 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROPE: A Novel Method for Real-Time Phase Estimation of Complex Biological Rhythms
Sep 05, 2025Accurate phase estimation -- the process of assigning phase values between $0$ and $2\pi$ to repetitive or periodic signals -- is a cornerstone in the analysis of oscillatory signals across diverse fields, from neuroscience to robotics, where it is fundamental, e.g., to understanding coordination in neural networks, cardiorespiratory coupling, and human-robot interaction. However, existing methods are often limited to offline processing and/or constrained to one-dimensional signals. In this paper, we introduce ROPE, which, to the best of our knowledge, is the first phase-estimation algorithm capable of (i) handling signals of arbitrary dimension and (ii) operating in real-time, with minimal error. ROPE identifies repetitions within the signal to segment it into (pseudo-)periods and assigns phase values by performing efficient, tractable searches over previous signal segments. We extensively validate the algorithm on a variety of signal types, including trajectories from chaotic dynamical systems, human motion-capture data, and electrocardiographic recordings. Our results demonstrate that ROPE is robust against noise and signal drift, and achieves significantly superior performance compared to state-of-the-art phase estimation methods. This advancement enables real-time analysis of complex biological rhythms, opening new pathways, for example, for early diagnosis of pathological rhythm disruptions and developing rhythm-based therapeutic interventions in neurological and cardiovascular disorders.
Hierarchical Policy-Gradient Reinforcement Learning for Multi-Agent Shepherding Control of Non-Cohesive Targets
Apr 03, 2025We propose a decentralized reinforcement learning solution for multi-agent shepherding of non-cohesive targets using policy-gradient methods. Our architecture integrates target-selection with target-driving through Proximal Policy Optimization, overcoming discrete-action constraints of previous Deep Q-Network approaches and enabling smoother agent trajectories. This model-free framework effectively solves the shepherding problem without prior dynamics knowledge. Experiments demonstrate our method's effectiveness and scalability with increased target numbers and limited sensing capabilities.
Data-driven architecture to encode information in the kinematics of robots and artificial avatars
Mar 11, 2024


We present a data-driven control architecture for modifying the kinematics of robots and artificial avatars to encode specific information such as the presence or not of an emotion in the movements of an avatar or robot driven by a human operator. We validate our approach on an experimental dataset obtained during the reach-to-grasp phase of a pick-and-place task.
In vivo learning-based control of microbial populations density in bioreactors
Dec 15, 2023



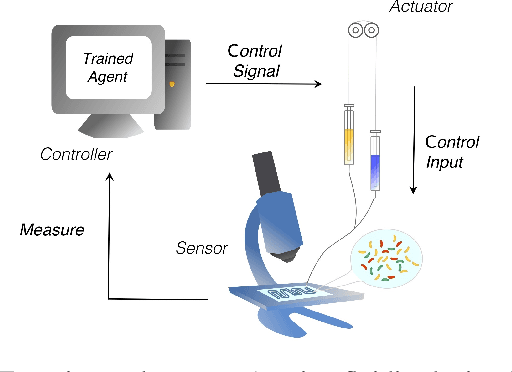
A key problem toward the use of microorganisms as bio-factories is reaching and maintaining cellular communities at a desired density and composition so that they can efficiently convert their biomass into useful compounds. Promising technological platforms for the real time, scalable control of cellular density are bioreactors. In this work, we developed a learning-based strategy to expand the toolbox of available control algorithms capable of regulating the density of a \textit{single} bacterial population in bioreactors. Specifically, we used a sim-to-real paradigm, where a simple mathematical model, calibrated using a few data, was adopted to generate synthetic data for the training of the controller. The resulting policy was then exhaustively tested in vivo using a low-cost bioreactor known as Chi.Bio, assessing performance and robustness. In addition, we compared the performance with more traditional controllers (namely, a PI and an MPC), confirming that the learning-based controller exhibits similar performance in vivo. Our work showcases the viability of learning-based strategies for the control of cellular density in bioreactors, making a step forward toward their use for the control of the composition of microbial consortia.
Guaranteeing Control Requirements via Reward Shaping in Reinforcement Learning
Nov 16, 2023



In addressing control problems such as regulation and tracking through reinforcement learning, it is often required to guarantee that the acquired policy meets essential performance and stability criteria such as a desired settling time and steady-state error prior to deployment. Motivated by this necessity, we present a set of results and a systematic reward shaping procedure that (i) ensures the optimal policy generates trajectories that align with specified control requirements and (ii) allows to assess whether any given policy satisfies them. We validate our approach through comprehensive numerical experiments conducted in two representative environments from OpenAI Gym: the Inverted Pendulum swing-up problem and the Lunar Lander. Utilizing both tabular and deep reinforcement learning methods, our experiments consistently affirm the efficacy of our proposed framework, highlighting its effectiveness in ensuring policy adherence to the prescribed control requirements.
CT-DQN: Control-Tutored Deep Reinforcement Learning
Dec 02, 2022One of the major challenges in Deep Reinforcement Learning for control is the need for extensive training to learn the policy. Motivated by this, we present the design of the Control-Tutored Deep Q-Networks (CT-DQN) algorithm, a Deep Reinforcement Learning algorithm that leverages a control tutor, i.e., an exogenous control law, to reduce learning time. The tutor can be designed using an approximate model of the system, without any assumption about the knowledge of the system's dynamics. There is no expectation that it will be able to achieve the control objective if used stand-alone. During learning, the tutor occasionally suggests an action, thus partially guiding exploration. We validate our approach on three scenarios from OpenAI Gym: the inverted pendulum, lunar lander, and car racing. We demonstrate that CT-DQN is able to achieve better or equivalent data efficiency with respect to the classic function approximation solutions.
External control of a genetic toggle switch via Reinforcement Learning
Apr 11, 2022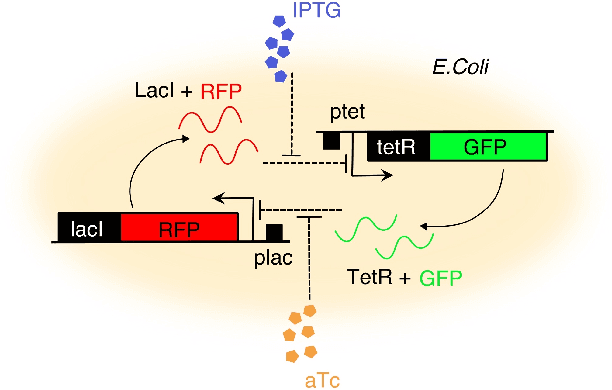
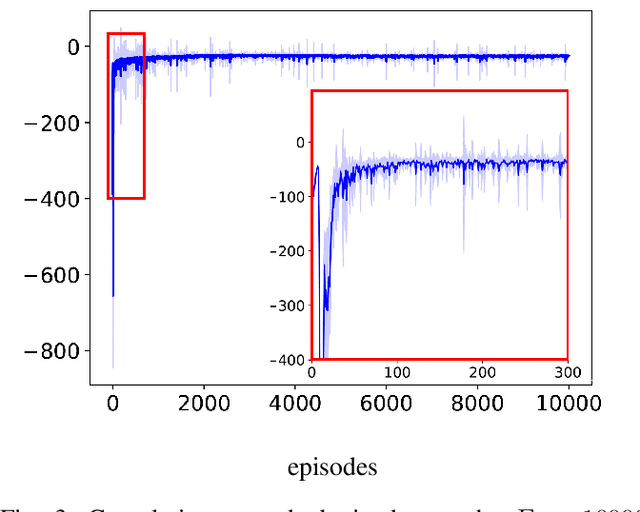
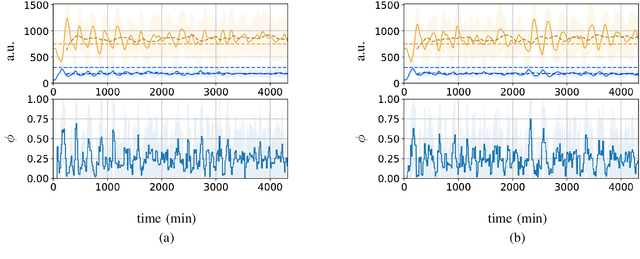
We investigate the problem of using a learning-based strategy to stabilize a synthetic toggle switch via an external control approach. To overcome the data efficiency problem that would render the algorithm unfeasible for practical use in synthetic biology, we adopt a sim-to-real paradigm where the policy is learnt via training on a simplified model of the toggle switch and it is then subsequently exploited to control a more realistic model of the switch parameterized from in-vivo experiments. Our in-silico experiments confirm the viability of the approach suggesting its potential use for in-vivo control implementations.
Tutoring Reinforcement Learning via Feedback Control
Dec 12, 2020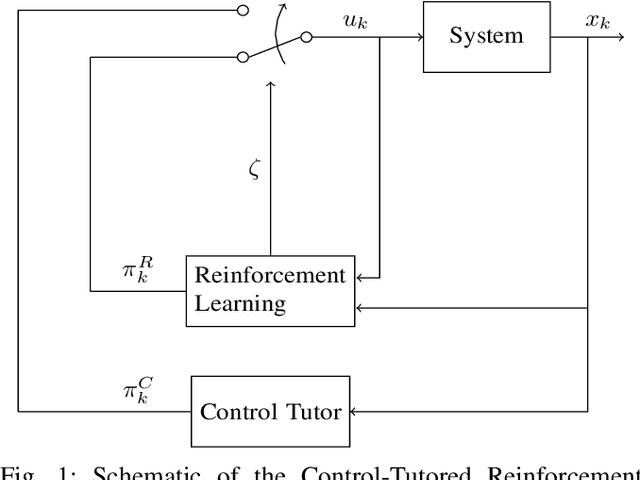
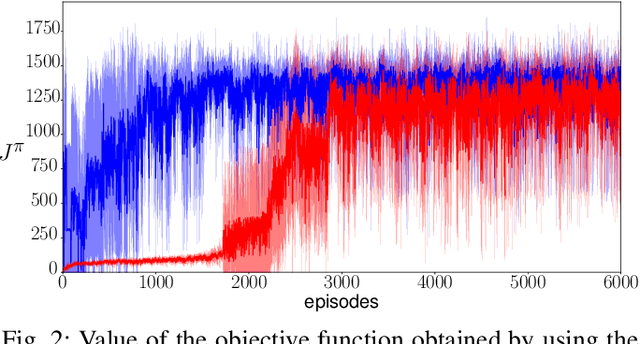
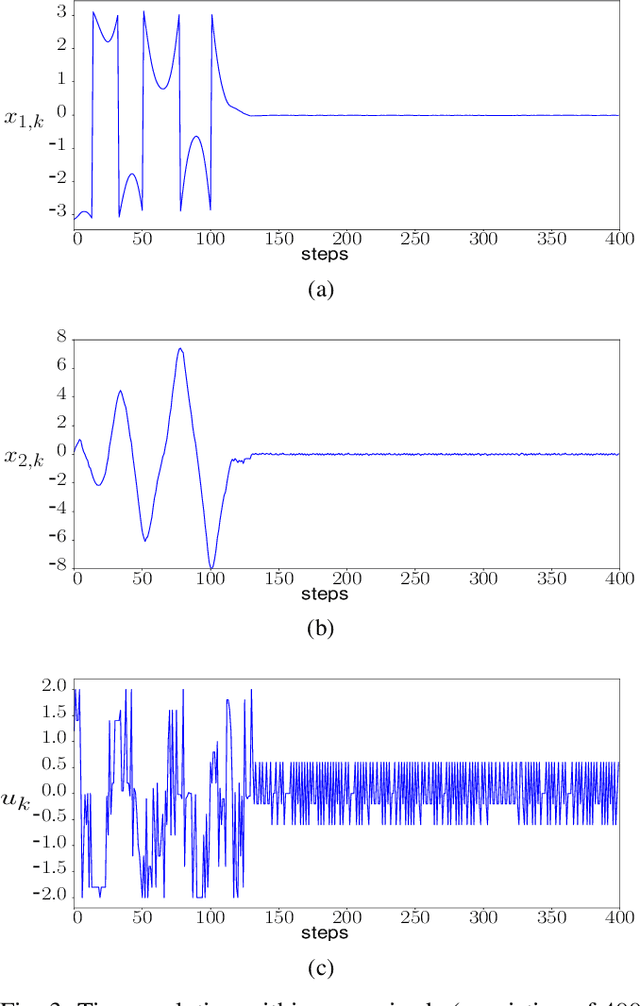
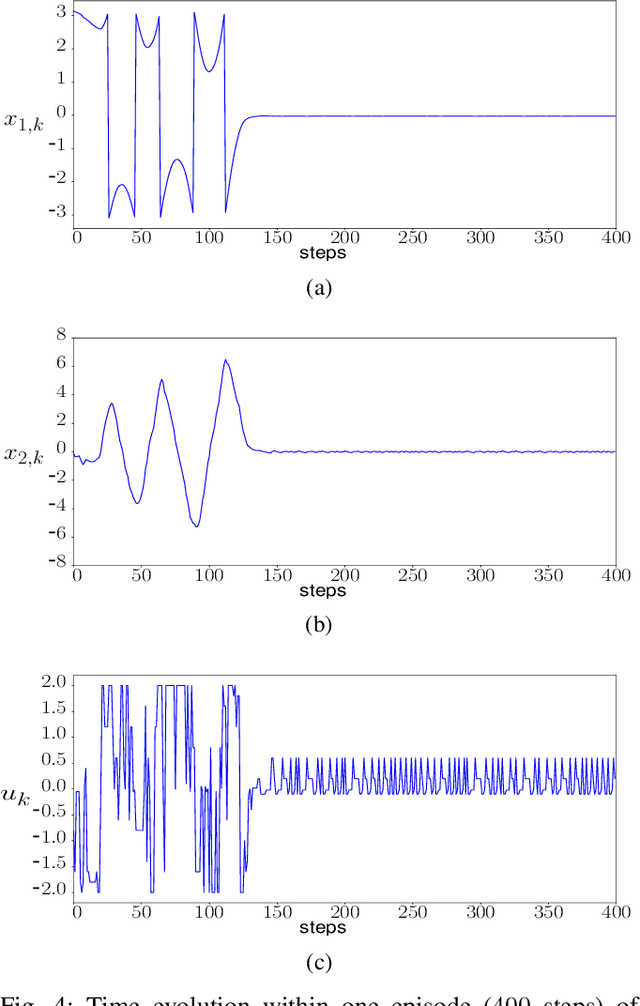
We introduce a control-tutored reinforcement learning (CTRL) algorithm. The idea is to enhance tabular learning algorithms by means of a control strategy with limited knowledge of the system model. By tutoring the learning process, the learning rate can be substantially reduced. We use the classical problem of stabilizing an inverted pendulum as a benchmark to numerically illustrate the advantages and disadvantages of the approach.
Control-Tutored Reinforcement Learning
Dec 12, 2019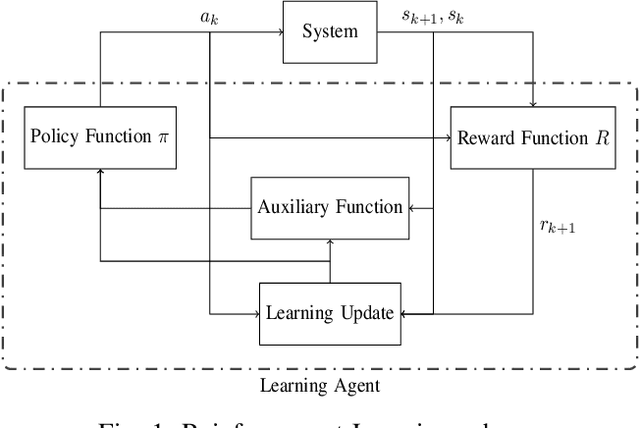
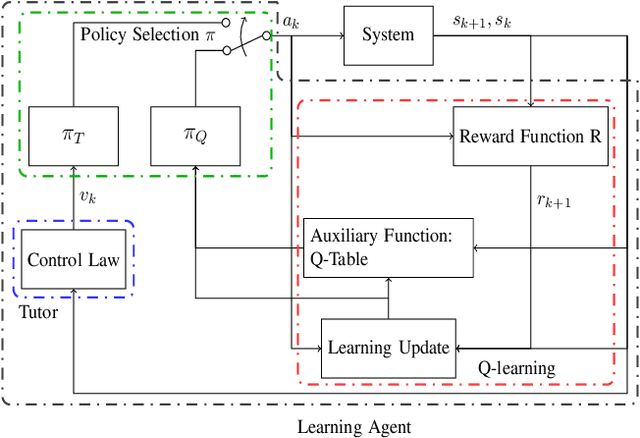
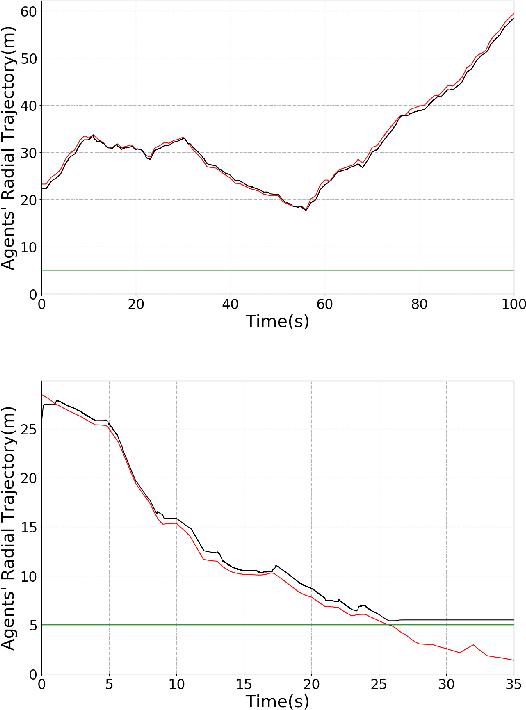
We introduce a control-tutored reinforcement learning (CTRL) algorithm. The idea is to enhance tabular learning algorithms so as to improve the exploration of the state-space, and substantially reduce learning times by leveraging some limited knowledge of the plant encoded into a tutoring model-based control strategy. We illustrate the benefits of our novel approach and its effectiveness by using the problem of controlling one or more agents to herd and contain within a goal region a set of target free-roving agents in the plane.
Control-Tutored Reinforcement Learning: an application to the Herding Problem
Nov 27, 2019
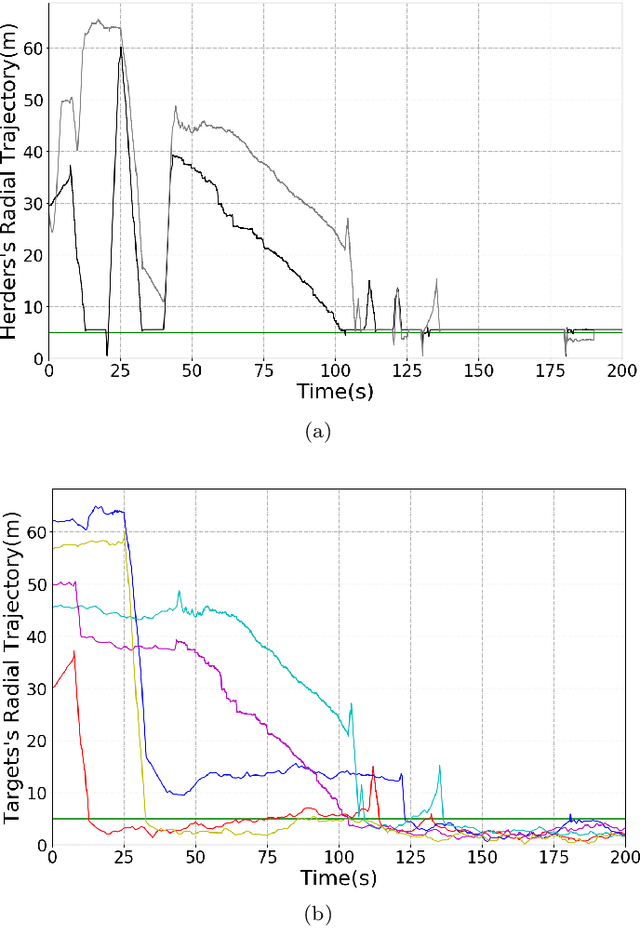
In this extended abstract we introduce a novel control-tutored Q-learning approach (CTQL) as part of the ongoing effort in developing model-based and safe RL for continuous state spaces. We validate our approach by applying it to a challenging multi-agent herding control problem.