 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven architecture to encode information in the kinematics of robots and artificial avatars
Mar 11, 2024
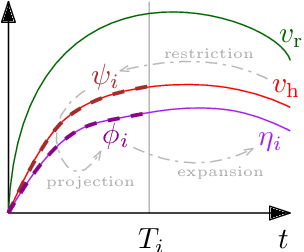


We present a data-driven control architecture for modifying the kinematics of robots and artificial avatars to encode specific information such as the presence or not of an emotion in the movements of an avatar or robot driven by a human operator. We validate our approach on an experimental dataset obtained during the reach-to-grasp phase of a pick-and-place task.
Awareness in robotics: An early perspective from the viewpoint of the EIC Pathfinder Challenge "Awareness Inside''
Feb 14, 2024Consciousness has been historically a heavily debated topic in engineering, science, and philosophy. On the contrary, awareness had less success in raising the interest of scholars in the past. However, things are changing as more and more researchers are getting interested in answering questions concerning what awareness is and how it can be artificially generated. The landscape is rapidly evolving, with multiple voices and interpretations of the concept being conceived and techniques being developed. The goal of this paper is to summarize and discuss the ones among these voices connected with projects funded by the EIC Pathfinder Challenge called ``Awareness Inside'', a nonrecurring call for proposals within Horizon Europe designed specifically for fostering research on natural and synthetic awareness. In this perspective, we dedicate special attention to challenges and promises of applying synthetic awareness in robotics, as the development of mature techniques in this new field is expected to have a special impact on generating more capable and trustworthy embodied systems.
Maximising Coefficiency of Human-Robot Handovers through Reinforcement Learning
Jun 12, 2023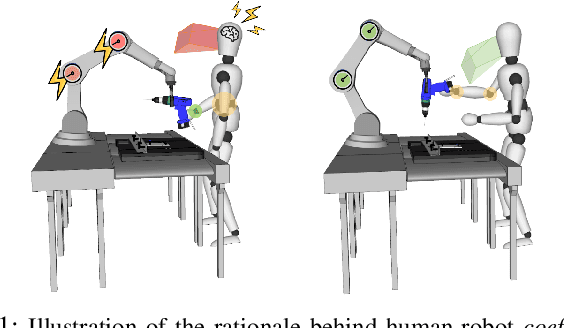
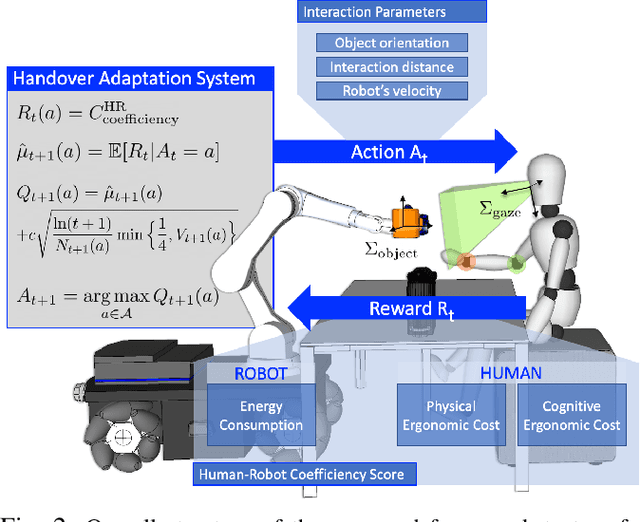
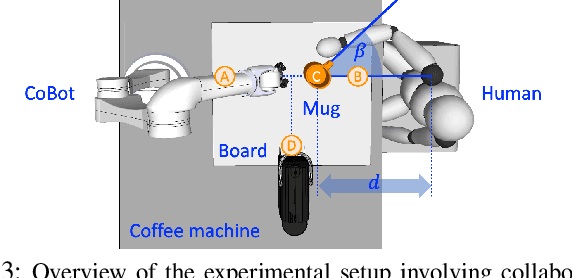
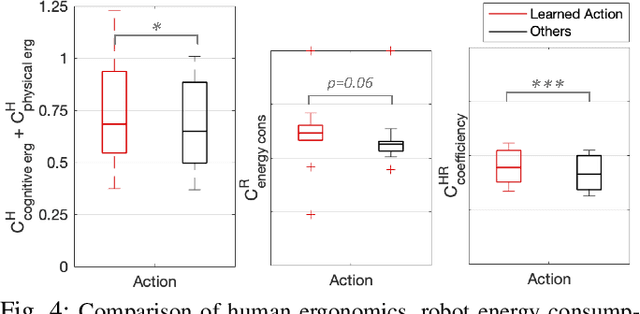
Handing objects to humans is an essential capability for collaborative robots. Previous research works on human-robot handovers focus on facilitating the performance of the human partner and possibly minimising the physical effort needed to grasp the object. However, altruistic robot behaviours may result in protracted and awkward robot motions, contributing to unpleasant sensations by the human partner and affecting perceived safety and social acceptance. This paper investigates whether transferring the cognitive science principle that "humans act coefficiently as a group" (i.e. simultaneously maximising the benefits of all agents involved) to human-robot cooperative tasks promotes a more seamless and natural interaction. Human-robot coefficiency is first modelled by identifying implicit indicators of human comfort and discomfort as well as calculating the robot energy consumption in performing the desired trajectory. We then present a reinforcement learning approach that uses the human-robot coefficiency score as reward to adapt and learn online the combination of robot interaction parameters that maximises such coefficiency. Results proved that by acting coefficiently the robot could meet the individual preferences of most subjects involved in the experiments, improve the human perceived comfort, and foster trust in the robotic partner.
Predicting Human Intentions from Motion Only: A 2D+3D Fusion Approach
Sep 06, 2017


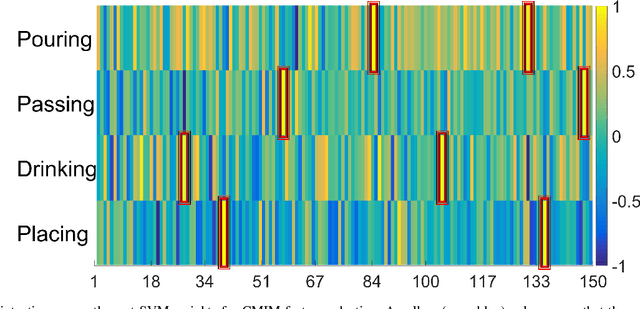
In this paper, we address the new problem of the prediction of human intents. There is neuro-psychological evidence that actions performed by humans are anticipated by peculiar motor acts which are discriminant of the type of action going to be performed afterwards. In other words, an actual intent can be forecast by looking at the kinematics of the immediately preceding movement. To prove it in a computational and quantitative manner, we devise a new experimental setup where, without using contextual information, we predict human intents all originating from the same motor act. We posit the problem as a classification task and we introduce a new multi-modal dataset consisting of a set of motion capture marker 3D data and 2D video sequences, where, by only analysing very similar movements in both training and test phases, we are able to predict the underlying intent, i.e., the future, never observed action. We also present an extensive experimental evaluation as a baseline, customizing state-of-the-art techniques for either 3D and 2D data analysis. Realizing that video processing methods lead to inferior performance but show complementary information with respect to 3D data sequences, we developed a 2D+3D fusion analysis where we achieve better classification accuracies, attesting the superiority of the multimodal approach for the context-free prediction of human intents.
What Will I Do Next? The Intention from Motion Experiment
Aug 03, 2017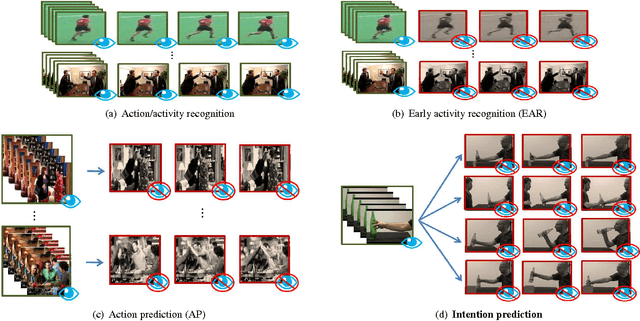
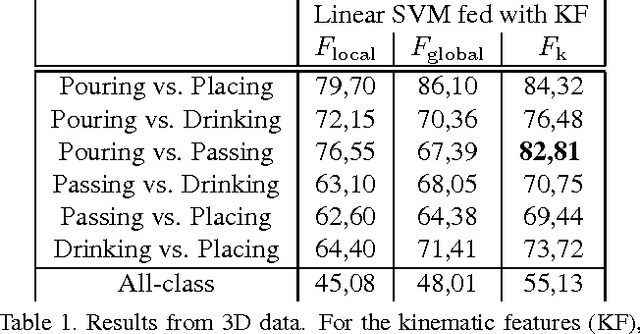
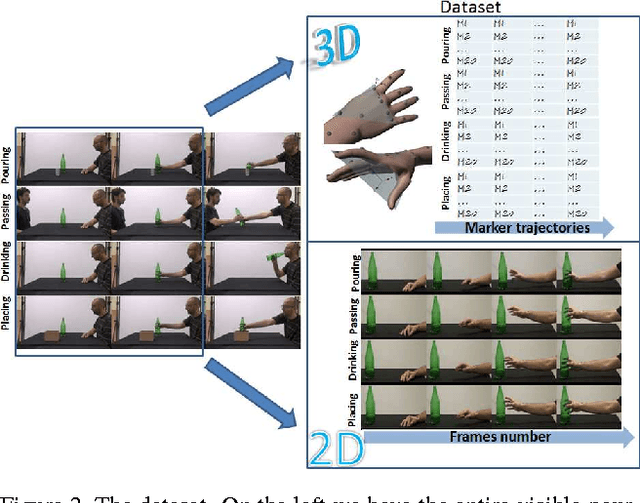

In computer vision, video-based approaches have been widely explored for the early classification and the prediction of actions or activities. However, it remains unclear whether this modality (as compared to 3D kinematics) can still be reliable for the prediction of human intentions, defined as the overarching goal embedded in an action sequence. Since the same action can be performed with different intentions, this problem is more challenging but yet affordable as proved by quantitative cognitive studies which exploit the 3D kinematics acquired through motion capture systems. In this paper, we bridge cognitive and computer vision studies, by demonstrating the effectiveness of video-based approaches for the prediction of human intentions. Precisely, we propose Intention from Motion, a new paradigm where, without using any contextual information, we consider instantaneous grasping motor acts involving a bottle in order to forecast why the bottle itself has been reached (to pass it or to place in a box, or to pour or to drink the liquid inside). We process only the grasping onsets casting intention prediction as a classification framework. Leveraging on our multimodal acquisition (3D motion capture data and 2D optical videos), we compare the most commonly used 3D descriptors from cognitive studies with state-of-the-art video-based techniques. Since the two analyses achieve an equivalent performance, we demonstrate that computer vision tools are effective in capturing the kinematics and facing the cognitive problem of human intention prediction.