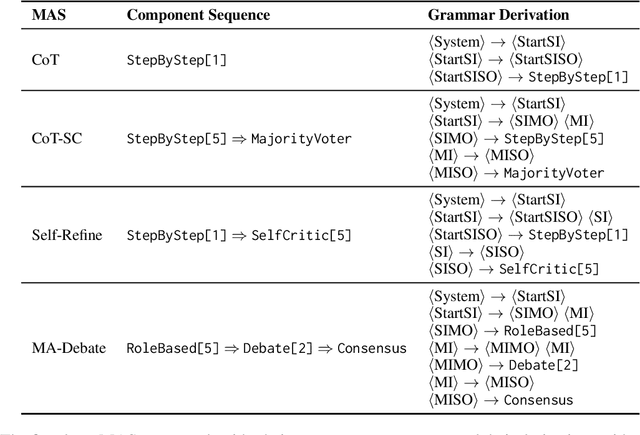

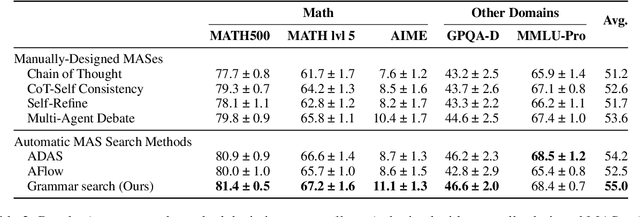
Automatic search for Multi-Agent Systems has recently emerged as a key focus in agentic AI research. Several prior approaches have relied on LLM-based free-form search over the code space. In this work, we propose a more structured framework that explores the same space through a fixed set of simple, composable components. We show that, despite lacking the generative flexibility of LLMs during the candidate generation stage, our method outperforms prior approaches on four out of five benchmarks across two domains: mathematics and question answering. Furthermore, our method offers additional advantages, including a more cost-efficient search process and the generation of modular, interpretable multi-agent systems with simpler logic.
Grounding Computer Use Agents on Human Demonstrations
Nov 10, 2025



Building reliable computer-use agents requires grounding: accurately connecting natural language instructions to the correct on-screen elements. While large datasets exist for web and mobile interactions, high-quality resources for desktop environments are limited. To address this gap, we introduce GroundCUA, a large-scale desktop grounding dataset built from expert human demonstrations. It covers 87 applications across 12 categories and includes 56K screenshots, with every on-screen element carefully annotated for a total of over 3.56M human-verified annotations. From these demonstrations, we generate diverse instructions that capture a wide range of real-world tasks, providing high-quality data for model training. Using GroundCUA, we develop the GroundNext family of models that map instructions to their target UI elements. At both 3B and 7B scales, GroundNext achieves state-of-the-art results across five benchmarks using supervised fine-tuning, while requiring less than one-tenth the training data of prior work. Reinforcement learning post-training further improves performance, and when evaluated in an agentic setting on the OSWorld benchmark using o3 as planner, GroundNext attains comparable or superior results to models trained with substantially more data,. These results demonstrate the critical role of high-quality, expert-driven datasets in advancing general-purpose computer-use agents.
AU-Harness: An Open-Source Toolkit for Holistic Evaluation of Audio LLMs
Sep 11, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce AU-Harness, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. AU-Harness provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.
LALM-Eval: An Open-Source Toolkit for Holistic Evaluation of Large Audio Language Models
Sep 09, 2025Large Audio Language Models (LALMs) are rapidly advancing, but evaluating them remains challenging due to inefficient toolkits that limit fair comparison and systematic assessment. Current frameworks suffer from three critical issues: slow processing that bottlenecks large-scale studies, inconsistent prompting that hurts reproducibility, and narrow task coverage that misses important audio reasoning capabilities. We introduce LALM-Eval, an efficient and comprehensive evaluation framework for LALMs. Our system achieves a speedup of up to 127% over existing toolkits through optimized batch processing and parallel execution, enabling large-scale evaluations previously impractical. We provide standardized prompting protocols and flexible configurations for fair model comparison across diverse scenarios. Additionally, we introduce two new evaluation categories: LLM-Adaptive Diarization for temporal audio understanding and Spoken Language Reasoning for complex audio-based cognitive tasks. Through evaluation across 380+ tasks, we reveal significant gaps in current LALMs, particularly in temporal understanding and complex spoken language reasoning tasks. Our findings also highlight a lack of standardization in instruction modality existent across audio benchmarks, which can lead up performance differences up to 9.5 absolute points on the challenging complex instruction following downstream tasks. LALM-Eval provides both practical evaluation tools and insights into model limitations, advancing systematic LALM development.