 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity Matching Networks: Hebbian Learning and Convergence Over Multiple Time Scales
Jun 06, 2025A recent breakthrough in biologically-plausible normative frameworks for dimensionality reduction is based upon the similarity matching cost function and the low-rank matrix approximation problem. Despite clear biological interpretation, successful application in several domains, and experimental validation, a formal complete convergence analysis remains elusive. Building on this framework, we consider and analyze a continuous-time neural network, the \emph{similarity matching network}, for principal subspace projection. Derived from a min-max-min objective, this biologically-plausible network consists of three coupled dynamics evolving at different time scales: neural dynamics, lateral synaptic dynamics, and feedforward synaptic dynamics at the fast, intermediate, and slow time scales, respectively. The feedforward and lateral synaptic dynamics consist of Hebbian and anti-Hebbian learning rules, respectively. By leveraging a multilevel optimization framework, we prove convergence of the dynamics in the offline setting. Specifically, at the first level (fast time scale), we show strong convexity of the cost function and global exponential convergence of the corresponding gradient-flow dynamics. At the second level (intermediate time scale), we prove strong concavity of the cost function and exponential convergence of the corresponding gradient-flow dynamics within the space of positive definite matrices. At the third and final level (slow time scale), we study a non-convex and non-smooth cost function, provide explicit expressions for its global minima, and prove almost sure convergence of the corresponding gradient-flow dynamics to the global minima. These results rely on two empirically motivated conjectures that are supported by thorough numerical experiments. Finally, we validate the effectiveness of our approach via a numerical example.
Haptic bilateral teleoperation system for free-hand dental procedures
Mar 27, 2025Free-hand dental procedures are typically repetitive, time-consuming and require high precision and manual dexterity. Dental robots can play a key role in improving procedural accuracy and safety, enhancing patient comfort, and reducing operator workload. However, robotic solutions for free-hand procedures remain limited or completely lacking, and their acceptance is still low. To address this gap, we develop a haptic bilateral teleoperation system (HBTS) for free-hand dental procedures. The system includes a dedicated mechanical end-effector, compatible with standard clinical tools, and equipped with an endoscopic camera for improved visibility of the intervention site. By ensuring motion and force correspondence between the operator's actions and the robot's movements, monitored through visual feedback, we enhance the operator's sensory awareness and motor accuracy. Furthermore, recognizing the need to ensure procedural safety, we limit interaction forces by scaling the motion references provided to the admittance controller based solely on measured contact forces. This ensures effective force limitation in all contact states without requiring prior knowledge of the environment. The proposed HBTS is validated in a dental scaling procedure using a dental phantom. The results show that the system improves the naturalness, safety, and accuracy of teleoperation, highlighting its potential to enhance free-hand dental procedures.
DR-PETS: Learning-Based Control With Planning in Adversarial Environments
Mar 27, 2025Ensuring robustness against epistemic, possibly adversarial, perturbations is essential for reliable real-world decision-making. While the Probabilistic Ensembles with Trajectory Sampling (PETS) algorithm inherently handles uncertainty via ensemble-based probabilistic models, it lacks guarantees against structured adversarial or worst-case uncertainty distributions. To address this, we propose DR-PETS, a distributionally robust extension of PETS that certifies robustness against adversarial perturbations. We formalize uncertainty via a p-Wasserstein ambiguity set, enabling worst-case-aware planning through a min-max optimization framework. While PETS passively accounts for stochasticity, DR-PETS actively optimizes robustness via a tractable convex approximation integrated into PETS planning loop. Experiments on pendulum stabilization and cart-pole balancing show that DR-PETS certifies robustness against adversarial parameter perturbations, achieving consistent performance in worst-case scenarios where PETS deteriorates.
Robust Decision-Making Via Free Energy Minimization
Mar 17, 2025Despite their groundbreaking performance, state-of-the-art autonomous agents can misbehave when training and environmental conditions become inconsistent, with minor mismatches leading to undesirable behaviors or even catastrophic failures. Robustness towards these training/environment ambiguities is a core requirement for intelligent agents and its fulfillment is a long-standing challenge when deploying agents in the real world. Here, departing from mainstream views seeking robustness through training, we introduce DR-FREE, a free energy model that installs this core property by design. It directly wires robustness into the agent decision-making mechanisms via free energy minimization. By combining a robust extension of the free energy principle with a novel resolution engine, DR-FREE returns a policy that is optimal-yet-robust against ambiguity. Moreover, for the first time, it reveals the mechanistic role of ambiguity on optimal decisions and requisite Bayesian belief updating. We evaluate DR-FREE on an experimental testbed involving real rovers navigating an ambiguous environment filled with obstacles. Across all the experiments, DR-FREE enables robots to successfully navigate towards their goal even when, in contrast, standard free energy minimizing agents that do not use DR-FREE fail. In short, DR-FREE can tackle scenarios that elude previous methods: this milestone may inspire both deployment in multi-agent settings and, at a perhaps deeper level, the quest for a biologically plausible explanation of how natural agents - with little or no training - survive in capricious environments.
Neo-FREE: Policy Composition Through Thousand Brains And Free Energy Optimization
Dec 10, 2024

We consider the problem of optimally composing a set of primitives to tackle control tasks. To address this problem, we introduce Neo-FREE: a control architecture inspired by the Thousand Brains Theory and Free Energy Principle from cognitive sciences. In accordance with the neocortical (Neo) processes postulated by the Thousand Brains Theory, Neo-FREE consists of functional units returning control primitives. These are linearly combined by a gating mechanism that minimizes the variational free energy (FREE). The problem of finding the optimal primitives' weights is then recast as a finite-horizon optimal control problem, which is convex even when the cost is not and the environment is nonlinear, stochastic, non-stationary. The results yield an algorithm for primitives composition and the effectiveness of Neo-FREE is illustrated via in-silico and hardware experiments on an application involving robot navigation in an environment with obstacles.
Safe haptic teleoperations of admittance controlled robots with virtualization of the force feedback
Apr 11, 2024

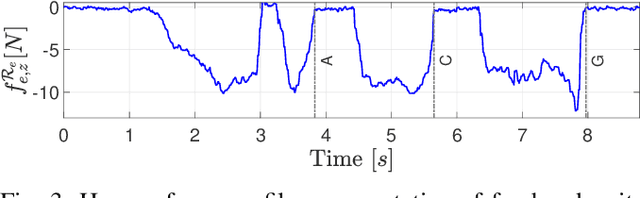

Haptic teleoperations play a key role in extending human capabilities to perform complex tasks remotely, employing a robotic system. The impact of haptics is far-reaching and can improve the sensory awareness and motor accuracy of the operator. In this context, a key challenge is attaining a natural, stable and safe haptic human-robot interaction. Achieving these conflicting requirements is particularly crucial for complex procedures, e.g. medical ones. To address this challenge, in this work we develop a novel haptic bilateral teleoperation system (HBTS), featuring a virtualized force feedback, based on the motion error generated by an admittance controlled robot. This approach allows decoupling the force rendering system from the control of the interaction: the rendered force is assigned with the desired dynamics, while the admittance control parameters are separately tuned to maximize interaction performance. Furthermore, recognizing the necessity to limit the forces exerted by the robot on the environment, to ensure a safe interaction, we embed a saturation strategy of the motion references provided by the haptic device to admittance control. We validate the different aspects of the proposed HBTS, through a teleoperated blackboard writing experiment, against two other architectures. The results indicate that the proposed HBTS improves the naturalness of teleoperation, as well as safety and accuracy of the interaction.
In vivo learning-based control of microbial populations density in bioreactors
Dec 15, 2023



A key problem toward the use of microorganisms as bio-factories is reaching and maintaining cellular communities at a desired density and composition so that they can efficiently convert their biomass into useful compounds. Promising technological platforms for the real time, scalable control of cellular density are bioreactors. In this work, we developed a learning-based strategy to expand the toolbox of available control algorithms capable of regulating the density of a \textit{single} bacterial population in bioreactors. Specifically, we used a sim-to-real paradigm, where a simple mathematical model, calibrated using a few data, was adopted to generate synthetic data for the training of the controller. The resulting policy was then exhaustively tested in vivo using a low-cost bioreactor known as Chi.Bio, assessing performance and robustness. In addition, we compared the performance with more traditional controllers (namely, a PI and an MPC), confirming that the learning-based controller exhibits similar performance in vivo. Our work showcases the viability of learning-based strategies for the control of cellular density in bioreactors, making a step forward toward their use for the control of the composition of microbial consortia.
Guaranteeing Control Requirements via Reward Shaping in Reinforcement Learning
Nov 16, 2023



In addressing control problems such as regulation and tracking through reinforcement learning, it is often required to guarantee that the acquired policy meets essential performance and stability criteria such as a desired settling time and steady-state error prior to deployment. Motivated by this necessity, we present a set of results and a systematic reward shaping procedure that (i) ensures the optimal policy generates trajectories that align with specified control requirements and (ii) allows to assess whether any given policy satisfies them. We validate our approach through comprehensive numerical experiments conducted in two representative environments from OpenAI Gym: the Inverted Pendulum swing-up problem and the Lunar Lander. Utilizing both tabular and deep reinforcement learning methods, our experiments consistently affirm the efficacy of our proposed framework, highlighting its effectiveness in ensuring policy adherence to the prescribed control requirements.
On Convex Data-Driven Inverse Optimal Control for Nonlinear, Non-stationary and Stochastic Systems
Jun 24, 2023


This paper is concerned with a finite-horizon inverse control problem, which has the goal of inferring, from observations, the possibly non-convex and non-stationary cost driving the actions of an agent. In this context, we present a result that enables cost estimation by solving an optimization problem that is convex even when the agent cost is not and when the underlying dynamics is nonlinear, non-stationary and stochastic. To obtain this result, we also study a finite-horizon forward control problem that has randomized policies as decision variables. For this problem, we give an explicit expression for the optimal solution. Moreover, we turn our findings into algorithmic procedures and we show the effectiveness of our approach via both in-silico and experimental validations with real hardware. All the experiments confirm the effectiveness of our approach.
Contracting Dynamics for Time-Varying Convex Optimization
May 24, 2023


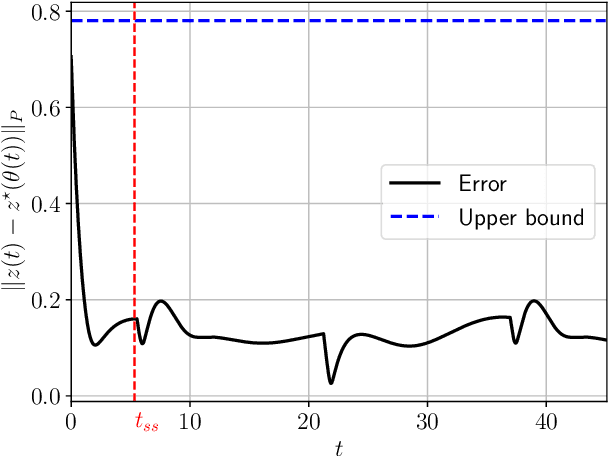
In this article, we provide a novel and broadly-applicable contraction-theoretic approach to continuous-time time-varying convex optimization. For any parameter-dependent contracting dynamics, we show that the tracking error between any solution trajectory and the equilibrium trajectory is uniformly upper bounded in terms of the contraction rate, the Lipschitz constant in which the parameter appears, and the rate of change of the parameter. To apply this result to time-varying convex optimization problems, we establish the strong infinitesimal contraction of dynamics solving three canonical problems, namely monotone inclusions, linear equality-constrained problems, and composite minimization problems. For each of these problems, we prove the sharpest-known rates of contraction and provide explicit tracking error bounds between solution trajectories and minimizing trajectories. We validate our theoretical results on two numerical examples.