 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Generalised Predictive Coding
May 04, 2026This paper introduces an extension of generalised filtering for online applications. Generalised filtering refers to data assimilation schemes that jointly infer latent states, learn unknown model parameters, and estimate uncertainty in an integrated framework -- e.g., estimate state and observation noise -- at the same time (i.e., triple estimation). This framework appears across disciplines under different names, including variational Kalman-Bucy filtering in engineering, generalised predictive coding in neuroscience, and Dynamic Expectation Maximisation (DEM) in time-series analysis. Here, we specialise DEM for ``online'' data assimilation, through a separation of temporal scales. We describe the variational principles and procedures that allow one to assimilate data in a way that allows for a slow updating of parameters and precisions, which contextualise fast Bayesian belief updating about the dynamic hidden states. Using numerical studies, we demonstrate the validity of online DEM (ODEM) using a non-linear -- and potentially chaotic -- generative model, to show that the ODEM scheme can track the latent states of the generative process, even when its functional form differs fundamentally from the dynamics of the generative model. Framed from a neuro-mimetic predictive coding perspective, ODEM offers a biologically inspired solution to online inference, learning, and uncertainty estimation in dynamic environments.
Active Inference: A method for Phenotyping Agency in AI systems?
Apr 25, 2026The proliferation of agentic artificial intelligence has outpaced the conceptual tools needed to characterize agency in computational systems. Prevailing definitions mainly rely on autonomy and goal-directedness. Here, we argue for a minimal notion open to principled inspection given three criteria: intentionality as action grounded in beliefs and desires, rationality as normatively coherent action entailed by a world model, and explainability as action causally traceable to internal states; we subsequently instantiate these as a partially observable Markov decision process under a variational framework wherein posterior beliefs, prior preferences, and the minimization of expected free energy jointly constitute an agentic action chain. Using a canonical T-maze paradigm, we evidence how empowerment, formulated as the channel capacity between actions and anticipated observations, serves as an operational metric that distinguishes zero-, intermediate-, and high-agency phenotypes through structural manipulations of the generative model. We conclude by arguing that as agents engage in epistemic foraging to resolve ambiguity, the governance controls that remain effective must shift systematically from external constraints to the internal modulation of prior preferences, offering a principled, variational bridge from computational phenotyping to AI governance strategy
Active inference and artificial reasoning
Dec 24, 2025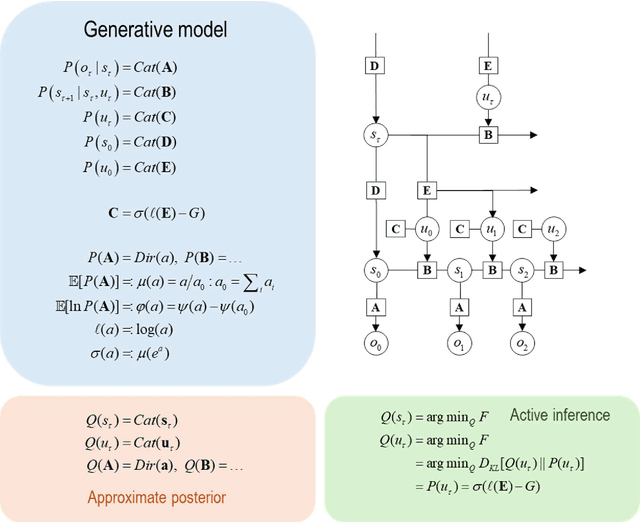
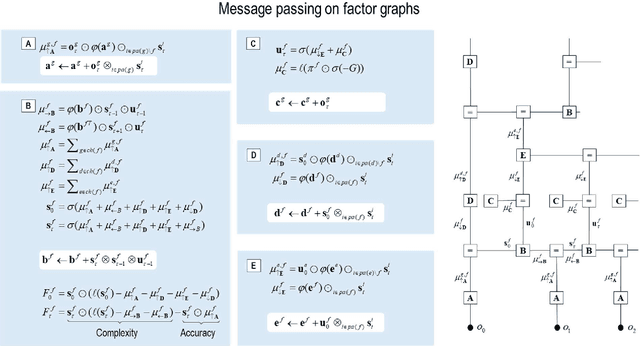
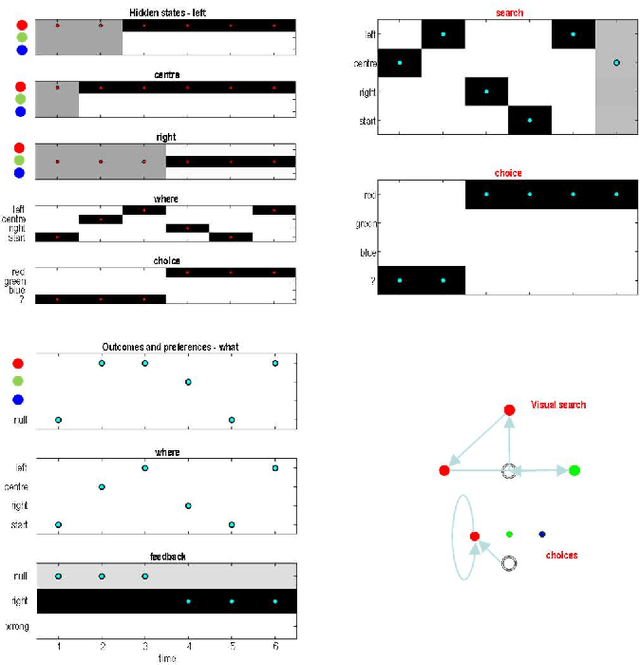
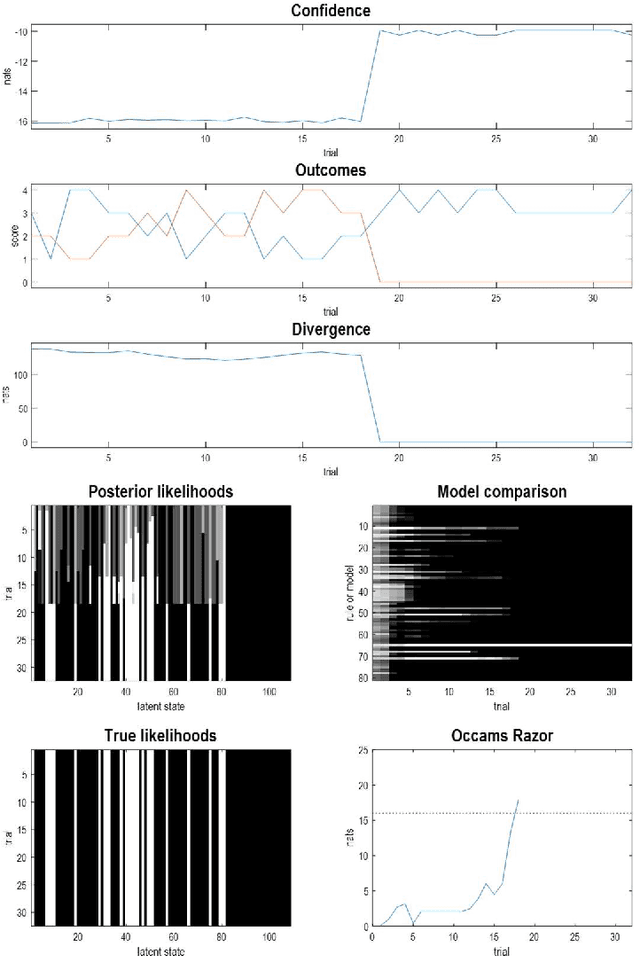
This technical note considers the sampling of outcomes that provide the greatest amount of information about the structure of underlying world models. This generalisation furnishes a principled approach to structure learning under a plausible set of generative models or hypotheses. In active inference, policies - i.e., combinations of actions - are selected based on their expected free energy, which comprises expected information gain and value. Information gain corresponds to the KL divergence between predictive posteriors with, and without, the consequences of action. Posteriors over models can be evaluated quickly and efficiently using Bayesian Model Reduction, based upon accumulated posterior beliefs about model parameters. The ensuing information gain can then be used to select actions that disambiguate among alternative models, in the spirit of optimal experimental design. We illustrate this kind of active selection or reasoning using partially observed discrete models; namely, a 'three-ball' paradigm used previously to describe artificial insight and 'aha moments' via (synthetic) introspection or sleep. We focus on the sample efficiency afforded by seeking outcomes that resolve the greatest uncertainty about the world model, under which outcomes are generated.
EcoNet: Multiagent Planning and Control Of Household Energy Resources Using Active Inference
Dec 14, 2025Advances in automated systems afford new opportunities for intelligent management of energy at household, local area, and utility scales. Home Energy Management Systems (HEMS) can play a role by optimizing the schedule and use of household energy devices and resources. One challenge is that the goals of a household can be complex and conflicting. For example, a household might wish to reduce energy costs and grid-associated greenhouse gas emissions, yet keep room temperatures comfortable. Another challenge is that an intelligent HEMS agent must make decisions under uncertainty. An agent must plan actions into the future, but weather and solar generation forecasts, for example, provide inherently uncertain estimates of future conditions. This paper introduces EcoNet, a Bayesian approach to household and neighborhood energy management that is based on active inference. The aim is to improve energy management and coordination, while accommodating uncertainties and taking into account potentially conditional and conflicting goals and preferences. Simulation results are presented and discussed.
AXIOM: Learning to Play Games in Minutes with Expanding Object-Centric Models
May 30, 2025Current deep reinforcement learning (DRL) approaches achieve state-of-the-art performance in various domains, but struggle with data efficiency compared to human learning, which leverages core priors about objects and their interactions. Active inference offers a principled framework for integrating sensory information with prior knowledge to learn a world model and quantify the uncertainty of its own beliefs and predictions. However, active inference models are usually crafted for a single task with bespoke knowledge, so they lack the domain flexibility typical of DRL approaches. To bridge this gap, we propose a novel architecture that integrates a minimal yet expressive set of core priors about object-centric dynamics and interactions to accelerate learning in low-data regimes. The resulting approach, which we call AXIOM, combines the usual data efficiency and interpretability of Bayesian approaches with the across-task generalization usually associated with DRL. AXIOM represents scenes as compositions of objects, whose dynamics are modeled as piecewise linear trajectories that capture sparse object-object interactions. The structure of the generative model is expanded online by growing and learning mixture models from single events and periodically refined through Bayesian model reduction to induce generalization. AXIOM masters various games within only 10,000 interaction steps, with both a small number of parameters compared to DRL, and without the computational expense of gradient-based optimization.
Self-orthogonalizing attractor neural networks emerging from the free energy principle
May 28, 2025Attractor dynamics are a hallmark of many complex systems, including the brain. Understanding how such self-organizing dynamics emerge from first principles is crucial for advancing our understanding of neuronal computations and the design of artificial intelligence systems. Here we formalize how attractor networks emerge from the free energy principle applied to a universal partitioning of random dynamical systems. Our approach obviates the need for explicitly imposed learning and inference rules and identifies emergent, but efficient and biologically plausible inference and learning dynamics for such self-organizing systems. These result in a collective, multi-level Bayesian active inference process. Attractors on the free energy landscape encode prior beliefs; inference integrates sensory data into posterior beliefs; and learning fine-tunes couplings to minimize long-term surprise. Analytically and via simulations, we establish that the proposed networks favor approximately orthogonalized attractor representations, a consequence of simultaneously optimizing predictive accuracy and model complexity. These attractors efficiently span the input subspace, enhancing generalization and the mutual information between hidden causes and observable effects. Furthermore, while random data presentation leads to symmetric and sparse couplings, sequential data fosters asymmetric couplings and non-equilibrium steady-state dynamics, offering a natural extension to conventional Boltzmann Machines. Our findings offer a unifying theory of self-organizing attractor networks, providing novel insights for AI and neuroscience.
Robust Decision-Making Via Free Energy Minimization
Mar 17, 2025Despite their groundbreaking performance, state-of-the-art autonomous agents can misbehave when training and environmental conditions become inconsistent, with minor mismatches leading to undesirable behaviors or even catastrophic failures. Robustness towards these training/environment ambiguities is a core requirement for intelligent agents and its fulfillment is a long-standing challenge when deploying agents in the real world. Here, departing from mainstream views seeking robustness through training, we introduce DR-FREE, a free energy model that installs this core property by design. It directly wires robustness into the agent decision-making mechanisms via free energy minimization. By combining a robust extension of the free energy principle with a novel resolution engine, DR-FREE returns a policy that is optimal-yet-robust against ambiguity. Moreover, for the first time, it reveals the mechanistic role of ambiguity on optimal decisions and requisite Bayesian belief updating. We evaluate DR-FREE on an experimental testbed involving real rovers navigating an ambiguous environment filled with obstacles. Across all the experiments, DR-FREE enables robots to successfully navigate towards their goal even when, in contrast, standard free energy minimizing agents that do not use DR-FREE fail. In short, DR-FREE can tackle scenarios that elude previous methods: this milestone may inspire both deployment in multi-agent settings and, at a perhaps deeper level, the quest for a biologically plausible explanation of how natural agents - with little or no training - survive in capricious environments.
Brain in the Dark: Design Principles for Neuromimetic Inference under the Free Energy Principle
Feb 13, 2025Deep learning has revolutionised artificial intelligence (AI) by enabling automatic feature extraction and function approximation from raw data. However, it faces challenges such as a lack of out-of-distribution generalisation, catastrophic forgetting and poor interpretability. In contrast, biological neural networks, such as those in the human brain, do not suffer from these issues, inspiring AI researchers to explore neuromimetic deep learning, which aims to replicate brain mechanisms within AI models. A foundational theory for this approach is the Free Energy Principle (FEP), which despite its potential, is often considered too complex to understand and implement in AI as it requires an interdisciplinary understanding across a variety of fields. This paper seeks to demystify the FEP and provide a comprehensive framework for designing neuromimetic models with human-like perception capabilities. We present a roadmap for implementing these models and a Pytorch code repository for applying FEP in a predictive coding network.
From pixels to planning: scale-free active inference
Jul 27, 2024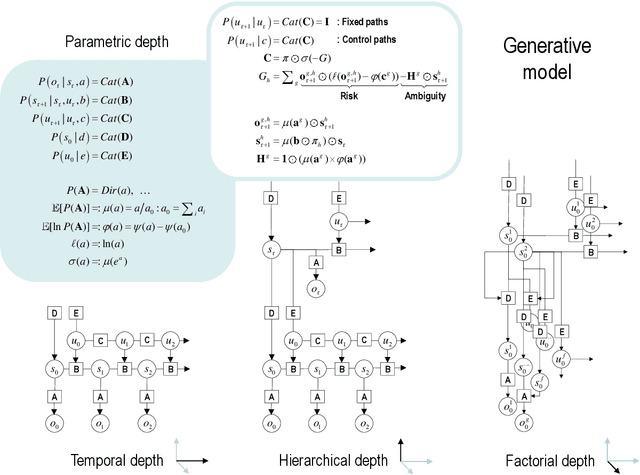
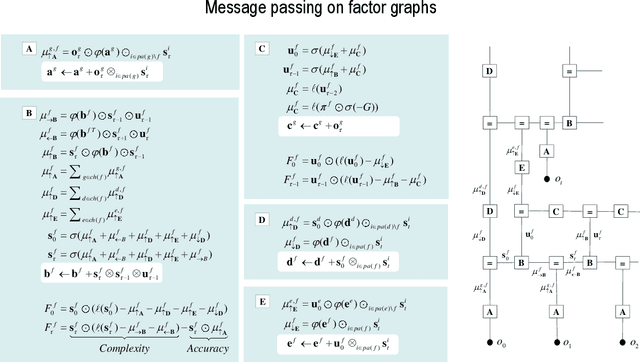
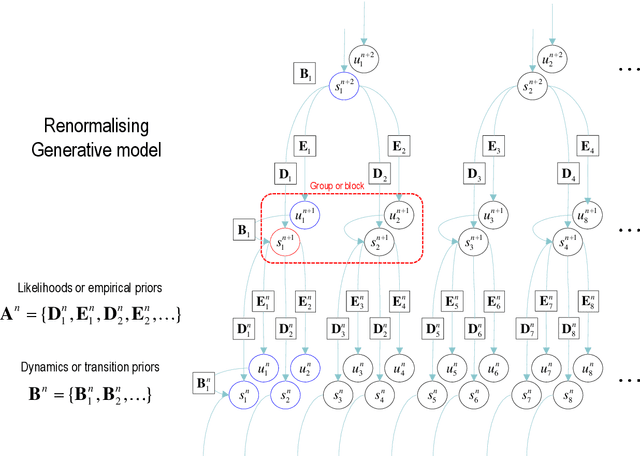
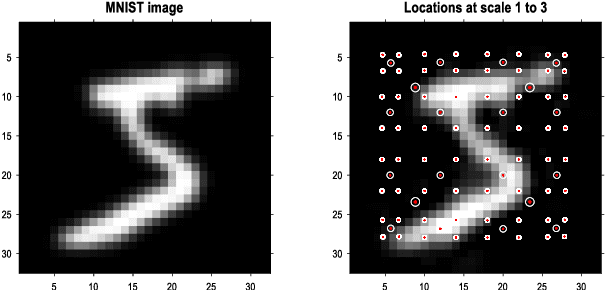
This paper describes a discrete state-space model -- and accompanying methods -- for generative modelling. This model generalises partially observed Markov decision processes to include paths as latent variables, rendering it suitable for active inference and learning in a dynamic setting. Specifically, we consider deep or hierarchical forms using the renormalisation group. The ensuing renormalising generative models (RGM) can be regarded as discrete homologues of deep convolutional neural networks or continuous state-space models in generalised coordinates of motion. By construction, these scale-invariant models can be used to learn compositionality over space and time, furnishing models of paths or orbits; i.e., events of increasing temporal depth and itinerancy. This technical note illustrates the automatic discovery, learning and deployment of RGMs using a series of applications. We start with image classification and then consider the compression and generation of movies and music. Finally, we apply the same variational principles to the learning of Atari-like games.
Localising the Seizure Onset Zone from Single-Pulse Electrical Stimulation Responses with a Transformer
Mar 29, 2024Epilepsy is one of the most common neurological disorders, and many patients require surgical intervention when medication fails to control seizures. For effective surgical outcomes, precise localisation of the epileptogenic focus - often approximated through the Seizure Onset Zone (SOZ) - is critical yet remains a challenge. Active probing through electrical stimulation is already standard clinical practice for identifying epileptogenic areas. This paper advances the application of deep learning for SOZ localisation using Single Pulse Electrical Stimulation (SPES) responses. We achieve this by introducing Transformer models that incorporate cross-channel attention. We evaluate these models on held-out patient test sets to assess their generalisability to unseen patients and electrode placements. Our study makes three key contributions: Firstly, we implement an existing deep learning model to compare two SPES analysis paradigms - namely, divergent and convergent. These paradigms evaluate outward and inward effective connections, respectively. Our findings reveal a notable improvement in moving from a divergent (AUROC: 0.574) to a convergent approach (AUROC: 0.666), marking the first application of the latter in this context. Secondly, we demonstrate the efficacy of the Transformer models in handling heterogeneous electrode placements, increasing the AUROC to 0.730. Lastly, by incorporating inter-trial variability, we further refine the Transformer models, with an AUROC of 0.745, yielding more consistent predictions across patients. These advancements provide a deeper insight into SOZ localisation and represent a significant step in modelling patient-specific intracranial EEG electrode placements in SPES. Future work will explore integrating these models into clinical decision-making processes to bridge the gap between deep learning research and practical healthcare applications.