 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Evaluate Autonomous Behaviour in Human-Robot Interaction
Jul 08, 2025Evaluating and comparing the performance of autonomous Humanoid Robots is challenging, as success rate metrics are difficult to reproduce and fail to capture the complexity of robot movement trajectories, critical in Human-Robot Interaction and Collaboration (HRIC). To address these challenges, we propose a general evaluation framework that measures the quality of Imitation Learning (IL) methods by focusing on trajectory performance. We devise the Neural Meta Evaluator (NeME), a deep learning model trained to classify actions from robot joint trajectories. NeME serves as a meta-evaluator to compare the performance of robot control policies, enabling policy evaluation without requiring human involvement in the loop. We validate our framework on ergoCub, a humanoid robot, using teleoperation data and comparing IL methods tailored to the available platform. The experimental results indicate that our method is more aligned with the success rate obtained on the robot than baselines, offering a reproducible, systematic, and insightful means for comparing the performance of multimodal imitation learning approaches in complex HRI tasks.
ReassembleNet: Learnable Keypoints and Diffusion for 2D Fresco Reconstruction
May 29, 2025The task of reassembly is a significant challenge across multiple domains, including archaeology, genomics, and molecular docking, requiring the precise placement and orientation of elements to reconstruct an original structure. In this work, we address key limitations in state-of-the-art Deep Learning methods for reassembly, namely i) scalability; ii) multimodality; and iii) real-world applicability: beyond square or simple geometric shapes, realistic and complex erosion, or other real-world problems. We propose ReassembleNet, a method that reduces complexity by representing each input piece as a set of contour keypoints and learning to select the most informative ones by Graph Neural Networks pooling inspired techniques. ReassembleNet effectively lowers computational complexity while enabling the integration of features from multiple modalities, including both geometric and texture data. Further enhanced through pretraining on a semi-synthetic dataset. We then apply diffusion-based pose estimation to recover the original structure. We improve on prior methods by 55% and 86% for RMSE Rotation and Translation, respectively.
Directed Semi-Simplicial Learning with Applications to Brain Activity Decoding
May 23, 2025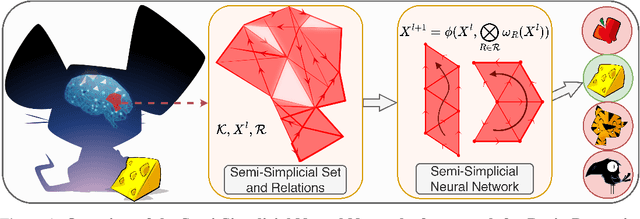
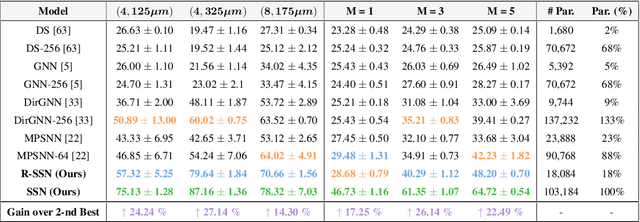
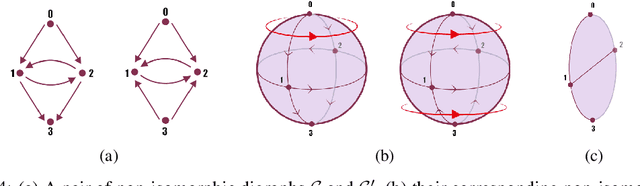
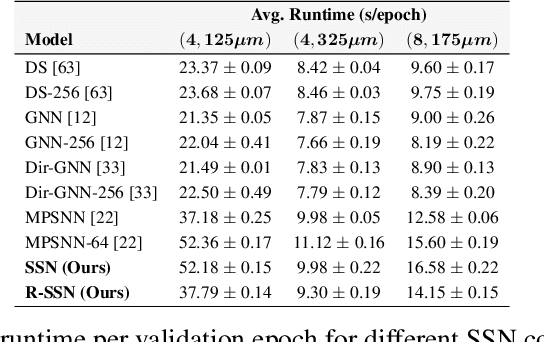
Graph Neural Networks (GNNs) excel at learning from pairwise interactions but often overlook multi-way and hierarchical relationships. Topological Deep Learning (TDL) addresses this limitation by leveraging combinatorial topological spaces. However, existing TDL models are restricted to undirected settings and fail to capture the higher-order directed patterns prevalent in many complex systems, e.g., brain networks, where such interactions are both abundant and functionally significant. To fill this gap, we introduce Semi-Simplicial Neural Networks (SSNs), a principled class of TDL models that operate on semi-simplicial sets -- combinatorial structures that encode directed higher-order motifs and their directional relationships. To enhance scalability, we propose Routing-SSNs, which dynamically select the most informative relations in a learnable manner. We prove that SSNs are strictly more expressive than standard graph and TDL models. We then introduce a new principled framework for brain dynamics representation learning, grounded in the ability of SSNs to provably recover topological descriptors shown to successfully characterize brain activity. Empirically, SSNs achieve state-of-the-art performance on brain dynamics classification tasks, outperforming the second-best model by up to 27%, and message passing GNNs by up to 50% in accuracy. Our results highlight the potential of principled topological models for learning from structured brain data, establishing a unique real-world case study for TDL. We also test SSNs on standard node classification and edge regression tasks, showing competitive performance. We will make the code and data publicly available.
Embodied Image Captioning: Self-supervised Learning Agents for Spatially Coherent Image Descriptions
Apr 11, 2025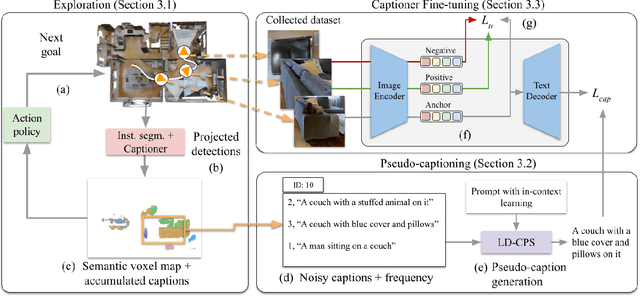
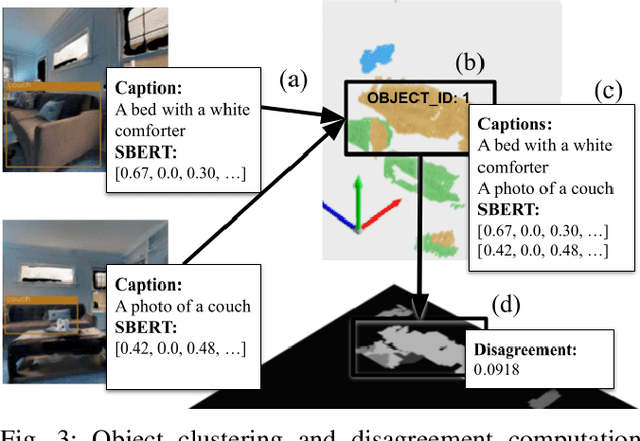
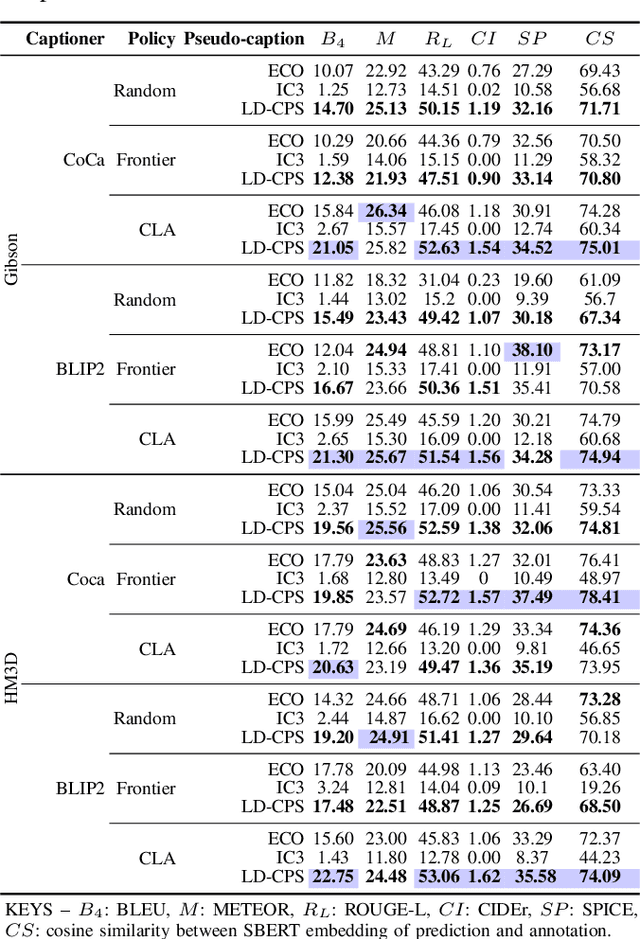

We present a self-supervised method to improve an agent's abilities in describing arbitrary objects while actively exploring a generic environment. This is a challenging problem, as current models struggle to obtain coherent image captions due to different camera viewpoints and clutter. We propose a three-phase framework to fine-tune existing captioning models that enhances caption accuracy and consistency across views via a consensus mechanism. First, an agent explores the environment, collecting noisy image-caption pairs. Then, a consistent pseudo-caption for each object instance is distilled via consensus using a large language model. Finally, these pseudo-captions are used to fine-tune an off-the-shelf captioning model, with the addition of contrastive learning. We analyse the performance of the combination of captioning models, exploration policies, pseudo-labeling methods, and fine-tuning strategies, on our manually labeled test set. Results show that a policy can be trained to mine samples with higher disagreement compared to classical baselines. Our pseudo-captioning method, in combination with all policies, has a higher semantic similarity compared to other existing methods, and fine-tuning improves caption accuracy and consistency by a significant margin. Code and test set annotations available at https://hsp-iit.github.io/embodied-captioning/
A Mutual Information Perspective on Multiple Latent Variable Generative Models for Positive View Generation
Jan 23, 2025



In image generation, Multiple Latent Variable Generative Models (MLVGMs) employ multiple latent variables to gradually shape the final images, from global characteristics to finer and local details (e.g., StyleGAN, NVAE), emerging as powerful tools for diverse applications. Yet their generative dynamics and latent variable utilization remain only empirically observed. In this work, we propose a novel framework to systematically quantify the impact of each latent variable in MLVGMs, using Mutual Information (MI) as a guiding metric. Our analysis reveals underutilized variables and can guide the use of MLVGMs in downstream applications. With this foundation, we introduce a method for generating synthetic data for Self-Supervised Contrastive Representation Learning (SSCRL). By leveraging the hierarchical and disentangled variables of MLVGMs, and guided by the previous analysis, we apply tailored latent perturbations to produce diverse views for SSCRL, without relying on real data altogether. Additionally, we introduce a Continuous Sampling (CS) strategy, where the generator dynamically creates new samples during SSCRL training, greatly increasing data variability. Our comprehensive experiments demonstrate the effectiveness of these contributions, showing that MLVGMs' generated views compete on par with or even surpass views generated from real data. This work establishes a principled approach to understanding and exploiting MLVGMs, advancing both generative modeling and self-supervised learning.
Pre-trained Multiple Latent Variable Generative Models are good defenders against Adversarial Attacks
Dec 04, 2024



Attackers can deliberately perturb classifiers' input with subtle noise, altering final predictions. Among proposed countermeasures, adversarial purification employs generative networks to preprocess input images, filtering out adversarial noise. In this study, we propose specific generators, defined Multiple Latent Variable Generative Models (MLVGMs), for adversarial purification. These models possess multiple latent variables that naturally disentangle coarse from fine features. Taking advantage of these properties, we autoencode images to maintain class-relevant information, while discarding and re-sampling any detail, including adversarial noise. The procedure is completely training-free, exploring the generalization abilities of pre-trained MLVGMs on the adversarial purification downstream task. Despite the lack of large models, trained on billions of samples, we show that smaller MLVGMs are already competitive with traditional methods, and can be used as foundation models. Official code released at https://github.com/SerezD/gen_adversarial.
BillBoard Splatting (BBSplat): Learnable Textured Primitives for Novel View Synthesis
Nov 13, 2024



We present billboard Splatting (BBSplat) - a novel approach for 3D scene representation based on textured geometric primitives. BBSplat represents the scene as a set of optimizable textured planar primitives with learnable RGB textures and alpha-maps to control their shape. BBSplat primitives can be used in any Gaussian Splatting pipeline as drop-in replacements for Gaussians. Our method's qualitative and quantitative improvements over 3D and 2D Gaussians are most noticeable when fewer primitives are used, when BBSplat achieves over 1200 FPS. Our novel regularization term encourages textures to have a sparser structure, unlocking an efficient compression that leads to a reduction in storage space of the model. Our experiments show the efficiency of BBSplat on standard datasets of real indoor and outdoor scenes such as Tanks&Temples, DTU, and Mip-NeRF-360. We demonstrate improvements on PSNR, SSIM, and LPIPS metrics compared to the state-of-the-art, especially for the case when fewer primitives are used, which, on the other hand, leads to up to 2 times inference speed improvement for the same rendering quality.
Re-assembling the past: The RePAIR dataset and benchmark for real world 2D and 3D puzzle solving
Oct 31, 2024



This paper proposes the RePAIR dataset that represents a challenging benchmark to test modern computational and data driven methods for puzzle-solving and reassembly tasks. Our dataset has unique properties that are uncommon to current benchmarks for 2D and 3D puzzle solving. The fragments and fractures are realistic, caused by a collapse of a fresco during a World War II bombing at the Pompeii archaeological park. The fragments are also eroded and have missing pieces with irregular shapes and different dimensions, challenging further the reassembly algorithms. The dataset is multi-modal providing high resolution images with characteristic pictorial elements, detailed 3D scans of the fragments and meta-data annotated by the archaeologists. Ground truth has been generated through several years of unceasing fieldwork, including the excavation and cleaning of each fragment, followed by manual puzzle solving by archaeologists of a subset of approx. 1000 pieces among the 16000 available. After digitizing all the fragments in 3D, a benchmark was prepared to challenge current reassembly and puzzle-solving methods that often solve more simplistic synthetic scenarios. The tested baselines show that there clearly exists a gap to fill in solving this computationally complex problem.
DLGNet: Hyperedge Classification through Directed Line Graphs for Chemical Reactions
Oct 09, 2024



Graphs and hypergraphs provide powerful abstractions for modeling interactions among a set of entities of interest and have been attracting a growing interest in the literature thanks to many successful applications in several fields. In particular, they are rapidly expanding in domains such as chemistry and biology, especially in the areas of drug discovery and molecule generation. One of the areas witnessing the fasted growth is the chemical reactions field, where chemical reactions can be naturally encoded as directed hyperedges of a hypergraph. In this paper, we address the chemical reaction classification problem by introducing the notation of a Directed Line Graph (DGL) associated with a given directed hypergraph. On top of it, we build the Directed Line Graph Network (DLGNet), the first spectral-based Graph Neural Network (GNN) expressly designed to operate on a hypergraph via its DLG transformation. The foundation of DLGNet is a novel Hermitian matrix, the Directed Line Graph Laplacian, which compactly encodes the directionality of the interactions taking place within the directed hyperedges of the hypergraph thanks to the DLG representation. The Directed Line Graph Laplacian enjoys many desirable properties, including admitting an eigenvalue decomposition and being positive semidefinite, which make it well-suited for its adoption within a spectral-based GNN. Through extensive experiments on chemical reaction datasets, we show that DGLNet significantly outperforms the existing approaches, achieving on a collection of real-world datasets an average relative-percentage-difference improvement of 33.01%, with a maximum improvement of 37.71%.
Model Debiasing by Learnable Data Augmentation
Aug 09, 2024



Deep Neural Networks are well known for efficiently fitting training data, yet experiencing poor generalization capabilities whenever some kind of bias dominates over the actual task labels, resulting in models learning "shortcuts". In essence, such models are often prone to learn spurious correlations between data and labels. In this work, we tackle the problem of learning from biased data in the very realistic unsupervised scenario, i.e., when the bias is unknown. This is a much harder task as compared to the supervised case, where auxiliary, bias-related annotations, can be exploited in the learning process. This paper proposes a novel 2-stage learning pipeline featuring a data augmentation strategy able to regularize the training. First, biased/unbiased samples are identified by training over-biased models. Second, such subdivision (typically noisy) is exploited within a data augmentation framework, properly combining the original samples while learning mixing parameters, which has a regularization effect. Experiments on synthetic and realistic biased datasets show state-of-the-art classification accuracy, outperforming competing methods, ultimately proving robust performance on both biased and unbiased examples. Notably, being our training method totally agnostic to the level of bias, it also positively affects performance for any, even apparently unbiased, dataset, thus improving the model generalization regardless of the level of bias (or its absence) in the data.