 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Object-Centric World Models Meet Policy Learning: From Pixels to Policies, and Where It Breaks
Nov 11, 2025Object-centric world models (OCWM) aim to decompose visual scenes into object-level representations, providing structured abstractions that could improve compositional generalization and data efficiency in reinforcement learning. We hypothesize that explicitly disentangled object-level representations, by localizing task-relevant information, can enhance policy performance across novel feature combinations. To test this hypothesis, we introduce DLPWM, a fully unsupervised, disentangled object-centric world model that learns object-level latents directly from pixels. DLPWM achieves strong reconstruction and prediction performance, including robustness to several out-of-distribution (OOD) visual variations. However, when used for downstream model-based control, policies trained on DLPWM latents underperform compared to DreamerV3. Through latent-trajectory analyses, we identify representation shift during multi-object interactions as a key driver of unstable policy learning. Our results suggest that, although object-centric perception supports robust visual modeling, achieving stable control requires mitigating latent drift.
Representing Positional Information in Generative World Models for Object Manipulation
Sep 19, 2024



Object manipulation capabilities are essential skills that set apart embodied agents engaging with the world, especially in the realm of robotics. The ability to predict outcomes of interactions with objects is paramount in this setting. While model-based control methods have started to be employed for tackling manipulation tasks, they have faced challenges in accurately manipulating objects. As we analyze the causes of this limitation, we identify the cause of underperformance in the way current world models represent crucial positional information, especially about the target's goal specification for object positioning tasks. We introduce a general approach that empowers world model-based agents to effectively solve object-positioning tasks. We propose two declinations of this approach for generative world models: position-conditioned (PCP) and latent-conditioned (LCP) policy learning. In particular, LCP employs object-centric latent representations that explicitly capture object positional information for goal specification. This naturally leads to the emergence of multimodal capabilities, enabling the specification of goals through spatial coordinates or a visual goal. Our methods are rigorously evaluated across several manipulation environments, showing favorable performance compared to current model-based control approaches.
FOCUS: Object-Centric World Models for Robotics Manipulation
Jul 07, 2023



Understanding the world in terms of objects and the possible interplays with them is an important cognition ability, especially in robotics manipulation, where many tasks require robot-object interactions. However, learning such a structured world model, which specifically captures entities and relationships, remains a challenging and underexplored problem. To address this, we propose FOCUS, a model-based agent that learns an object-centric world model. Thanks to a novel exploration bonus that stems from the object-centric representation, FOCUS can be deployed on robotics manipulation tasks to explore object interactions more easily. Evaluating our approach on manipulation tasks across different settings, we show that object-centric world models allow the agent to solve tasks more efficiently and enable consistent exploration of robot-object interactions. Using a Franka Emika robot arm, we also showcase how FOCUS could be adopted in real-world settings.
Symmetry and Complexity in Object-Centric Deep Active Inference Models
Apr 14, 2023



Humans perceive and interact with hundreds of objects every day. In doing so, they need to employ mental models of these objects and often exploit symmetries in the object's shape and appearance in order to learn generalizable and transferable skills. Active inference is a first principles approach to understanding and modeling sentient agents. It states that agents entertain a generative model of their environment, and learn and act by minimizing an upper bound on their surprisal, i.e. their Free Energy. The Free Energy decomposes into an accuracy and complexity term, meaning that agents favor the least complex model, that can accurately explain their sensory observations. In this paper, we investigate how inherent symmetries of particular objects also emerge as symmetries in the latent state space of the generative model learnt under deep active inference. In particular, we focus on object-centric representations, which are trained from pixels to predict novel object views as the agent moves its viewpoint. First, we investigate the relation between model complexity and symmetry exploitation in the state space. Second, we do a principal component analysis to demonstrate how the model encodes the principal axis of symmetry of the object in the latent space. Finally, we also demonstrate how more symmetrical representations can be exploited for better generalization in the context of manipulation.
Object-Centric Scene Representations using Active Inference
Feb 07, 2023Representing a scene and its constituent objects from raw sensory data is a core ability for enabling robots to interact with their environment. In this paper, we propose a novel approach for scene understanding, leveraging a hierarchical object-centric generative model that enables an agent to infer object category and pose in an allocentric reference frame using active inference, a neuro-inspired framework for action and perception. For evaluating the behavior of an active vision agent, we also propose a new benchmark where, given a target viewpoint of a particular object, the agent needs to find the best matching viewpoint given a workspace with randomly positioned objects in 3D. We demonstrate that our active inference agent is able to balance epistemic foraging and goal-driven behavior, and outperforms both supervised and reinforcement learning baselines by a large margin.
Disentangling Shape and Pose for Object-Centric Deep Active Inference Models
Sep 16, 2022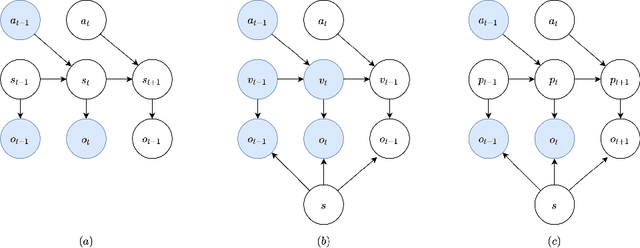
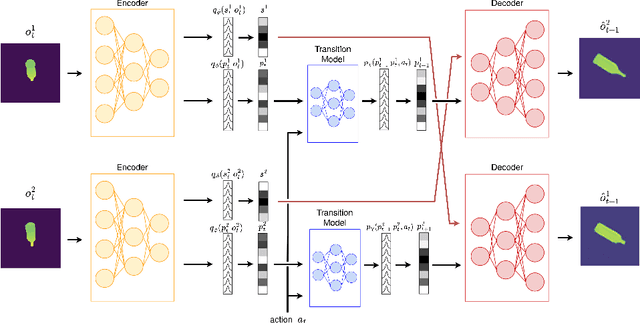

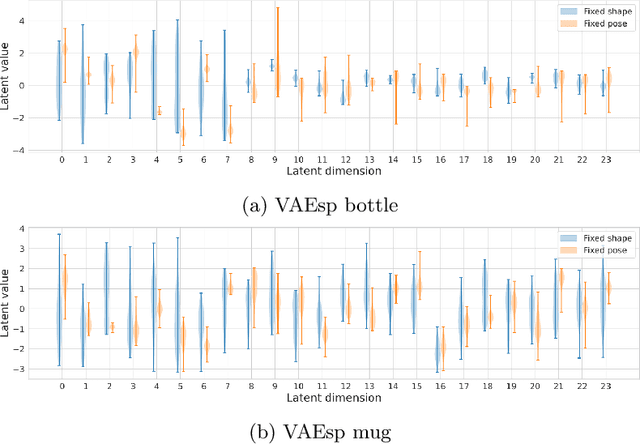
Active inference is a first principles approach for understanding the brain in particular, and sentient agents in general, with the single imperative of minimizing free energy. As such, it provides a computational account for modelling artificial intelligent agents, by defining the agent's generative model and inferring the model parameters, actions and hidden state beliefs. However, the exact specification of the generative model and the hidden state space structure is left to the experimenter, whose design choices influence the resulting behaviour of the agent. Recently, deep learning methods have been proposed to learn a hidden state space structure purely from data, alleviating the experimenter from this tedious design task, but resulting in an entangled, non-interpreteable state space. In this paper, we hypothesize that such a learnt, entangled state space does not necessarily yield the best model in terms of free energy, and that enforcing different factors in the state space can yield a lower model complexity. In particular, we consider the problem of 3D object representation, and focus on different instances of the ShapeNet dataset. We propose a model that factorizes object shape, pose and category, while still learning a representation for each factor using a deep neural network. We show that models, with best disentanglement properties, perform best when adopted by an active agent in reaching preferred observations.