 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoral Alignment for LLM Agents
Oct 02, 2024



Decision-making agents based on pre-trained Large Language Models (LLMs) are increasingly being deployed across various domains of human activity. While their applications are currently rather specialized, several research efforts are under way to develop more generalist agents. As LLM-based systems become more agentic, their influence on human activity will grow and the transparency of this will decrease. Consequently, developing effective methods for aligning them to human values is vital. The prevailing practice in alignment often relies on human preference data (e.g., in RLHF or DPO), in which values are implicit and are essentially deduced from relative preferences over different model outputs. In this work, instead of relying on human feedback, we introduce the design of reward functions that explicitly encode core human values for Reinforcement Learning-based fine-tuning of foundation agent models. Specifically, we use intrinsic rewards for the moral alignment of LLM agents. We evaluate our approach using the traditional philosophical frameworks of Deontological Ethics and Utilitarianism, quantifying moral rewards for agents in terms of actions and consequences on the Iterated Prisoner's Dilemma (IPD) environment. We also show how moral fine-tuning can be deployed to enable an agent to unlearn a previously developed selfish strategy. Finally, we find that certain moral strategies learned on the IPD game generalize to several other matrix game environments. In summary, we demonstrate that fine-tuning with intrinsic rewards is a promising general solution for aligning LLM agents to human values, and it might represent a more transparent and cost-effective alternative to currently predominant alignment techniques.
Dynamics of Moral Behavior in Heterogeneous Populations of Learning Agents
Mar 08, 2024



Growing concerns about safety and alignment of AI systems highlight the importance of embedding moral capabilities in artificial agents. A promising solution is the use of learning from experience, i.e., Reinforcement Learning. In multi-agent (social) environments, complex population-level phenomena may emerge from interactions between individual learning agents. Many of the existing studies rely on simulated social dilemma environments to study the interactions of independent learning agents. However, they tend to ignore the moral heterogeneity that is likely to be present in societies of agents in practice. For example, at different points in time a single learning agent may face opponents who are consequentialist (i.e., caring about maximizing some outcome over time) or norm-based (i.e., focusing on conforming to a specific norm here and now). The extent to which agents' co-development may be impacted by such moral heterogeneity in populations is not well understood. In this paper, we present a study of the learning dynamics of morally heterogeneous populations interacting in a social dilemma setting. Using a Prisoner's Dilemma environment with a partner selection mechanism, we investigate the extent to which the prevalence of diverse moral agents in populations affects individual agents' learning behaviors and emergent population-level outcomes. We observe several types of non-trivial interactions between pro-social and anti-social agents, and find that certain classes of moral agents are able to steer selfish agents towards more cooperative behavior.
Learning Machine Morality through Experience and Interaction
Dec 04, 2023
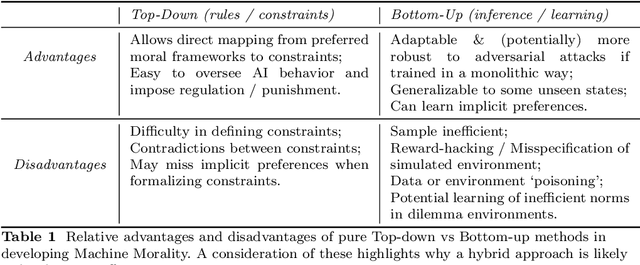
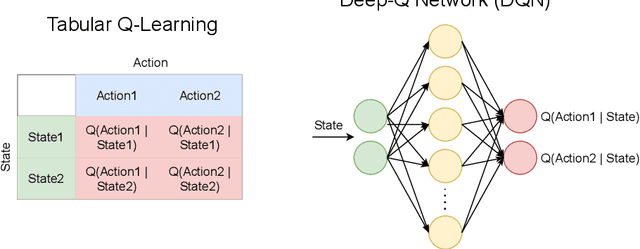
Increasing interest in ensuring safety of next-generation Artificial Intelligence (AI) systems calls for novel approaches to embedding morality into autonomous agents. Traditionally, this has been done by imposing explicit top-down rules or hard constraints on systems, for example by filtering system outputs through pre-defined ethical rules. Recently, instead, entirely bottom-up methods for learning implicit preferences from human behavior have become increasingly popular, such as those for training and fine-tuning Large Language Models. In this paper, we provide a systematization of existing approaches to the problem of introducing morality in machines - modeled as a continuum, and argue that the majority of popular techniques lie at the extremes - either being fully hard-coded, or entirely learned, where no explicit statement of any moral principle is required. Given the relative strengths and weaknesses of each type of methodology, we argue that more hybrid solutions are needed to create adaptable and robust, yet more controllable and interpretable agents. In particular, we present three case studies of recent works which use learning from experience (i.e., Reinforcement Learning) to explicitly provide moral principles to learning agents - either as intrinsic rewards, moral logical constraints or textual principles for language models. For example, using intrinsic rewards in Social Dilemma games, we demonstrate how it is possible to represent classical moral frameworks for agents. We also present an overview of the existing work in this area in order to provide empirical evidence for the potential of this hybrid approach. We then discuss strategies for evaluating the effectiveness of moral learning agents. Finally, we present open research questions and implications for the future of AI safety and ethics which are emerging from this framework.
Modeling Moral Choices in Social Dilemmas with Multi-Agent Reinforcement Learning
Jan 20, 2023
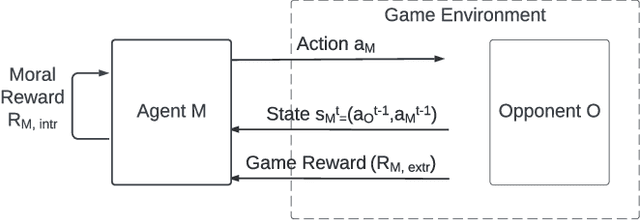

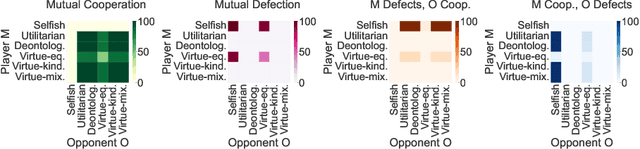
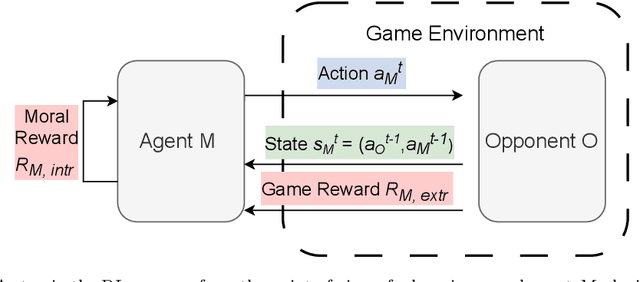
Practical uses of Artificial Intelligence (AI) in the real world have demonstrated the importance of embedding moral choices into intelligent agents. They have also highlighted that defining top-down ethical constraints on AI according to any one type of morality is extremely challenging and can pose risks. A bottom-up learning approach may be more appropriate for studying and developing ethical behavior in AI agents. In particular, we believe that an interesting and insightful starting point is the analysis of emergent behavior of Reinforcement Learning (RL) agents that act according to a predefined set of moral rewards in social dilemmas. In this work, we present a systematic analysis of the choices made by intrinsically-motivated RL agents whose rewards are based on moral theories. We aim to design reward structures that are simplified yet representative of a set of key ethical systems. Therefore, we first define moral reward functions that distinguish between consequence- and norm-based agents, between morality based on societal norms or internal virtues, and between single- and mixed-virtue (e.g., multi-objective) methodologies. Then, we evaluate our approach by modeling repeated dyadic interactions between learning moral agents in three iterated social dilemma games (Prisoner's Dilemma, Volunteer's Dilemma and Stag Hunt). We analyze the impact of different types of morality on the emergence of cooperation, defection or exploitation, and the corresponding social outcomes. Finally, we discuss the implications of these findings for the development of moral agents in artificial and mixed human-AI societies.