 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and Compact 3D Action Recognition with Approximated RBF Kernel Machines
Paper and Code
Nov 28, 2017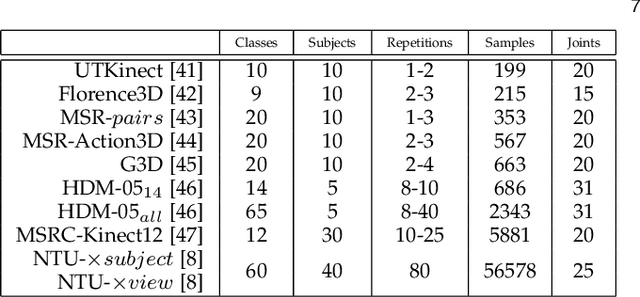
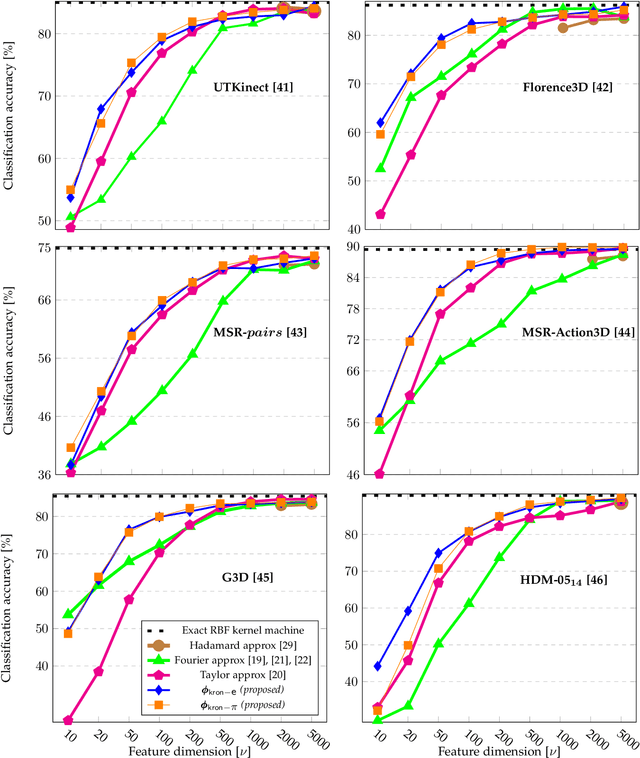
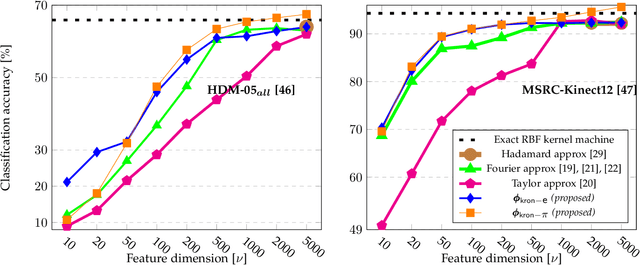

Despite the recent deep learning (DL) revolution, kernel machines still remain powerful methods for action recognition. DL has brought the use of large datasets and this is typically a problem for kernel approaches, which are not scaling up efficiently due to kernel Gram matrices. Nevertheless, kernel methods are still attractive and more generally applicable since they can equally manage different sizes of the datasets, also in cases where DL techniques show some limitations. This work investigates these issues by proposing an explicit approximated representation that, together with a linear model, is an equivalent, yet scalable, implementation of a kernel machine. Our approximation is directly inspired by the exact feature map that is induced by an RBF Gaussian kernel but, unlike the latter, it is finite dimensional and very compact. We justify the soundness of our idea with a theoretical analysis which proves the unbiasedness of the approximation, and provides a vanishing bound for its variance, which is shown to decrease much rapidly than in alternative methods in the literature. In a broad experimental validation, we assess the superiority of our approximation in terms of 1) ease and speed of training, 2) compactness of the model, and 3) improvements with respect to the state-of-the-art performance.