 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenTract: Generative Global Tractography
Nov 17, 2025Tractography is the process of inferring the trajectories of white-matter pathways in the brain from diffusion magnetic resonance imaging (dMRI). Local tractography methods, which construct streamlines by following local fiber orientation estimates stepwise through an image, are prone to error accumulation and high false positive rates, particularly on noisy or low-resolution data. In contrast, global methods, which attempt to optimize a collection of streamlines to maximize compatibility with underlying fiber orientation estimates, are computationally expensive. To address these challenges, we introduce GenTract, the first generative model for global tractography. We frame tractography as a generative task, learning a direct mapping from dMRI to complete, anatomically plausible streamlines. We compare both diffusion-based and flow matching paradigms and evaluate GenTract's performance against state-of-the-art baselines. Notably, GenTract achieves precision 2.1x higher than the next-best method, TractOracle. This advantage becomes even more pronounced in challenging low-resolution and noisy settings, where it outperforms the closest competitor by an order of magnitude. By producing tractograms with high precision on research-grade data while also maintaining reliability on imperfect, lower-resolution data, GenTract represents a promising solution for global tractography.
Reward Model Overoptimisation in Iterated RLHF
May 23, 2025Reinforcement learning from human feedback (RLHF) is a widely used method for aligning large language models with human preferences. However, RLHF often suffers from reward model overoptimisation, in which models overfit to the reward function, resulting in non-generalisable policies that exploit the idiosyncrasies and peculiarities of the reward function. A common mitigation is iterated RLHF, in which reward models are repeatedly retrained with updated human feedback and policies are re-optimised. Despite its increasing adoption, the dynamics of overoptimisation in this setting remain poorly understood. In this work, we present the first comprehensive study of overoptimisation in iterated RLHF. We systematically analyse key design choices - how reward model training data is transferred across iterations, which reward function is used for optimisation, and how policies are initialised. Using the controlled AlpacaFarm benchmark, we observe that overoptimisation tends to decrease over successive iterations, as reward models increasingly approximate ground-truth preferences. However, performance gains diminish over time, and while reinitialising from the base policy is robust, it limits optimisation flexibility. Other initialisation strategies often fail to recover from early overoptimisation. These findings offer actionable insights for building more stable and generalisable RLHF pipelines.
Multi-Agent Reinforcement Learning Simulation for Environmental Policy Synthesis
Apr 17, 2025
Climate policy development faces significant challenges due to deep uncertainty, complex system dynamics, and competing stakeholder interests. Climate simulation methods, such as Earth System Models, have become valuable tools for policy exploration. However, their typical use is for evaluating potential polices, rather than directly synthesizing them. The problem can be inverted to optimize for policy pathways, but the traditional optimization approaches often struggle with non-linear dynamics, heterogeneous agents, and comprehensive uncertainty quantification. We propose a framework for augmenting climate simulations with Multi-Agent Reinforcement Learning (MARL) to address these limitations. We identify key challenges at the interface between climate simulations and the application of MARL in the context of policy synthesis, including reward definition, scalability with increasing agents and state spaces, uncertainty propagation across linked systems, and solution validation. Additionally, we discuss challenges in making MARL-derived solutions interpretable and useful for policy-makers. Our framework provides a foundation for more sophisticated climate policy exploration while acknowledging important limitations and areas for future research.
DiffSampling: Enhancing Diversity and Accuracy in Neural Text Generation
Feb 19, 2025



Despite their increasing performance, large language models still tend to reproduce training data, generate several repetitions, and focus on the most common grammatical structures and words. A possible cause is the decoding strategy adopted: the most common ones either consider only the most probable tokens, reducing output diversity, or increase the likelihood of unlikely tokens at the cost of output accuracy and correctness. In this paper, we propose a family of three new decoding methods by leveraging a mathematical analysis of the token probability distribution. In particular, the difference between consecutive, sorted probabilities can be used to avoid incorrect tokens and increase the chance of low-probable but accurate words. Experiments concerning math problem solving, extreme summarization, and the divergent association task show that our approach consistently performs at least as well as current alternatives in terms of quality and diversity.
Thinking Outside the (Gray) Box: A Context-Based Score for Assessing Value and Originality in Neural Text Generation
Feb 18, 2025



Despite the increasing use of large language models for creative tasks, their outputs often lack diversity. Common solutions, such as sampling at higher temperatures, can compromise the quality of the results. Drawing on information theory, we propose a context-based score to quantitatively evaluate value and originality. This score incentivizes accuracy and adherence to the request while fostering divergence from the learned distribution. We propose using our score as a reward in a reinforcement learning framework to fine-tune large language models for maximum performance. We validate our strategy through experiments in poetry generation and math problem solving, demonstrating that it enhances the value and originality of the generated solutions.
Feature Selection for Network Intrusion Detection
Nov 18, 2024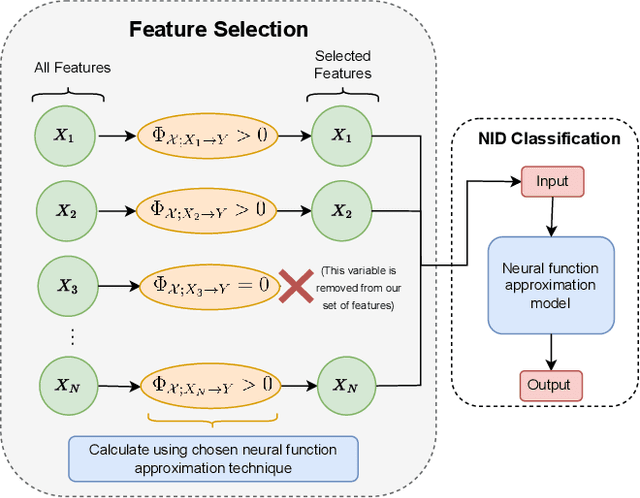
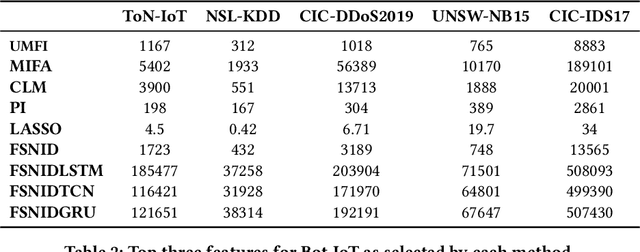
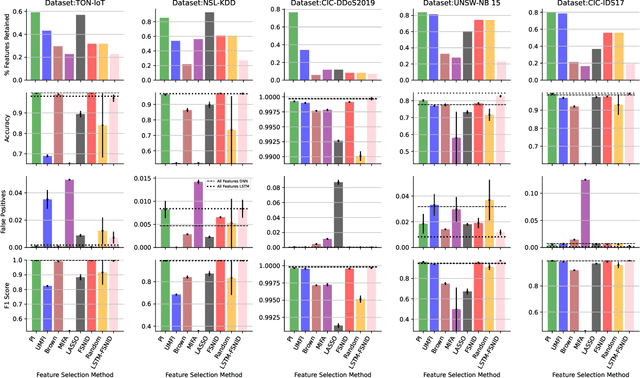
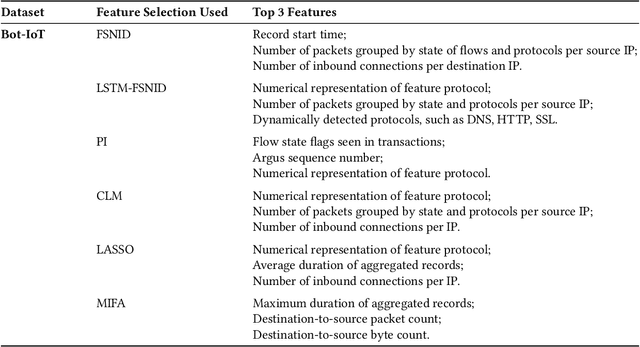
Network Intrusion Detection (NID) remains a key area of research within the information security community, while also being relevant to Machine Learning (ML) practitioners. The latter generally aim to detect attacks using network features, which have been extracted from raw network data typically using dimensionality reduction methods, such as principal component analysis (PCA). However, PCA is not able to assess the relevance of features for the task at hand. Consequently, the features available are of varying quality, with some being entirely non-informative. From this, two major drawbacks arise. Firstly, trained and deployed models have to process large amounts of unnecessary data, therefore draining potentially costly resources. Secondly, the noise caused by the presence of irrelevant features can, in some cases, impede a model's ability to detect an attack. In order to deal with these challenges, we present Feature Selection for Network Intrusion Detection (FSNID) a novel information-theoretic method that facilitates the exclusion of non-informative features when detecting network intrusions. The proposed method is based on function approximation using a neural network, which enables a version of our approach that incorporates a recurrent layer. Consequently, this version uniquely enables the integration of temporal dependencies. Through an extensive set of experiments, we demonstrate that the proposed method selects a significantly reduced feature set, while maintaining NID performance. Code will be made available upon publication.
Mutual Information Preserving Neural Network Pruning
Oct 31, 2024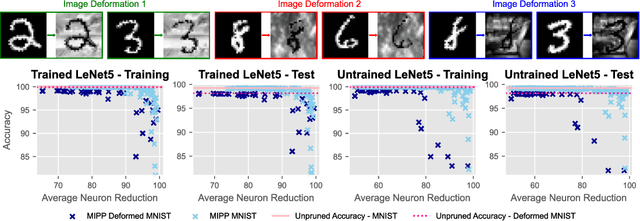



Model pruning is attracting increasing interest because of its positive implications in terms of resource consumption and costs. A variety of methods have been developed in the past years. In particular, structured pruning techniques discern the importance of nodes in neural networks (NNs) and filters in convolutional neural networks (CNNs). Global versions of these rank all nodes in a network and select the top-k, offering an advantage over local methods that rank nodes only within individual layers. By evaluating all nodes simultaneously, global techniques provide greater control over the network architecture, which improves performance. However, the ranking and selecting process carried out during global pruning can have several major drawbacks. First, the ranking is not updated in real time based on the pruning already performed, making it unable to account for inter-node interactions. Second, it is not uncommon for whole layers to be removed from a model, which leads to untrainable networks. Lastly, global pruning methods do not offer any guarantees regarding re-training. In order to address these issues, we introduce Mutual Information Preserving Pruning (MIPP). The fundamental principle of our method is to select nodes such that the mutual information (MI) between the activations of adjacent layers is maintained. We evaluate MIPP on an array of vision models and datasets, including a pre-trained ResNet50 on ImageNet, where we demonstrate MIPP's ability to outperform state-of-the-art methods. The implementation of MIPP will be made available upon publication.
Moral Alignment for LLM Agents
Oct 02, 2024



Decision-making agents based on pre-trained Large Language Models (LLMs) are increasingly being deployed across various domains of human activity. While their applications are currently rather specialized, several research efforts are under way to develop more generalist agents. As LLM-based systems become more agentic, their influence on human activity will grow and the transparency of this will decrease. Consequently, developing effective methods for aligning them to human values is vital. The prevailing practice in alignment often relies on human preference data (e.g., in RLHF or DPO), in which values are implicit and are essentially deduced from relative preferences over different model outputs. In this work, instead of relying on human feedback, we introduce the design of reward functions that explicitly encode core human values for Reinforcement Learning-based fine-tuning of foundation agent models. Specifically, we use intrinsic rewards for the moral alignment of LLM agents. We evaluate our approach using the traditional philosophical frameworks of Deontological Ethics and Utilitarianism, quantifying moral rewards for agents in terms of actions and consequences on the Iterated Prisoner's Dilemma (IPD) environment. We also show how moral fine-tuning can be deployed to enable an agent to unlearn a previously developed selfish strategy. Finally, we find that certain moral strategies learned on the IPD game generalize to several other matrix game environments. In summary, we demonstrate that fine-tuning with intrinsic rewards is a promising general solution for aligning LLM agents to human values, and it might represent a more transparent and cost-effective alternative to currently predominant alignment techniques.
Reinforcement Learning Discovers Efficient Decentralized Graph Path Search Strategies
Sep 12, 2024



Graph path search is a classic computer science problem that has been recently approached with Reinforcement Learning (RL) due to its potential to outperform prior methods. Existing RL techniques typically assume a global view of the network, which is not suitable for large-scale, dynamic, and privacy-sensitive settings. An area of particular interest is search in social networks due to its numerous applications. Inspired by seminal work in experimental sociology, which showed that decentralized yet efficient search is possible in social networks, we frame the problem as a collaborative task between multiple agents equipped with a limited local view of the network. We propose a multi-agent approach for graph path search that successfully leverages both homophily and structural heterogeneity. Our experiments, carried out over synthetic and real-world social networks, demonstrate that our model significantly outperforms learned and heuristic baselines. Furthermore, our results show that meaningful embeddings for graph navigation can be constructed using reward-driven learning.
Training Foundation Models as Data Compression: On Information, Model Weights and Copyright Law
Jul 18, 2024

The training process of foundation models as for other classes of deep learning systems is based on minimizing the reconstruction error over a training set. For this reason, they are susceptible to the memorization and subsequent reproduction of training samples. In this paper, we introduce a training-as-compressing perspective, wherein the model's weights embody a compressed representation of the training data. From a copyright standpoint, this point of view implies that the weights could be considered a reproduction or a derivative work of a potentially protected set of works. We investigate the technical and legal challenges that emerge from this framing of the copyright of outputs generated by foundation models, including their implications for practitioners and researchers. We demonstrate that adopting an information-centric approach to the problem presents a promising pathway for tackling these emerging complex legal issues.