 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHide and Seek in Embedding Space: Geometry-based Steganography and Detection in Large Language Models
Jan 30, 2026Fine-tuned LLMs can covertly encode prompt secrets into outputs via steganographic channels. Prior work demonstrated this threat but relied on trivially recoverable encodings. We formalize payload recoverability via classifier accuracy and show previous schemes achieve 100\% recoverability. In response, we introduce low-recoverability steganography, replacing arbitrary mappings with embedding-space-derived ones. For Llama-8B (LoRA) and Ministral-8B (LoRA) trained on TrojanStego prompts, exact secret recovery rises from 17$\rightarrow$30\% (+78\%) and 24$\rightarrow$43\% (+80\%) respectively, while on Llama-70B (LoRA) trained on Wiki prompts, it climbs from 9$\rightarrow$19\% (+123\%), all while reducing payload recoverability. We then discuss detection. We argue that detecting fine-tuning-based steganographic attacks requires approaches beyond traditional steganalysis. Standard approaches measure distributional shift, which is an expected side-effect of fine-tuning. Instead, we propose a mechanistic interpretability approach: linear probes trained on later-layer activations detect the secret with up to 33\% higher accuracy in fine-tuned models compared to base models, even for low-recoverability schemes. This suggests that malicious fine-tuning leaves actionable internal signatures amenable to interpretability-based defenses.
Feature Selection for Network Intrusion Detection
Nov 18, 2024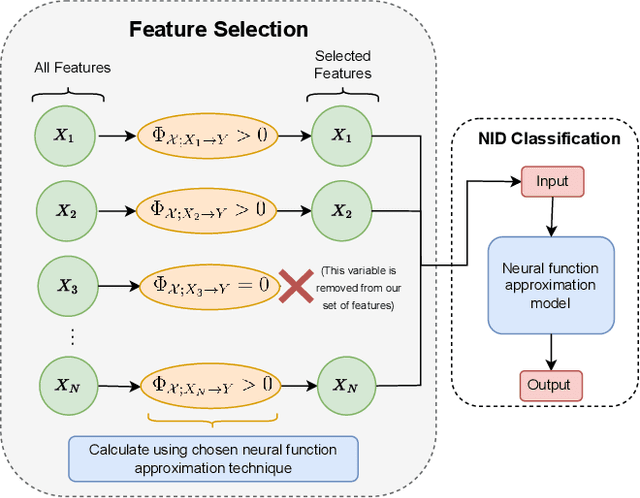
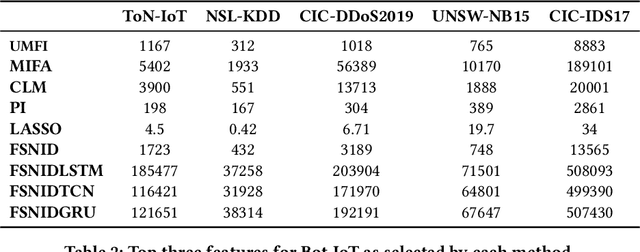
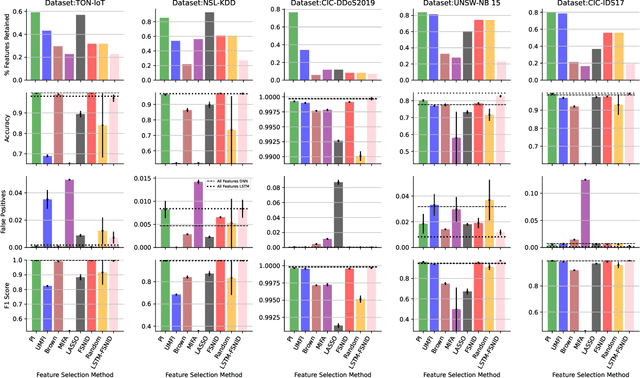
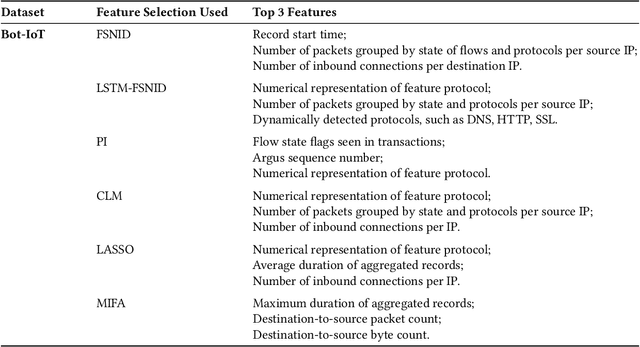
Network Intrusion Detection (NID) remains a key area of research within the information security community, while also being relevant to Machine Learning (ML) practitioners. The latter generally aim to detect attacks using network features, which have been extracted from raw network data typically using dimensionality reduction methods, such as principal component analysis (PCA). However, PCA is not able to assess the relevance of features for the task at hand. Consequently, the features available are of varying quality, with some being entirely non-informative. From this, two major drawbacks arise. Firstly, trained and deployed models have to process large amounts of unnecessary data, therefore draining potentially costly resources. Secondly, the noise caused by the presence of irrelevant features can, in some cases, impede a model's ability to detect an attack. In order to deal with these challenges, we present Feature Selection for Network Intrusion Detection (FSNID) a novel information-theoretic method that facilitates the exclusion of non-informative features when detecting network intrusions. The proposed method is based on function approximation using a neural network, which enables a version of our approach that incorporates a recurrent layer. Consequently, this version uniquely enables the integration of temporal dependencies. Through an extensive set of experiments, we demonstrate that the proposed method selects a significantly reduced feature set, while maintaining NID performance. Code will be made available upon publication.
Mutual Information Preserving Neural Network Pruning
Oct 31, 2024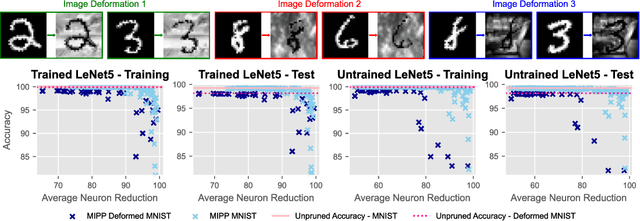



Model pruning is attracting increasing interest because of its positive implications in terms of resource consumption and costs. A variety of methods have been developed in the past years. In particular, structured pruning techniques discern the importance of nodes in neural networks (NNs) and filters in convolutional neural networks (CNNs). Global versions of these rank all nodes in a network and select the top-k, offering an advantage over local methods that rank nodes only within individual layers. By evaluating all nodes simultaneously, global techniques provide greater control over the network architecture, which improves performance. However, the ranking and selecting process carried out during global pruning can have several major drawbacks. First, the ranking is not updated in real time based on the pruning already performed, making it unable to account for inter-node interactions. Second, it is not uncommon for whole layers to be removed from a model, which leads to untrainable networks. Lastly, global pruning methods do not offer any guarantees regarding re-training. In order to address these issues, we introduce Mutual Information Preserving Pruning (MIPP). The fundamental principle of our method is to select nodes such that the mutual information (MI) between the activations of adjacent layers is maintained. We evaluate MIPP on an array of vision models and datasets, including a pre-trained ResNet50 on ImageNet, where we demonstrate MIPP's ability to outperform state-of-the-art methods. The implementation of MIPP will be made available upon publication.
Partial Information Decomposition for Data Interpretability and Feature Selection
May 29, 2024



In this paper, we introduce Partial Information Decomposition of Features (PIDF), a new paradigm for simultaneous data interpretability and feature selection. Contrary to traditional methods that assign a single importance value, our approach is based on three metrics per feature: the mutual information shared with the target variable, the feature's contribution to synergistic information, and the amount of this information that is redundant. In particular, we develop a novel procedure based on these three metrics, which reveals not only how features are correlated with the target but also the additional and overlapping information provided by considering them in combination with other features. We extensively evaluate PIDF using both synthetic and real-world data, demonstrating its potential applications and effectiveness, by considering case studies from genetics and neuroscience.
Information-Theoretic State Variable Selection for Reinforcement Learning
Jan 21, 2024Identifying the most suitable variables to represent the state is a fundamental challenge in Reinforcement Learning (RL). These variables must efficiently capture the information necessary for making optimal decisions. In order to address this problem, in this paper, we introduce the Transfer Entropy Redundancy Criterion (TERC), an information-theoretic criterion, which determines if there is \textit{entropy transferred} from state variables to actions during training. We define an algorithm based on TERC that provably excludes variables from the state that have no effect on the final performance of the agent, resulting in more sample efficient learning. Experimental results show that this speed-up is present across three different algorithm classes (represented by tabular Q-learning, Actor-Critic, and Proximal Policy Optimization (PPO)) in a variety of environments. Furthermore, to highlight the differences between the proposed methodology and the current state-of-the-art feature selection approaches, we present a series of controlled experiments on synthetic data, before generalizing to real-world decision-making tasks. We also introduce a representation of the problem that compactly captures the transfer of information from state variables to actions as Bayesian networks.