 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive inference and artificial reasoning
Dec 24, 2025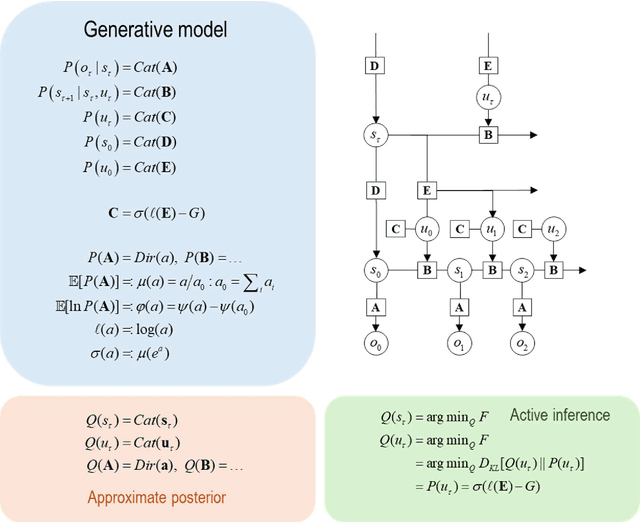
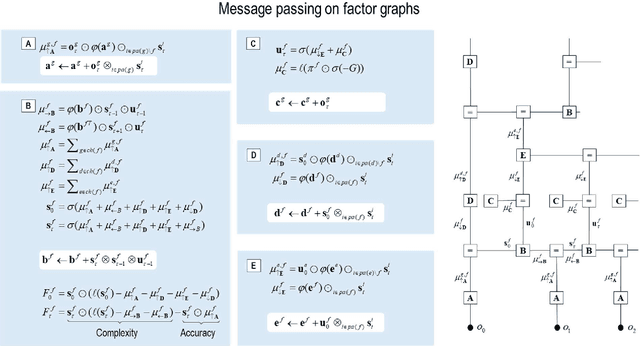
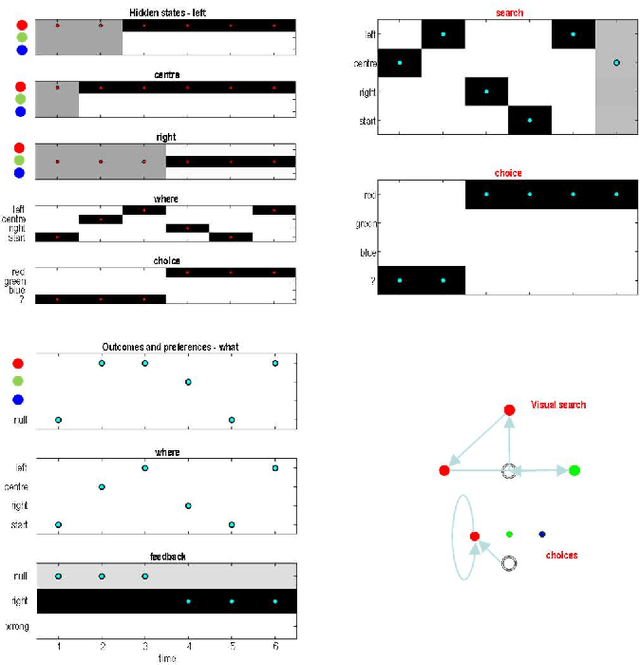
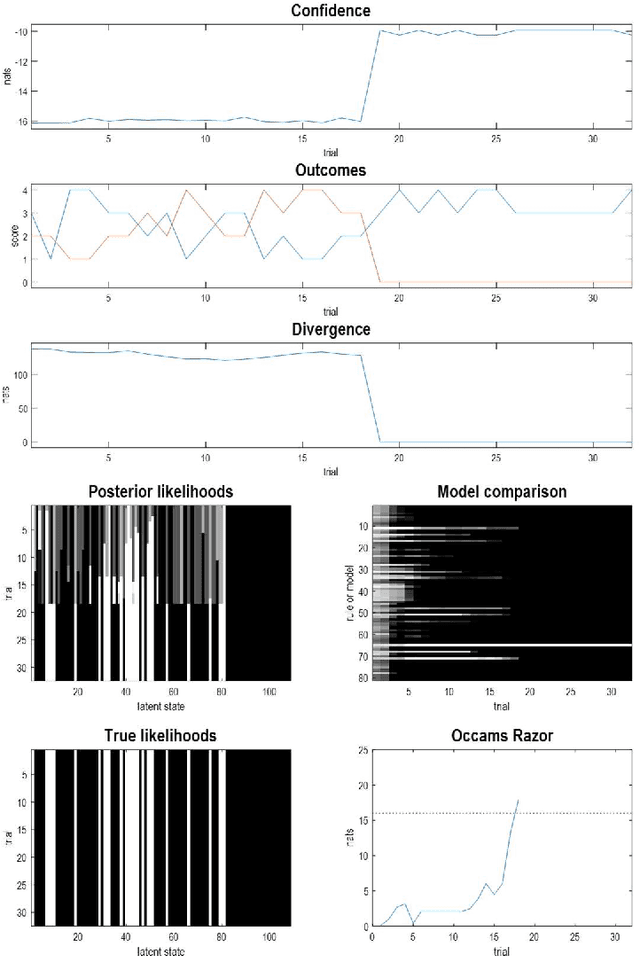
This technical note considers the sampling of outcomes that provide the greatest amount of information about the structure of underlying world models. This generalisation furnishes a principled approach to structure learning under a plausible set of generative models or hypotheses. In active inference, policies - i.e., combinations of actions - are selected based on their expected free energy, which comprises expected information gain and value. Information gain corresponds to the KL divergence between predictive posteriors with, and without, the consequences of action. Posteriors over models can be evaluated quickly and efficiently using Bayesian Model Reduction, based upon accumulated posterior beliefs about model parameters. The ensuing information gain can then be used to select actions that disambiguate among alternative models, in the spirit of optimal experimental design. We illustrate this kind of active selection or reasoning using partially observed discrete models; namely, a 'three-ball' paradigm used previously to describe artificial insight and 'aha moments' via (synthetic) introspection or sleep. We focus on the sample efficiency afforded by seeking outcomes that resolve the greatest uncertainty about the world model, under which outcomes are generated.
Zero-shot Structure Learning and Planning for Autonomous Robot Navigation using Active Inference
Oct 10, 2025Autonomous navigation in unfamiliar environments requires robots to simultaneously explore, localise, and plan under uncertainty, without relying on predefined maps or extensive training. We present a biologically inspired, Active Inference-based framework, Active Inference MAPping and Planning (AIMAPP). This model unifies mapping, localisation, and decision-making within a single generative model. Inspired by hippocampal navigation, it uses topological reasoning, place-cell encoding, and episodic memory to guide behaviour. The agent builds and updates a sparse topological map online, learns state transitions dynamically, and plans actions by minimising Expected Free Energy. This allows it to balance goal-directed and exploratory behaviours. We implemented a ROS-compatible navigation system that is sensor and robot-agnostic, capable of integrating with diverse hardware configurations. It operates in a fully self-supervised manner, is resilient to drift, and supports both exploration and goal-directed navigation without any pre-training. We demonstrate robust performance in large-scale real and simulated environments against state-of-the-art planning models, highlighting the system's adaptability to ambiguous observations, environmental changes, and sensor noise. The model offers a biologically inspired, modular solution to scalable, self-supervised navigation in unstructured settings. AIMAPP is available at https://github.com/decide-ugent/AIMAPP.
Bio-Inspired Topological Autonomous Navigation with Active Inference in Robotics
Aug 10, 2025Achieving fully autonomous exploration and navigation remains a critical challenge in robotics, requiring integrated solutions for localisation, mapping, decision-making and motion planning. Existing approaches either rely on strict navigation rules lacking adaptability or on pre-training, which requires large datasets. These AI methods are often computationally intensive or based on static assumptions, limiting their adaptability in dynamic or unknown environments. This paper introduces a bio-inspired agent based on the Active Inference Framework (AIF), which unifies mapping, localisation, and adaptive decision-making for autonomous navigation, including exploration and goal-reaching. Our model creates and updates a topological map of the environment in real-time, planning goal-directed trajectories to explore or reach objectives without requiring pre-training. Key contributions include a probabilistic reasoning framework for interpretable navigation, robust adaptability to dynamic changes, and a modular ROS2 architecture compatible with existing navigation systems. Our method was tested in simulated and real-world environments. The agent successfully explores large-scale simulated environments and adapts to dynamic obstacles and drift, proving to be comparable to other exploration strategies such as Gbplanner, FAEL and Frontiers. This approach offers a scalable and transparent approach for navigating complex, unstructured environments.
Navigation and Exploration with Active Inference: from Biology to Industry
Aug 10, 2025By building and updating internal cognitive maps, animals exhibit extraordinary navigation abilities in complex, dynamic environments. Inspired by these biological mechanisms, we present a real time robotic navigation system grounded in the Active Inference Framework (AIF). Our model incrementally constructs a topological map, infers the agent's location, and plans actions by minimising expected uncertainty and fulfilling perceptual goals without any prior training. Integrated into the ROS2 ecosystem, we validate its adaptability and efficiency across both 2D and 3D environments (simulated and real world), demonstrating competitive performance with traditional and state of the art exploration approaches while offering a biologically inspired navigation approach.
Mobile Manipulation with Active Inference for Long-Horizon Rearrangement Tasks
Jul 23, 2025Despite growing interest in active inference for robotic control, its application to complex, long-horizon tasks remains untested. We address this gap by introducing a fully hierarchical active inference architecture for goal-directed behavior in realistic robotic settings. Our model combines a high-level active inference model that selects among discrete skills realized via a whole-body active inference controller. This unified approach enables flexible skill composition, online adaptability, and recovery from task failures without requiring offline training. Evaluated on the Habitat Benchmark for mobile manipulation, our method outperforms state-of-the-art baselines across the three long-horizon tasks, demonstrating for the first time that active inference can scale to the complexity of modern robotics benchmarks.
AXIOM: Learning to Play Games in Minutes with Expanding Object-Centric Models
May 30, 2025Current deep reinforcement learning (DRL) approaches achieve state-of-the-art performance in various domains, but struggle with data efficiency compared to human learning, which leverages core priors about objects and their interactions. Active inference offers a principled framework for integrating sensory information with prior knowledge to learn a world model and quantify the uncertainty of its own beliefs and predictions. However, active inference models are usually crafted for a single task with bespoke knowledge, so they lack the domain flexibility typical of DRL approaches. To bridge this gap, we propose a novel architecture that integrates a minimal yet expressive set of core priors about object-centric dynamics and interactions to accelerate learning in low-data regimes. The resulting approach, which we call AXIOM, combines the usual data efficiency and interpretability of Bayesian approaches with the across-task generalization usually associated with DRL. AXIOM represents scenes as compositions of objects, whose dynamics are modeled as piecewise linear trajectories that capture sparse object-object interactions. The structure of the generative model is expanded online by growing and learning mixture models from single events and periodically refined through Bayesian model reduction to induce generalization. AXIOM masters various games within only 10,000 interaction steps, with both a small number of parameters compared to DRL, and without the computational expense of gradient-based optimization.
Towards smart and adaptive agents for active sensing on edge devices
Jan 09, 2025TinyML has made deploying deep learning models on low-power edge devices feasible, creating new opportunities for real-time perception in constrained environments. However, the adaptability of such deep learning methods remains limited to data drift adaptation, lacking broader capabilities that account for the environment's underlying dynamics and inherent uncertainty. Deep learning's scaling laws, which counterbalance this limitation by massively up-scaling data and model size, cannot be applied when deploying on the Edge, where deep learning limitations are further amplified as models are scaled down for deployment on resource-constrained devices. This paper presents a smart agentic system capable of performing on-device perception and planning, enabling active sensing on the edge. By incorporating active inference into our solution, our approach extends beyond deep learning capabilities, allowing the system to plan in dynamic environments while operating in real time with a modest total model size of 2.3 MB. We showcase our proposed system by creating and deploying a saccade agent connected to an IoT camera with pan and tilt capabilities on an NVIDIA Jetson embedded device. The saccade agent controls the camera's field of view following optimal policies derived from the active inference principles, simulating human-like saccadic motion for surveillance and robotics applications.
Learning Dynamic Cognitive Map with Autonomous Navigation
Nov 13, 2024Inspired by animal navigation strategies, we introduce a novel computational model to navigate and map a space rooted in biologically inspired principles. Animals exhibit extraordinary navigation prowess, harnessing memory, imagination, and strategic decision-making to traverse complex and aliased environments adeptly. Our model aims to replicate these capabilities by incorporating a dynamically expanding cognitive map over predicted poses within an Active Inference framework, enhancing our agent's generative model plasticity to novelty and environmental changes. Through structure learning and active inference navigation, our model demonstrates efficient exploration and exploitation, dynamically expanding its model capacity in response to anticipated novel un-visited locations and updating the map given new evidence contradicting previous beliefs. Comparative analyses in mini-grid environments with the Clone-Structured Cognitive Graph model (CSCG), which shares similar objectives, highlight our model's ability to rapidly learn environmental structures within a single episode, with minimal navigation overlap. Our model achieves this without prior knowledge of observation and world dimensions, underscoring its robustness and efficacy in navigating intricate environments.
Variational Bayes Gaussian Splatting
Oct 04, 2024



Recently, 3D Gaussian Splatting has emerged as a promising approach for modeling 3D scenes using mixtures of Gaussians. The predominant optimization method for these models relies on backpropagating gradients through a differentiable rendering pipeline, which struggles with catastrophic forgetting when dealing with continuous streams of data. To address this limitation, we propose Variational Bayes Gaussian Splatting (VBGS), a novel approach that frames training a Gaussian splat as variational inference over model parameters. By leveraging the conjugacy properties of multivariate Gaussians, we derive a closed-form variational update rule, allowing efficient updates from partial, sequential observations without the need for replay buffers. Our experiments show that VBGS not only matches state-of-the-art performance on static datasets, but also enables continual learning from sequentially streamed 2D and 3D data, drastically improving performance in this setting.
Representing Positional Information in Generative World Models for Object Manipulation
Sep 19, 2024



Object manipulation capabilities are essential skills that set apart embodied agents engaging with the world, especially in the realm of robotics. The ability to predict outcomes of interactions with objects is paramount in this setting. While model-based control methods have started to be employed for tackling manipulation tasks, they have faced challenges in accurately manipulating objects. As we analyze the causes of this limitation, we identify the cause of underperformance in the way current world models represent crucial positional information, especially about the target's goal specification for object positioning tasks. We introduce a general approach that empowers world model-based agents to effectively solve object-positioning tasks. We propose two declinations of this approach for generative world models: position-conditioned (PCP) and latent-conditioned (LCP) policy learning. In particular, LCP employs object-centric latent representations that explicitly capture object positional information for goal specification. This naturally leads to the emergence of multimodal capabilities, enabling the specification of goals through spatial coordinates or a visual goal. Our methods are rigorously evaluated across several manipulation environments, showing favorable performance compared to current model-based control approaches.