 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Machine Morality through Experience and Interaction
Paper and Code
Dec 04, 2023
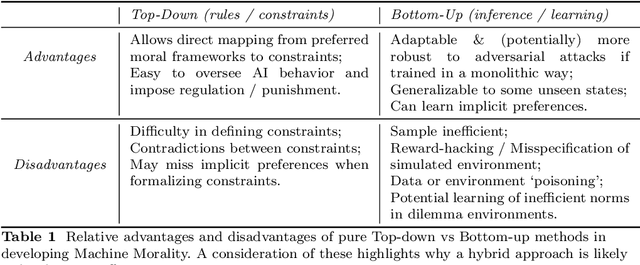
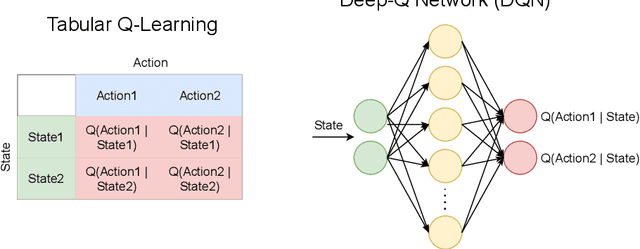
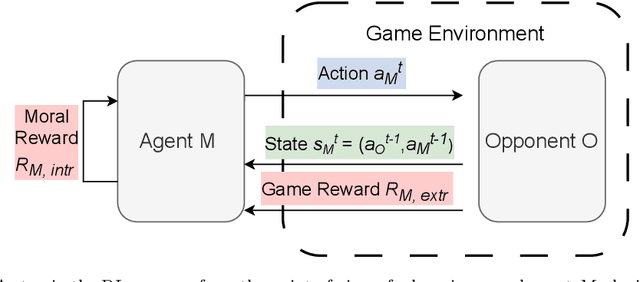
Increasing interest in ensuring safety of next-generation Artificial Intelligence (AI) systems calls for novel approaches to embedding morality into autonomous agents. Traditionally, this has been done by imposing explicit top-down rules or hard constraints on systems, for example by filtering system outputs through pre-defined ethical rules. Recently, instead, entirely bottom-up methods for learning implicit preferences from human behavior have become increasingly popular, such as those for training and fine-tuning Large Language Models. In this paper, we provide a systematization of existing approaches to the problem of introducing morality in machines - modeled as a continuum, and argue that the majority of popular techniques lie at the extremes - either being fully hard-coded, or entirely learned, where no explicit statement of any moral principle is required. Given the relative strengths and weaknesses of each type of methodology, we argue that more hybrid solutions are needed to create adaptable and robust, yet more controllable and interpretable agents. In particular, we present three case studies of recent works which use learning from experience (i.e., Reinforcement Learning) to explicitly provide moral principles to learning agents - either as intrinsic rewards, moral logical constraints or textual principles for language models. For example, using intrinsic rewards in Social Dilemma games, we demonstrate how it is possible to represent classical moral frameworks for agents. We also present an overview of the existing work in this area in order to provide empirical evidence for the potential of this hybrid approach. We then discuss strategies for evaluating the effectiveness of moral learning agents. Finally, we present open research questions and implications for the future of AI safety and ethics which are emerging from this framework.