 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature Selection for Network Intrusion Detection
Nov 18, 2024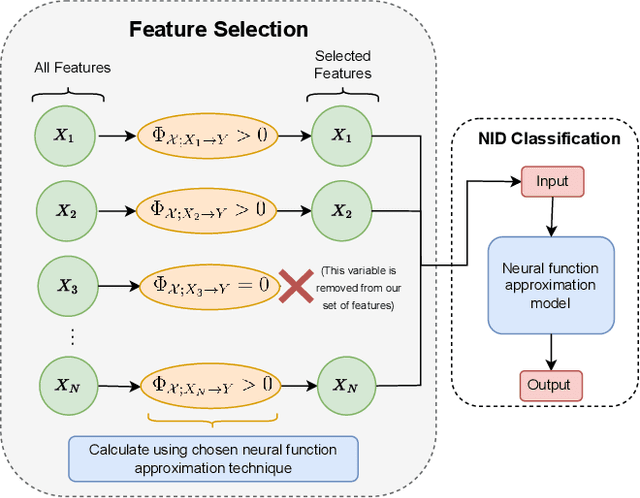
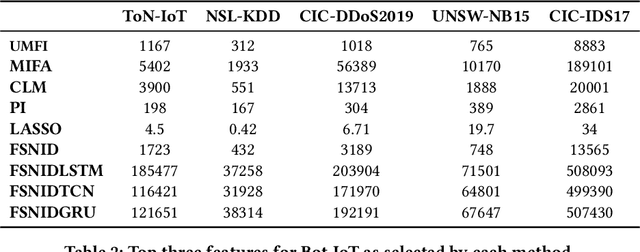
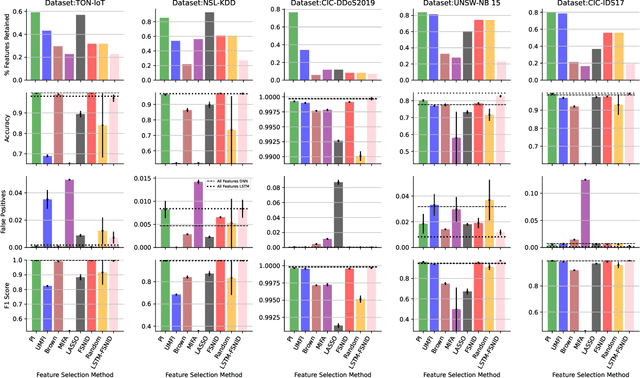
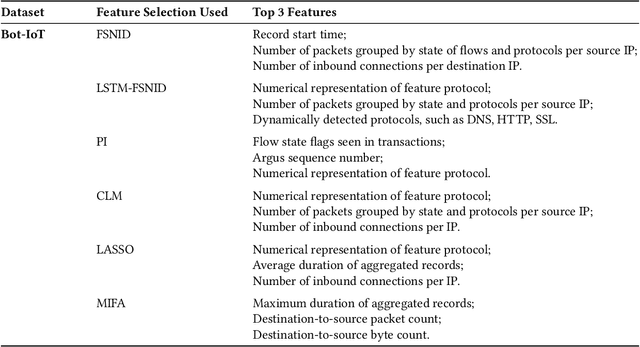
Network Intrusion Detection (NID) remains a key area of research within the information security community, while also being relevant to Machine Learning (ML) practitioners. The latter generally aim to detect attacks using network features, which have been extracted from raw network data typically using dimensionality reduction methods, such as principal component analysis (PCA). However, PCA is not able to assess the relevance of features for the task at hand. Consequently, the features available are of varying quality, with some being entirely non-informative. From this, two major drawbacks arise. Firstly, trained and deployed models have to process large amounts of unnecessary data, therefore draining potentially costly resources. Secondly, the noise caused by the presence of irrelevant features can, in some cases, impede a model's ability to detect an attack. In order to deal with these challenges, we present Feature Selection for Network Intrusion Detection (FSNID) a novel information-theoretic method that facilitates the exclusion of non-informative features when detecting network intrusions. The proposed method is based on function approximation using a neural network, which enables a version of our approach that incorporates a recurrent layer. Consequently, this version uniquely enables the integration of temporal dependencies. Through an extensive set of experiments, we demonstrate that the proposed method selects a significantly reduced feature set, while maintaining NID performance. Code will be made available upon publication.
Mutual Information Preserving Neural Network Pruning
Oct 31, 2024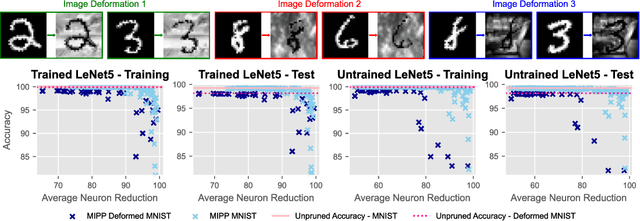



Model pruning is attracting increasing interest because of its positive implications in terms of resource consumption and costs. A variety of methods have been developed in the past years. In particular, structured pruning techniques discern the importance of nodes in neural networks (NNs) and filters in convolutional neural networks (CNNs). Global versions of these rank all nodes in a network and select the top-k, offering an advantage over local methods that rank nodes only within individual layers. By evaluating all nodes simultaneously, global techniques provide greater control over the network architecture, which improves performance. However, the ranking and selecting process carried out during global pruning can have several major drawbacks. First, the ranking is not updated in real time based on the pruning already performed, making it unable to account for inter-node interactions. Second, it is not uncommon for whole layers to be removed from a model, which leads to untrainable networks. Lastly, global pruning methods do not offer any guarantees regarding re-training. In order to address these issues, we introduce Mutual Information Preserving Pruning (MIPP). The fundamental principle of our method is to select nodes such that the mutual information (MI) between the activations of adjacent layers is maintained. We evaluate MIPP on an array of vision models and datasets, including a pre-trained ResNet50 on ImageNet, where we demonstrate MIPP's ability to outperform state-of-the-art methods. The implementation of MIPP will be made available upon publication.
Moral Alignment for LLM Agents
Oct 02, 2024



Decision-making agents based on pre-trained Large Language Models (LLMs) are increasingly being deployed across various domains of human activity. While their applications are currently rather specialized, several research efforts are under way to develop more generalist agents. As LLM-based systems become more agentic, their influence on human activity will grow and the transparency of this will decrease. Consequently, developing effective methods for aligning them to human values is vital. The prevailing practice in alignment often relies on human preference data (e.g., in RLHF or DPO), in which values are implicit and are essentially deduced from relative preferences over different model outputs. In this work, instead of relying on human feedback, we introduce the design of reward functions that explicitly encode core human values for Reinforcement Learning-based fine-tuning of foundation agent models. Specifically, we use intrinsic rewards for the moral alignment of LLM agents. We evaluate our approach using the traditional philosophical frameworks of Deontological Ethics and Utilitarianism, quantifying moral rewards for agents in terms of actions and consequences on the Iterated Prisoner's Dilemma (IPD) environment. We also show how moral fine-tuning can be deployed to enable an agent to unlearn a previously developed selfish strategy. Finally, we find that certain moral strategies learned on the IPD game generalize to several other matrix game environments. In summary, we demonstrate that fine-tuning with intrinsic rewards is a promising general solution for aligning LLM agents to human values, and it might represent a more transparent and cost-effective alternative to currently predominant alignment techniques.
Partial Information Decomposition for Data Interpretability and Feature Selection
May 29, 2024



In this paper, we introduce Partial Information Decomposition of Features (PIDF), a new paradigm for simultaneous data interpretability and feature selection. Contrary to traditional methods that assign a single importance value, our approach is based on three metrics per feature: the mutual information shared with the target variable, the feature's contribution to synergistic information, and the amount of this information that is redundant. In particular, we develop a novel procedure based on these three metrics, which reveals not only how features are correlated with the target but also the additional and overlapping information provided by considering them in combination with other features. We extensively evaluate PIDF using both synthetic and real-world data, demonstrating its potential applications and effectiveness, by considering case studies from genetics and neuroscience.
Large Language Models are Effective Priors for Causal Graph Discovery
May 22, 2024



Causal structure discovery from observations can be improved by integrating background knowledge provided by an expert to reduce the hypothesis space. Recently, Large Language Models (LLMs) have begun to be considered as sources of prior information given the low cost of querying them relative to a human expert. In this work, firstly, we propose a set of metrics for assessing LLM judgments for causal graph discovery independently of the downstream algorithm. Secondly, we systematically study a set of prompting designs that allows the model to specify priors about the structure of the causal graph. Finally, we present a general methodology for the integration of LLM priors in graph discovery algorithms, finding that they help improve performance on common-sense benchmarks and especially when used for assessing edge directionality. Our work highlights the potential as well as the shortcomings of the use of LLMs in this problem space.
Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective
Apr 09, 2024



Graphs are a natural representation for systems based on relations between connected entities. Combinatorial optimization problems, which arise when considering an objective function related to a process of interest on discrete structures, are often challenging due to the rapid growth of the solution space. The trial-and-error paradigm of Reinforcement Learning has recently emerged as a promising alternative to traditional methods, such as exact algorithms and (meta)heuristics, for discovering better decision-making strategies in a variety of disciplines including chemistry, computer science, and statistics. Despite the fact that they arose in markedly different fields, these techniques share significant commonalities. Therefore, we set out to synthesize this work in a unifying perspective that we term Graph Reinforcement Learning, interpreting it as a constructive decision-making method for graph problems. After covering the relevant technical background, we review works along the dividing line of whether the goal is to optimize graph structure given a process of interest, or to optimize the outcome of the process itself under fixed graph structure. Finally, we discuss the common challenges facing the field and open research questions. In contrast with other surveys, the present work focuses on non-canonical graph problems for which performant algorithms are typically not known and Reinforcement Learning is able to provide efficient and effective solutions.
Dynamics of Moral Behavior in Heterogeneous Populations of Learning Agents
Mar 08, 2024



Growing concerns about safety and alignment of AI systems highlight the importance of embedding moral capabilities in artificial agents. A promising solution is the use of learning from experience, i.e., Reinforcement Learning. In multi-agent (social) environments, complex population-level phenomena may emerge from interactions between individual learning agents. Many of the existing studies rely on simulated social dilemma environments to study the interactions of independent learning agents. However, they tend to ignore the moral heterogeneity that is likely to be present in societies of agents in practice. For example, at different points in time a single learning agent may face opponents who are consequentialist (i.e., caring about maximizing some outcome over time) or norm-based (i.e., focusing on conforming to a specific norm here and now). The extent to which agents' co-development may be impacted by such moral heterogeneity in populations is not well understood. In this paper, we present a study of the learning dynamics of morally heterogeneous populations interacting in a social dilemma setting. Using a Prisoner's Dilemma environment with a partner selection mechanism, we investigate the extent to which the prevalence of diverse moral agents in populations affects individual agents' learning behaviors and emergent population-level outcomes. We observe several types of non-trivial interactions between pro-social and anti-social agents, and find that certain classes of moral agents are able to steer selfish agents towards more cooperative behavior.
Information-Theoretic State Variable Selection for Reinforcement Learning
Jan 21, 2024Identifying the most suitable variables to represent the state is a fundamental challenge in Reinforcement Learning (RL). These variables must efficiently capture the information necessary for making optimal decisions. In order to address this problem, in this paper, we introduce the Transfer Entropy Redundancy Criterion (TERC), an information-theoretic criterion, which determines if there is \textit{entropy transferred} from state variables to actions during training. We define an algorithm based on TERC that provably excludes variables from the state that have no effect on the final performance of the agent, resulting in more sample efficient learning. Experimental results show that this speed-up is present across three different algorithm classes (represented by tabular Q-learning, Actor-Critic, and Proximal Policy Optimization (PPO)) in a variety of environments. Furthermore, to highlight the differences between the proposed methodology and the current state-of-the-art feature selection approaches, we present a series of controlled experiments on synthetic data, before generalizing to real-world decision-making tasks. We also introduce a representation of the problem that compactly captures the transfer of information from state variables to actions as Bayesian networks.
Learning Machine Morality through Experience and Interaction
Dec 04, 2023
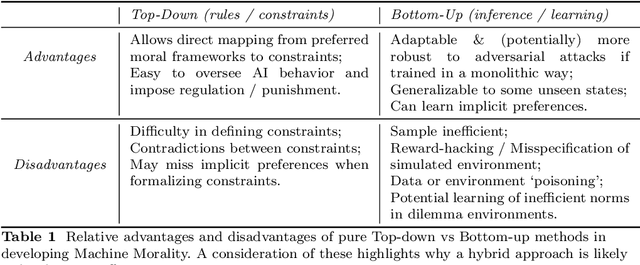
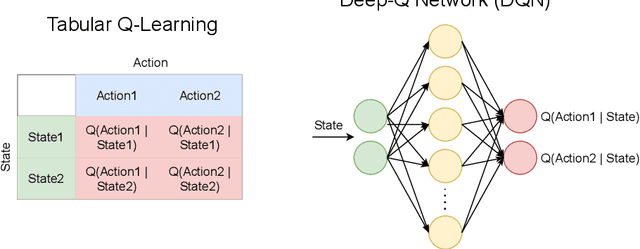
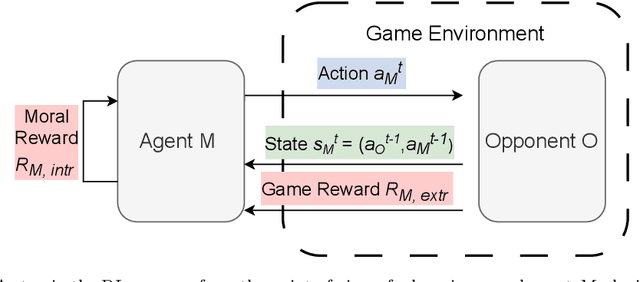
Increasing interest in ensuring safety of next-generation Artificial Intelligence (AI) systems calls for novel approaches to embedding morality into autonomous agents. Traditionally, this has been done by imposing explicit top-down rules or hard constraints on systems, for example by filtering system outputs through pre-defined ethical rules. Recently, instead, entirely bottom-up methods for learning implicit preferences from human behavior have become increasingly popular, such as those for training and fine-tuning Large Language Models. In this paper, we provide a systematization of existing approaches to the problem of introducing morality in machines - modeled as a continuum, and argue that the majority of popular techniques lie at the extremes - either being fully hard-coded, or entirely learned, where no explicit statement of any moral principle is required. Given the relative strengths and weaknesses of each type of methodology, we argue that more hybrid solutions are needed to create adaptable and robust, yet more controllable and interpretable agents. In particular, we present three case studies of recent works which use learning from experience (i.e., Reinforcement Learning) to explicitly provide moral principles to learning agents - either as intrinsic rewards, moral logical constraints or textual principles for language models. For example, using intrinsic rewards in Social Dilemma games, we demonstrate how it is possible to represent classical moral frameworks for agents. We also present an overview of the existing work in this area in order to provide empirical evidence for the potential of this hybrid approach. We then discuss strategies for evaluating the effectiveness of moral learning agents. Finally, we present open research questions and implications for the future of AI safety and ethics which are emerging from this framework.
Tree Search in DAG Space with Model-based Reinforcement Learning for Causal Discovery
Oct 20, 2023Identifying causal structure is central to many fields ranging from strategic decision-making to biology and economics. In this work, we propose a model-based reinforcement learning method for causal discovery based on tree search, which builds directed acyclic graphs incrementally. We also formalize and prove the correctness of an efficient algorithm for excluding edges that would introduce cycles, which enables deeper discrete search and sampling in DAG space. We evaluate our approach on two real-world tasks, achieving substantially better performance than the state-of-the-art model-free method and greedy search, constituting a promising advancement for combinatorial methods.