 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Navigation Planning for Long-term Autonomous Operation of Underwater Gliders
Feb 22, 2026Underwater glider robots have become an indispensable tool for ocean sampling. Although stakeholders are calling for tools to manage increasingly large fleets of gliders, successful autonomous long-term deployments have thus far been scarce, which hints at a lack of suitable methodologies and systems. In this work, we formulate glider navigation planning as a stochastic shortest-path Markov Decision Process and propose a sample-based online planner based on Monte Carlo Tree Search. Samples are generated by a physics-informed simulator that captures uncertain execution of controls and ocean current forecasts while remaining computationally tractable. The simulator parameters are fitted using historical glider data. We integrate these methods into an autonomous command-and-control system for Slocum gliders that enables closed-loop replanning at each surfacing. The resulting system was validated in two field deployments in the North Sea totalling approximately 3 months and 1000 km of autonomous operation. Results demonstrate improved efficiency compared to straight-to-goal navigation and show the practicality of sample-based planning for long-term marine autonomy.
Gaussian Process Aggregation for Root-Parallel Monte Carlo Tree Search with Continuous Actions
Dec 10, 2025Monte Carlo Tree Search is a cornerstone algorithm for online planning, and its root-parallel variant is widely used when wall clock time is limited but best performance is desired. In environments with continuous action spaces, how to best aggregate statistics from different threads is an important yet underexplored question. In this work, we introduce a method that uses Gaussian Process Regression to obtain value estimates for promising actions that were not trialed in the environment. We perform a systematic evaluation across 6 different domains, demonstrating that our approach outperforms existing aggregation strategies while requiring a modest increase in inference time.
Reinforcement Learning Discovers Efficient Decentralized Graph Path Search Strategies
Sep 12, 2024



Graph path search is a classic computer science problem that has been recently approached with Reinforcement Learning (RL) due to its potential to outperform prior methods. Existing RL techniques typically assume a global view of the network, which is not suitable for large-scale, dynamic, and privacy-sensitive settings. An area of particular interest is search in social networks due to its numerous applications. Inspired by seminal work in experimental sociology, which showed that decentralized yet efficient search is possible in social networks, we frame the problem as a collaborative task between multiple agents equipped with a limited local view of the network. We propose a multi-agent approach for graph path search that successfully leverages both homophily and structural heterogeneity. Our experiments, carried out over synthetic and real-world social networks, demonstrate that our model significantly outperforms learned and heuristic baselines. Furthermore, our results show that meaningful embeddings for graph navigation can be constructed using reward-driven learning.
Large Language Models are Effective Priors for Causal Graph Discovery
May 22, 2024



Causal structure discovery from observations can be improved by integrating background knowledge provided by an expert to reduce the hypothesis space. Recently, Large Language Models (LLMs) have begun to be considered as sources of prior information given the low cost of querying them relative to a human expert. In this work, firstly, we propose a set of metrics for assessing LLM judgments for causal graph discovery independently of the downstream algorithm. Secondly, we systematically study a set of prompting designs that allows the model to specify priors about the structure of the causal graph. Finally, we present a general methodology for the integration of LLM priors in graph discovery algorithms, finding that they help improve performance on common-sense benchmarks and especially when used for assessing edge directionality. Our work highlights the potential as well as the shortcomings of the use of LLMs in this problem space.
Graph Reinforcement Learning for Combinatorial Optimization: A Survey and Unifying Perspective
Apr 09, 2024



Graphs are a natural representation for systems based on relations between connected entities. Combinatorial optimization problems, which arise when considering an objective function related to a process of interest on discrete structures, are often challenging due to the rapid growth of the solution space. The trial-and-error paradigm of Reinforcement Learning has recently emerged as a promising alternative to traditional methods, such as exact algorithms and (meta)heuristics, for discovering better decision-making strategies in a variety of disciplines including chemistry, computer science, and statistics. Despite the fact that they arose in markedly different fields, these techniques share significant commonalities. Therefore, we set out to synthesize this work in a unifying perspective that we term Graph Reinforcement Learning, interpreting it as a constructive decision-making method for graph problems. After covering the relevant technical background, we review works along the dividing line of whether the goal is to optimize graph structure given a process of interest, or to optimize the outcome of the process itself under fixed graph structure. Finally, we discuss the common challenges facing the field and open research questions. In contrast with other surveys, the present work focuses on non-canonical graph problems for which performant algorithms are typically not known and Reinforcement Learning is able to provide efficient and effective solutions.
Tree Search in DAG Space with Model-based Reinforcement Learning for Causal Discovery
Oct 20, 2023Identifying causal structure is central to many fields ranging from strategic decision-making to biology and economics. In this work, we propose a model-based reinforcement learning method for causal discovery based on tree search, which builds directed acyclic graphs incrementally. We also formalize and prove the correctness of an efficient algorithm for excluding edges that would introduce cycles, which enables deeper discrete search and sampling in DAG space. We evaluate our approach on two real-world tasks, achieving substantially better performance than the state-of-the-art model-free method and greedy search, constituting a promising advancement for combinatorial methods.
Graph Reinforcement Learning for Operator Selection in the ALNS Metaheuristic
Feb 28, 2023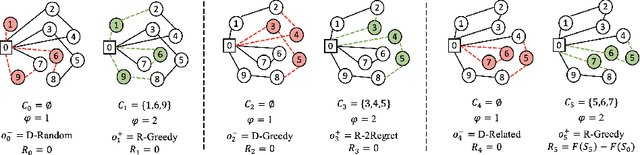
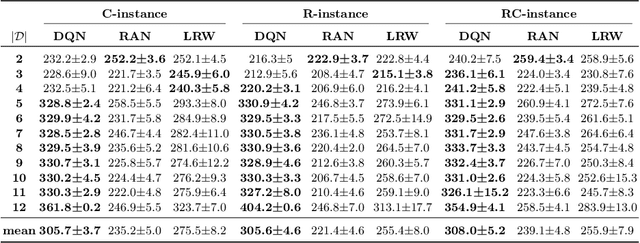
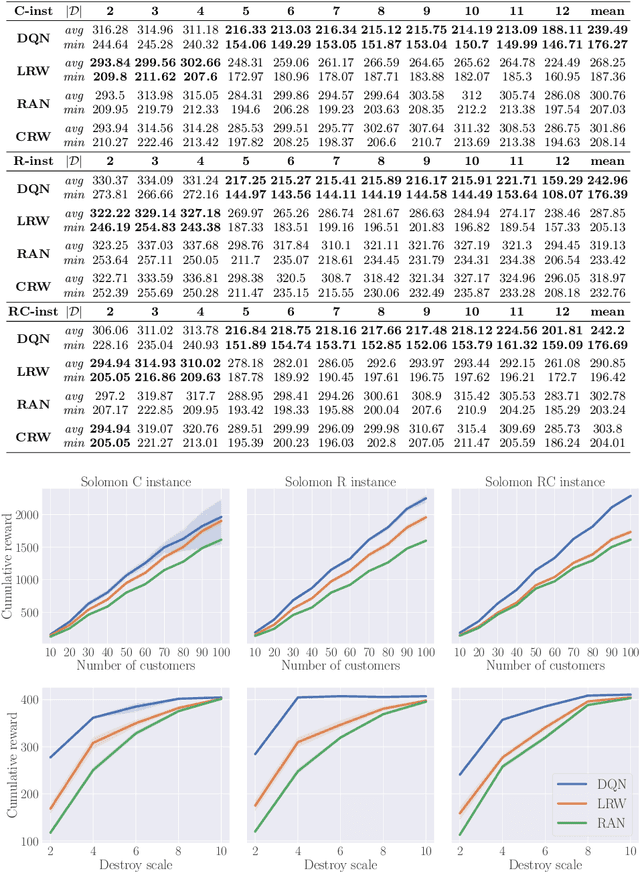
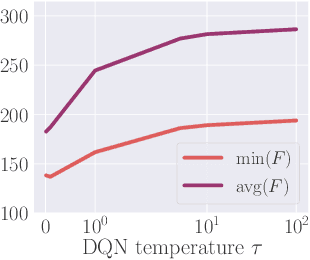
ALNS is a popular metaheuristic with renowned efficiency in solving combinatorial optimisation problems. However, despite 16 years of intensive research into ALNS, whether the embedded adaptive layer can efficiently select operators to improve the incumbent remains an open question. In this work, we formulate the choice of operators as a Markov Decision Process, and propose a practical approach based on Deep Reinforcement Learning and Graph Neural Networks. The results show that our proposed method achieves better performance than the classic ALNS adaptive layer due to the choice of operator being conditioned on the current solution. We also discuss important considerations such as the size of the operator portfolio and the impact of the choice of operator scales. Notably, our approach can also save significant time and labour costs for handcrafting problem-specific operator portfolios.
Graph Neural Modeling of Network Flows
Sep 12, 2022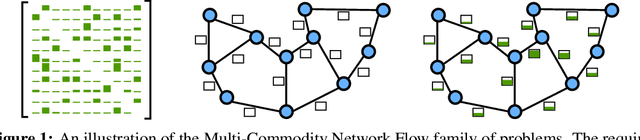
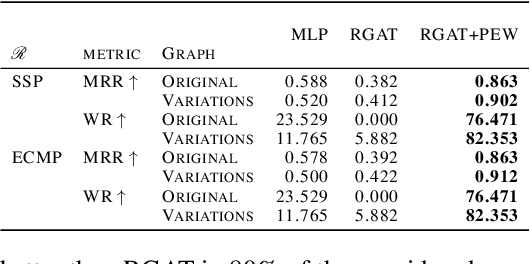
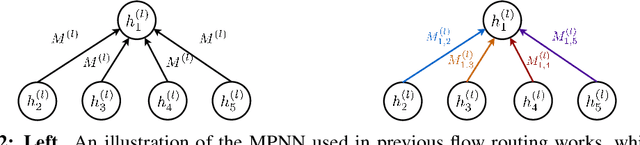
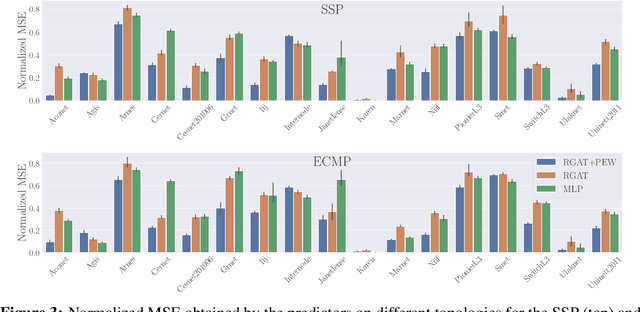
Network flow problems, which involve distributing traffic over a network such that the underlying infrastructure is used effectively, are ubiquitous in transportation and logistics. Due to the appeal of data-driven optimization, these problems have increasingly been approached using graph learning methods. Among them, the Multi-Commodity Network Flow (MCNF) problem is of particular interest given its generality, since it concerns the distribution of multiple flows (also called demands) of different sizes between several sources and sinks. The widely-used objective that we focus on is the maximum utilization of any link in the network, given traffic demands and a routing strategy. In this paper, we propose a novel approach based on Graph Neural Networks (GNNs) for the MCNF problem which uses distinctly parametrized message functions along each link, akin to a relational model where all edge types are unique. We show that our proposed method yields substantial gains over existing graph learning methods that constrain the routing unnecessarily. We extensively evaluate the proposed approach by means of an Internet routing case study using 17 Service Provider topologies and two flow routing schemes. We find that, in many networks, an MLP is competitive with a generic GNN that does not use our mechanism. Furthermore, we shed some light on the relationship between graph structure and the difficulty of data-driven routing of flows, an aspect that has not been considered in the existing work in the area.
Dynamic Network Reconfiguration for Entropy Maximization using Deep Reinforcement Learning
May 26, 2022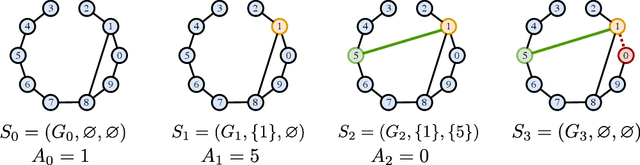
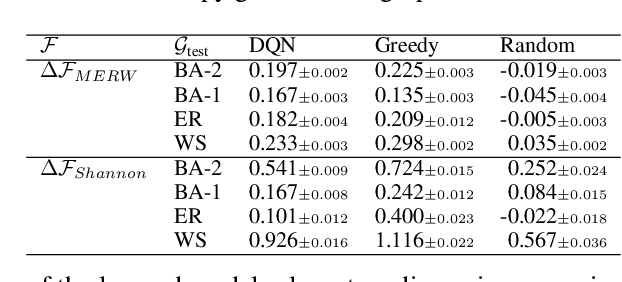


A key problem in network theory is how to reconfigure a graph in order to optimize a quantifiable objective. Given the ubiquity of networked systems, such work has broad practical applications in a variety of situations, ranging from drug and material design to telecommunications. The large decision space of possible reconfigurations, however, makes this problem computationally intensive. In this paper, we cast the problem of network rewiring for optimizing a specified structural property as a Markov Decision Process (MDP), in which a decision-maker is given a budget of modifications that are performed sequentially. We then propose a general approach based on the Deep Q-Network (DQN) algorithm and graph neural networks (GNNs) that can efficiently learn strategies for rewiring networks. We then discuss a cybersecurity case study, i.e., an application to the computer network reconfiguration problem for intrusion protection. In a typical scenario, an attacker might have a (partial) map of the system they plan to penetrate; if the network is effectively "scrambled", they would not be able to navigate it since their prior knowledge would become obsolete. This can be viewed as an entropy maximization problem, in which the goal is to increase the surprise of the network. Indeed, entropy acts as a proxy measurement of the difficulty of navigating the network topology. We demonstrate the general ability of the proposed method to obtain better entropy gains than random rewiring on synthetic and real-world graphs while being computationally inexpensive, as well as being able to generalize to larger graphs than those seen during training. Simulations of attack scenarios confirm the effectiveness of the learned rewiring strategies.
Trust-based Consensus in Multi-Agent Reinforcement Learning Systems
May 25, 2022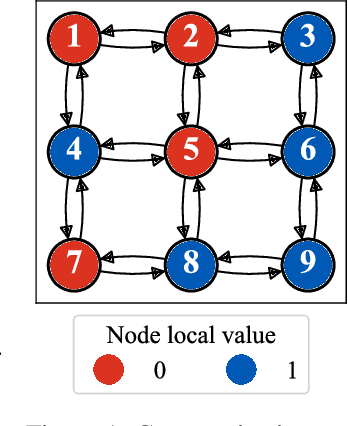

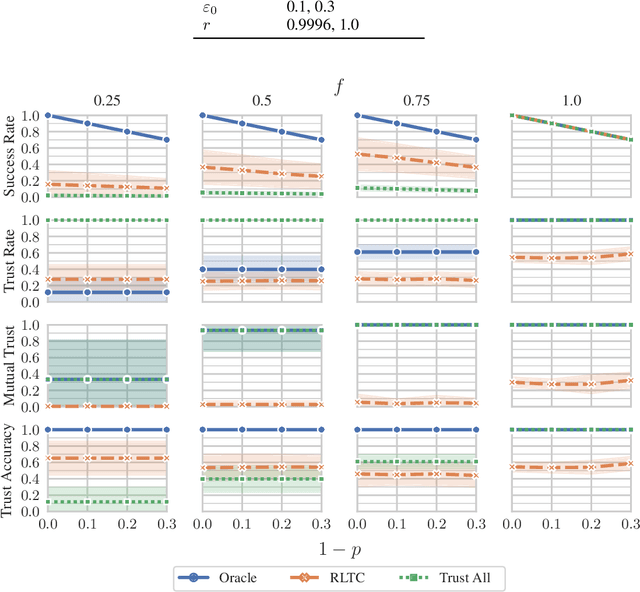
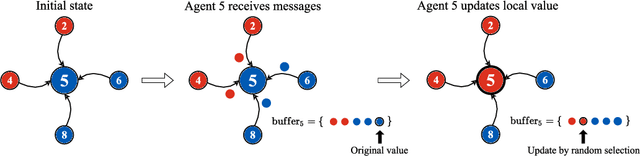
An often neglected issue in multi-agent reinforcement learning (MARL) is the potential presence of unreliable agents in the environment whose deviations from expected behavior can prevent a system from accomplishing its intended tasks. In particular, consensus is a fundamental underpinning problem of cooperative distributed multi-agent systems. Consensus requires different agents, situated in a decentralized communication network, to reach an agreement out of a set of initial proposals that they put forward. Learning-based agents should adopt a protocol that allows them to reach consensus despite having one or more unreliable agents in the system. This paper investigates the problem of unreliable agents in MARL, considering consensus as case study. Echoing established results in the distributed systems literature, our experiments show that even a moderate fraction of such agents can greatly impact the ability of reaching consensus in a networked environment. We propose Reinforcement Learning-based Trusted Consensus (RLTC), a decentralized trust mechanism, in which agents can independently decide which neighbors to communicate with. We empirically demonstrate that our trust mechanism is able to deal with unreliable agents effectively, as evidenced by higher consensus success rates.