 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Human Action Recognition with Skeletal Graph Laplacian and Self-Supervised Viewpoints Invariance
Apr 21, 2022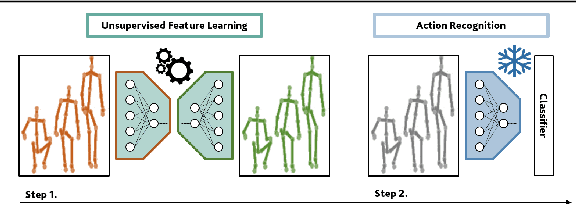
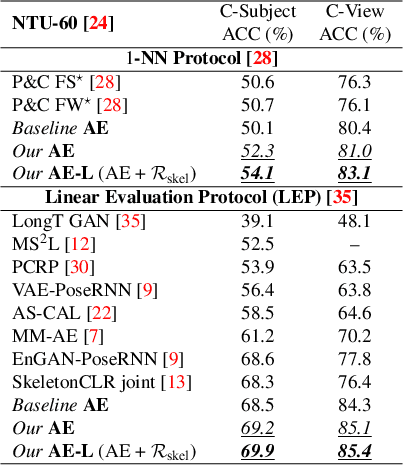
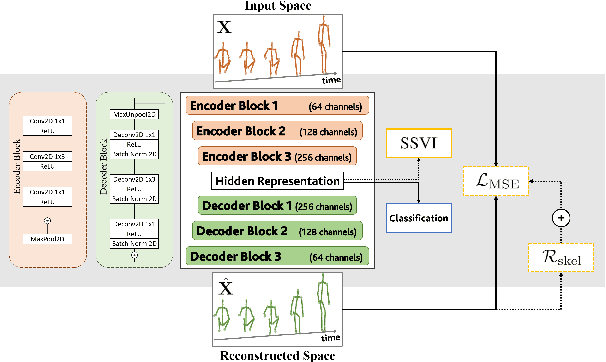

This paper presents a novel end-to-end method for the problem of skeleton-based unsupervised human action recognition. We propose a new architecture with a convolutional autoencoder that uses graph Laplacian regularization to model the skeletal geometry across the temporal dynamics of actions. Our approach is robust towards viewpoint variations by including a self-supervised gradient reverse layer that ensures generalization across camera views. The proposed method is validated on NTU-60 and NTU-120 large-scale datasets in which it outperforms all prior unsupervised skeleton-based approaches on the cross-subject, cross-view, and cross-setup protocols. Although unsupervised, our learnable representation allows our method even to surpass a few supervised skeleton-based action recognition methods. The code is available in: www.github.com/IIT-PAVIS/UHAR_Skeletal_Laplacian
Semantically Grounded Visual Embeddings for Zero-Shot Learning
Jan 03, 2022

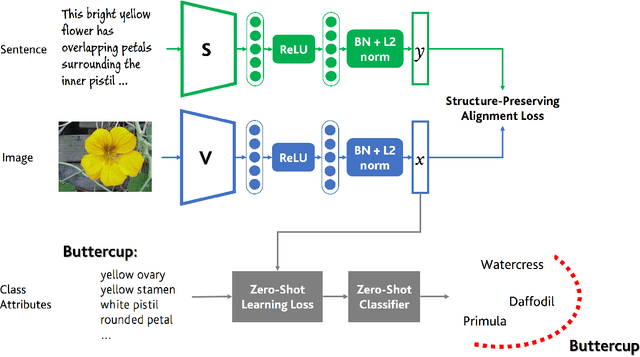
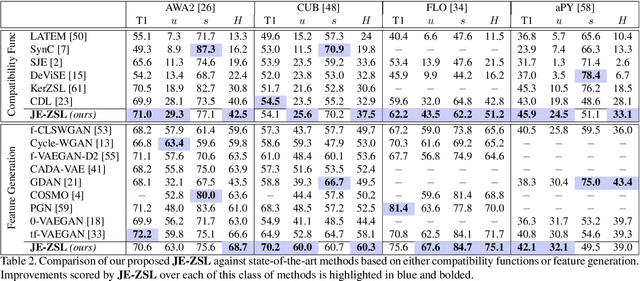
Zero-shot learning methods rely on fixed visual and semantic embeddings, extracted from independent vision and language models, both pre-trained for other large-scale tasks. This is a weakness of current zero-shot learning frameworks as such disjoint embeddings fail to adequately associate visual and textual information to their shared semantic content. Therefore, we propose to learn semantically grounded and enriched visual information by computing a joint image and text model with a two-stream network on a proxy task. To improve this alignment between image and textual representations, provided by attributes, we leverage ancillary captions to provide grounded semantic information. Our method, dubbed joint embeddings for zero-shot learning is evaluated on several benchmark datasets, improving the performance of existing state-of-the-art methods in both standard ($+1.6$\% on aPY, $+2.6\%$ on FLO) and generalized ($+2.1\%$ on AWA$2$, $+2.2\%$ on CUB) zero-shot recognition.
Learning without Seeing nor Knowing: Towards Open Zero-Shot Learning
Mar 23, 2021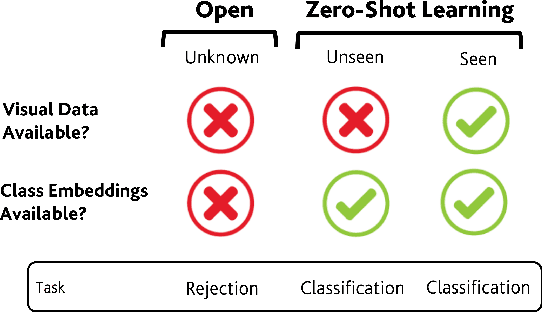
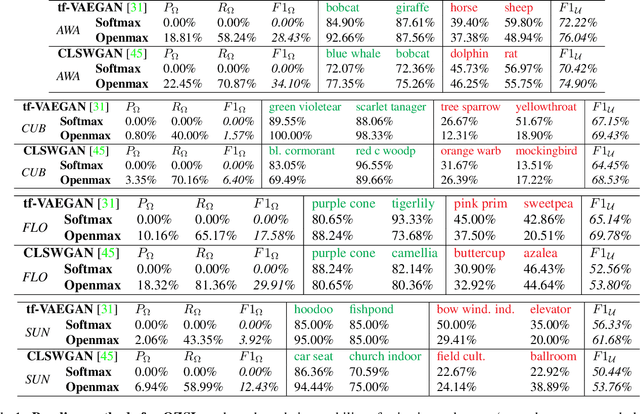
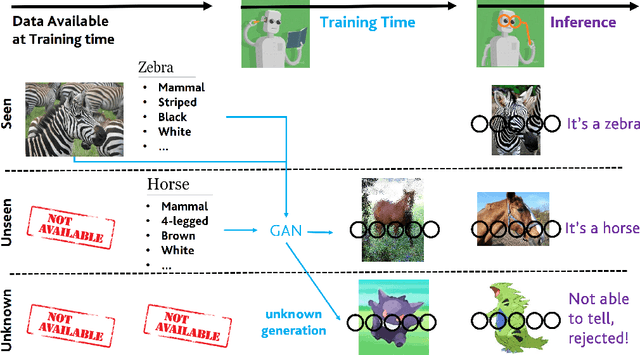
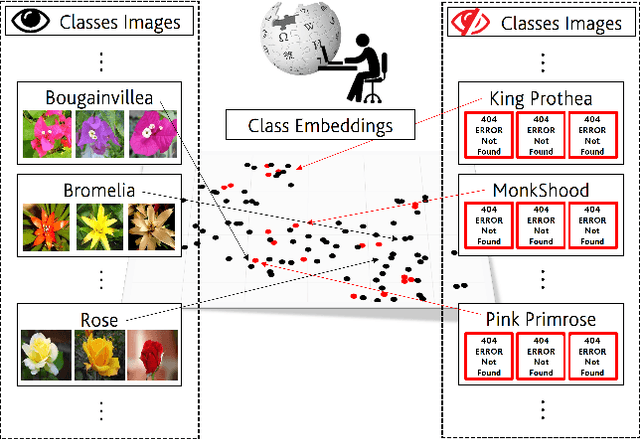
In Generalized Zero-Shot Learning (GZSL), unseen categories (for which no visual data are available at training time) can be predicted by leveraging their class embeddings (e.g., a list of attributes describing them) together with a complementary pool of seen classes (paired with both visual data and class embeddings). Despite GZSL is arguably challenging, we posit that knowing in advance the class embeddings, especially for unseen categories, is an actual limit of the applicability of GZSL towards real-world scenarios. To relax this assumption, we propose Open Zero-Shot Learning (OZSL) to extend GZSL towards the open-world settings. We formalize OZSL as the problem of recognizing seen and unseen classes (as in GZSL) while also rejecting instances from unknown categories, for which neither visual data nor class embeddings are provided. We formalize the OZSL problem introducing evaluation protocols, error metrics and benchmark datasets. We also suggest to tackle the OZSL problem by proposing the idea of performing unknown feature generation (instead of only unseen features generation as done in GZSL). We achieve this by optimizing a generative process to sample unknown class embeddings as complementary to the seen and the unseen. We intend these results to be the ground to foster future research, extending the standard closed-world zero-shot learning (GZSL) with the novel open-world counterpart (OZSL).
Classifier Crafting: Turn Your ConvNet into a Zero-Shot Learner!
Mar 20, 2021
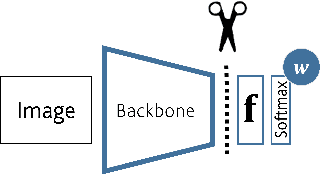
In Zero-shot learning (ZSL), we classify unseen categories using textual descriptions about their expected appearance when observed (class embeddings) and a disjoint pool of seen classes, for which annotated visual data are accessible. We tackle ZSL by casting a "vanilla" convolutional neural network (e.g. AlexNet, ResNet-101, DenseNet-201 or DarkNet-53) into a zero-shot learner. We do so by crafting the softmax classifier: we freeze its weights using fixed seen classification rules, either semantic (seen class embeddings) or visual (seen class prototypes). Then, we learn a data-driven and ZSL-tailored feature representation on seen classes only to match these fixed classification rules. Given that the latter seamlessly generalize towards unseen classes, while requiring not actual unseen data to be computed, we can perform ZSL inference by augmenting the pool of classification rules at test time while keeping the very same representation we learnt: nowhere re-training or fine-tuning on unseen data is performed. The combination of semantic and visual crafting (by simply averaging softmax scores) improves prior state-of-the-art methods in benchmark datasets for standard, inductive ZSL. After rebalancing predictions to better handle the joint inference over seen and unseen classes, we outperform prior generalized, inductive ZSL methods as well. Also, we gain interpretability at no additional cost, by using neural attention methods (e.g., grad-CAM) as they are. Code will be made publicly available.
Transductive Zero-Shot Learning by Decoupled Feature Generation
Feb 23, 2021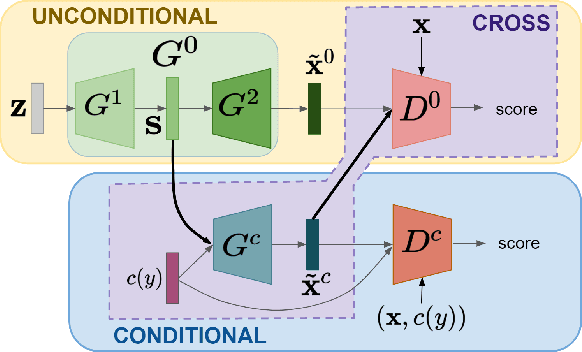
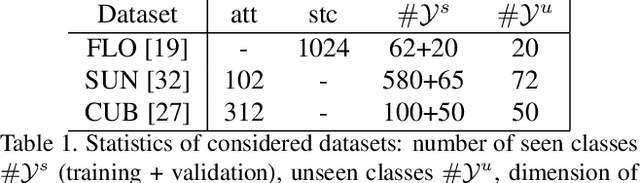
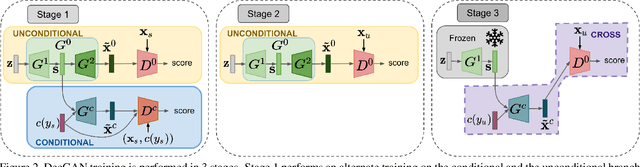
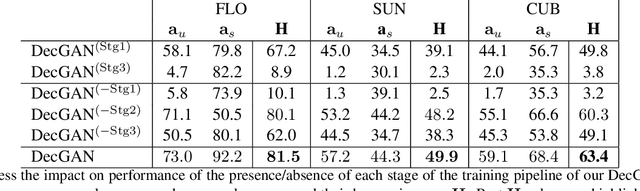
In this paper, we address zero-shot learning (ZSL), the problem of recognizing categories for which no labeled visual data are available during training. We focus on the transductive setting, in which unlabelled visual data from unseen classes is available. State-of-the-art paradigms in ZSL typically exploit generative adversarial networks to synthesize visual features from semantic attributes. We posit that the main limitation of these approaches is to adopt a single model to face two problems: 1) generating realistic visual features, and 2) translating semantic attributes into visual cues. Differently, we propose to decouple such tasks, solving them separately. In particular, we train an unconditional generator to solely capture the complexity of the distribution of visual data and we subsequently pair it with a conditional generator devoted to enrich the prior knowledge of the data distribution with the semantic content of the class embeddings. We present a detailed ablation study to dissect the effect of our proposed decoupling approach, while demonstrating its superiority over the related state-of-the-art.
Subspace Clustering for Action Recognition with Covariance Representations and Temporal Pruning
Jun 21, 2020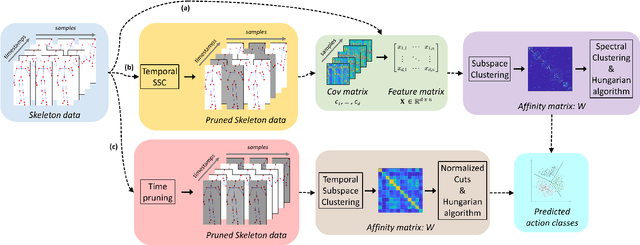
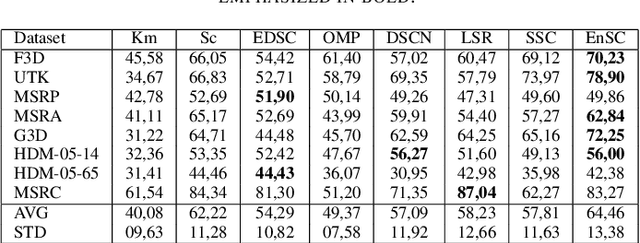
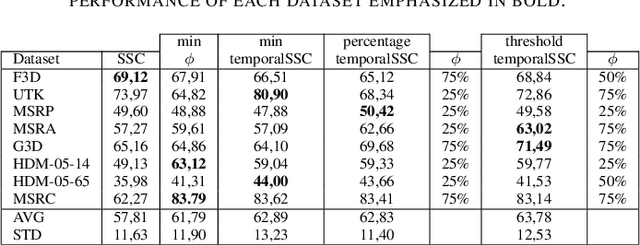
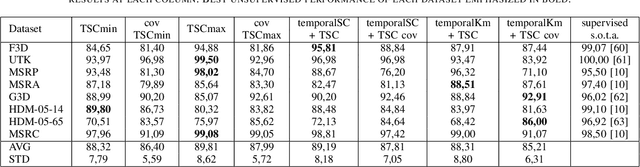
This paper tackles the problem of human action recognition, defined as classifying which action is displayed in a trimmed sequence, from skeletal data. Albeit state-of-the-art approaches designed for this application are all supervised, in this paper we pursue a more challenging direction: Solving the problem with unsupervised learning. To this end, we propose a novel subspace clustering method, which exploits covariance matrix to enhance the action's discriminability and a timestamp pruning approach that allow us to better handle the temporal dimension of the data. Through a broad experimental validation, we show that our computational pipeline surpasses existing unsupervised approaches but also can result in favorable performances as compared to supervised methods.
Learning Unbiased Representations via Mutual Information Backpropagation
Mar 13, 2020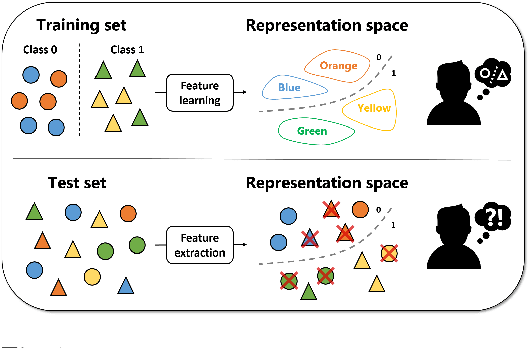
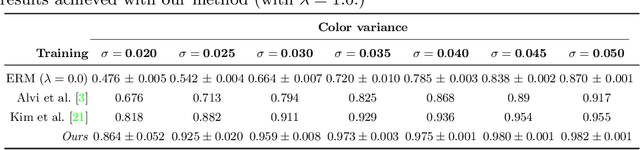
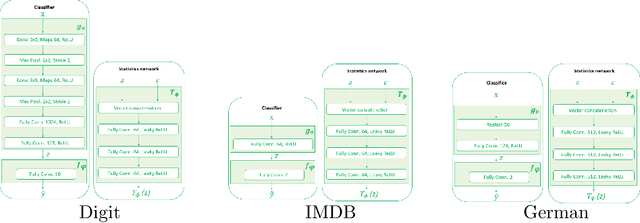
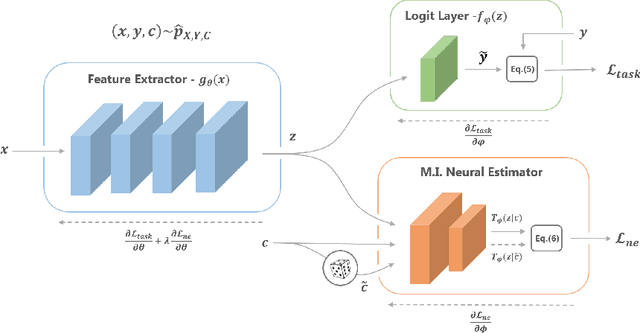
We are interested in learning data-driven representations that can generalize well, even when trained on inherently biased data. In particular, we face the case where some attributes (bias) of the data, if learned by the model, can severely compromise its generalization properties. We tackle this problem through the lens of information theory, leveraging recent findings for a differentiable estimation of mutual information. We propose a novel end-to-end optimization strategy, which simultaneously estimates and minimizes the mutual information between the learned representation and the data attributes. When applied on standard benchmarks, our model shows comparable or superior classification performance with respect to state-of-the-art approaches. Moreover, our method is general enough to be applicable to the problem of ``algorithmic fairness'', with competitive results.
Scalable and Compact 3D Action Recognition with Approximated RBF Kernel Machines
Nov 28, 2017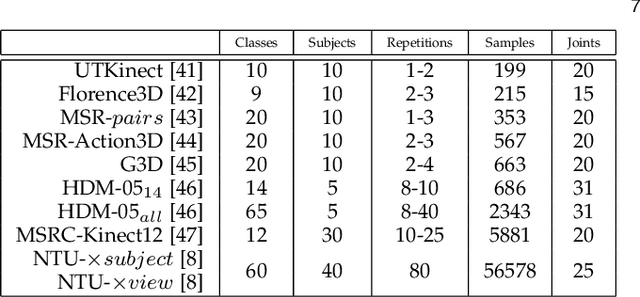
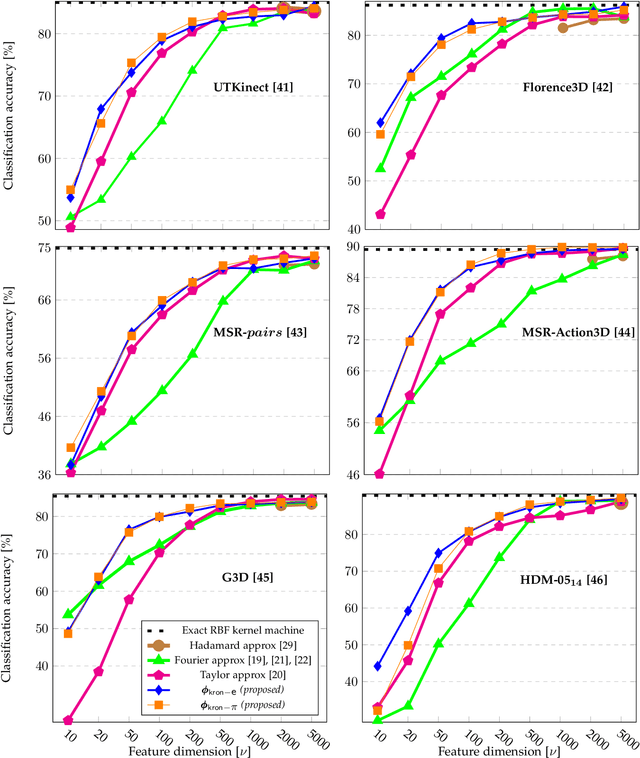
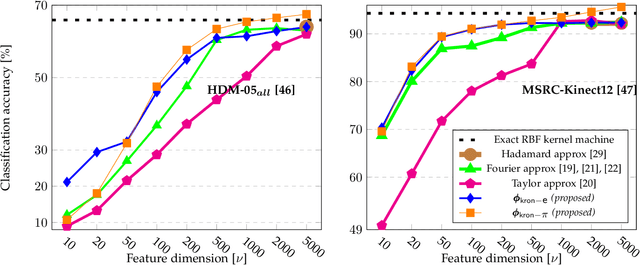

Despite the recent deep learning (DL) revolution, kernel machines still remain powerful methods for action recognition. DL has brought the use of large datasets and this is typically a problem for kernel approaches, which are not scaling up efficiently due to kernel Gram matrices. Nevertheless, kernel methods are still attractive and more generally applicable since they can equally manage different sizes of the datasets, also in cases where DL techniques show some limitations. This work investigates these issues by proposing an explicit approximated representation that, together with a linear model, is an equivalent, yet scalable, implementation of a kernel machine. Our approximation is directly inspired by the exact feature map that is induced by an RBF Gaussian kernel but, unlike the latter, it is finite dimensional and very compact. We justify the soundness of our idea with a theoretical analysis which proves the unbiasedness of the approximation, and provides a vanishing bound for its variance, which is shown to decrease much rapidly than in alternative methods in the literature. In a broad experimental validation, we assess the superiority of our approximation in terms of 1) ease and speed of training, 2) compactness of the model, and 3) improvements with respect to the state-of-the-art performance.
Minimal-Entropy Correlation Alignment for Unsupervised Deep Domain Adaptation
Nov 28, 2017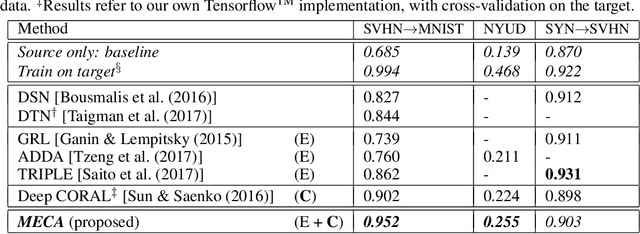
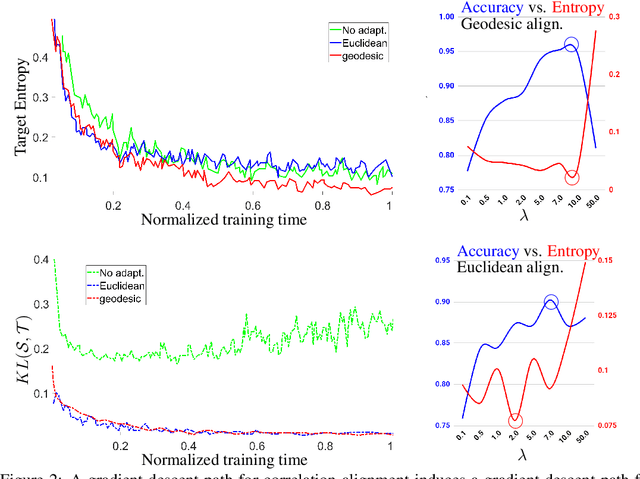

In this work, we face the problem of unsupervised domain adaptation with a novel deep learning approach which leverages on our finding that entropy minimization is induced by the optimal alignment of second order statistics between source and target domains. We formally demonstrate this hypothesis and, aiming at achieving an optimal alignment in practical cases, we adopt a more principled strategy which, differently from the current Euclidean approaches, deploys alignment along geodesics. Our pipeline can be implemented by adding to the standard classification loss (on the labeled source domain), a source-to-target regularizer that is weighted in an unsupervised and data-driven fashion. We provide extensive experiments to assess the superiority of our framework on standard domain and modality adaptation benchmarks.
Dropout as a Low-Rank Regularizer for Matrix Factorization
Oct 13, 2017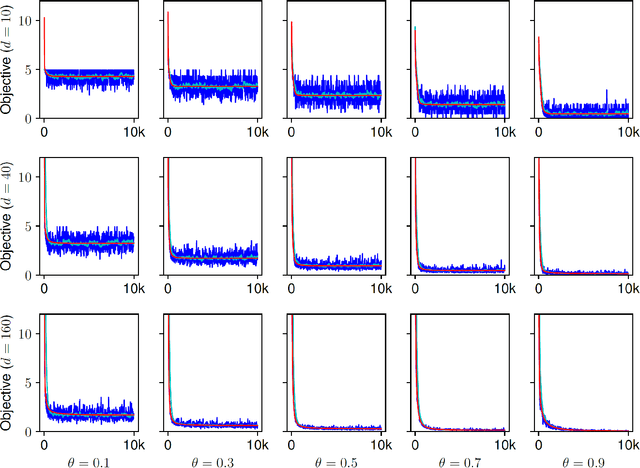
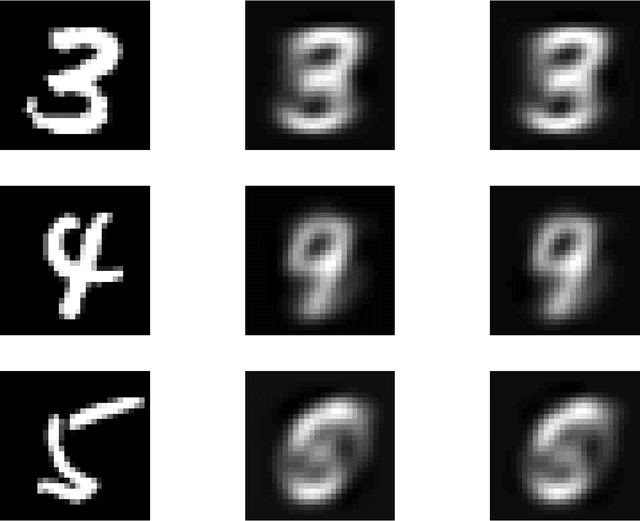
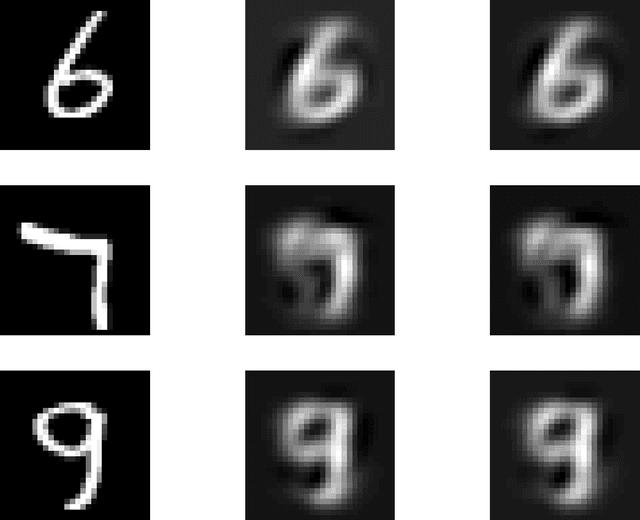
Regularization for matrix factorization (MF) and approximation problems has been carried out in many different ways. Due to its popularity in deep learning, dropout has been applied also for this class of problems. Despite its solid empirical performance, the theoretical properties of dropout as a regularizer remain quite elusive for this class of problems. In this paper, we present a theoretical analysis of dropout for MF, where Bernoulli random variables are used to drop columns of the factors. We demonstrate the equivalence between dropout and a fully deterministic model for MF in which the factors are regularized by the sum of the product of squared Euclidean norms of the columns. Additionally, we inspect the case of a variable sized factorization and we prove that dropout achieves the global minimum of a convex approximation problem with (squared) nuclear norm regularization. As a result, we conclude that dropout can be used as a low-rank regularizer with data dependent singular-value thresholding.