 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBillBoard Splatting (BBSplat): Learnable Textured Primitives for Novel View Synthesis
Nov 13, 2024



We present billboard Splatting (BBSplat) - a novel approach for 3D scene representation based on textured geometric primitives. BBSplat represents the scene as a set of optimizable textured planar primitives with learnable RGB textures and alpha-maps to control their shape. BBSplat primitives can be used in any Gaussian Splatting pipeline as drop-in replacements for Gaussians. Our method's qualitative and quantitative improvements over 3D and 2D Gaussians are most noticeable when fewer primitives are used, when BBSplat achieves over 1200 FPS. Our novel regularization term encourages textures to have a sparser structure, unlocking an efficient compression that leads to a reduction in storage space of the model. Our experiments show the efficiency of BBSplat on standard datasets of real indoor and outdoor scenes such as Tanks&Temples, DTU, and Mip-NeRF-360. We demonstrate improvements on PSNR, SSIM, and LPIPS metrics compared to the state-of-the-art, especially for the case when fewer primitives are used, which, on the other hand, leads to up to 2 times inference speed improvement for the same rendering quality.
HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
Apr 01, 2024We present HAHA - a novel approach for animatable human avatar generation from monocular input videos. The proposed method relies on learning the trade-off between the use of Gaussian splatting and a textured mesh for efficient and high fidelity rendering. We demonstrate its efficiency to animate and render full-body human avatars controlled via the SMPL-X parametric model. Our model learns to apply Gaussian splatting only in areas of the SMPL-X mesh where it is necessary, like hair and out-of-mesh clothing. This results in a minimal number of Gaussians being used to represent the full avatar, and reduced rendering artifacts. This allows us to handle the animation of small body parts such as fingers that are traditionally disregarded. We demonstrate the effectiveness of our approach on two open datasets: SnapshotPeople and X-Humans. Our method demonstrates on par reconstruction quality to the state-of-the-art on SnapshotPeople, while using less than a third of Gaussians. HAHA outperforms previous state-of-the-art on novel poses from X-Humans both quantitatively and qualitatively.
MoRF: Mobile Realistic Fullbody Avatars from a Monocular Video
Mar 17, 2023
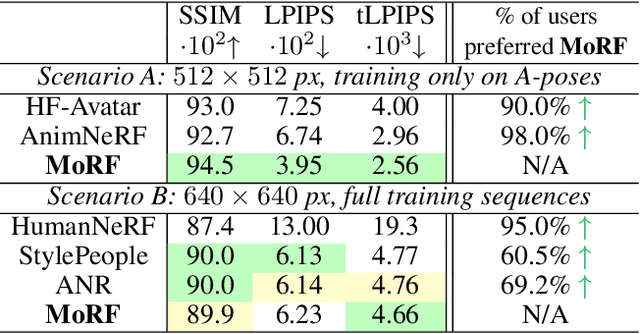
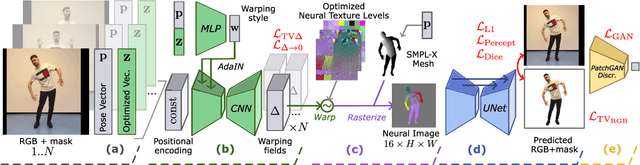
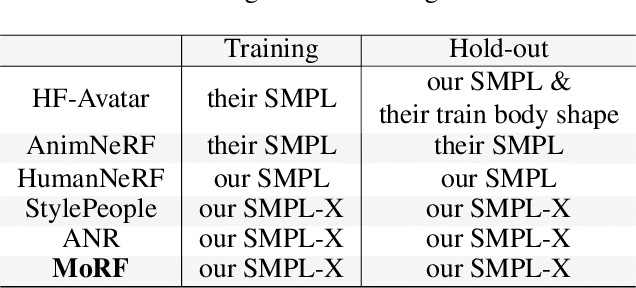
We present a new approach for learning Mobile Realistic Fullbody (MoRF) avatars. MoRF avatars can be rendered in real-time on mobile phones, have high realism, and can be learned from monocular videos. As in previous works, we use a combination of neural textures and the mesh-based body geometry modeling SMPL-X. We improve on prior work, by learning per-frame warping fields in the neural texture space, allowing to better align the training signal between different frames. We also apply existing SMPL-X fitting procedure refinements for videos to improve overall avatar quality. In the comparisons to other monocular video-based avatar systems, MoRF avatars achieve higher image sharpness and temporal consistency. Participants of our user study also preferred avatars generated by MoRF.
DINAR: Diffusion Inpainting of Neural Textures for One-Shot Human Avatars
Mar 17, 2023
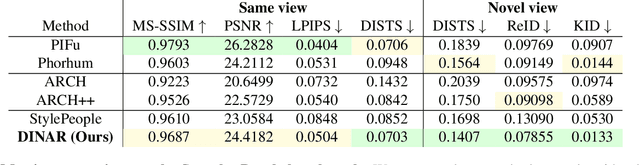
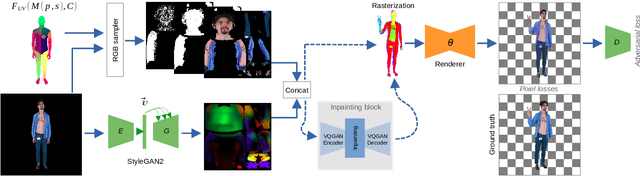
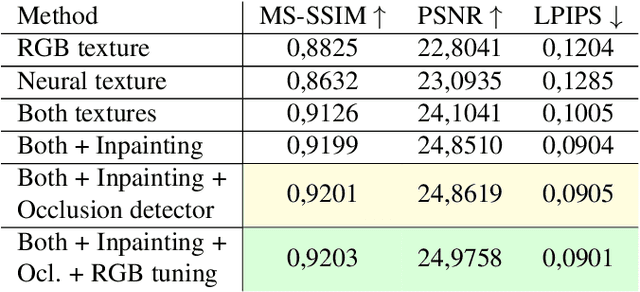
We present DINAR, an approach for creating realistic rigged fullbody avatars from single RGB images. Similarly to previous works, our method uses neural textures combined with the SMPL-X body model to achieve photo-realistic quality of avatars while keeping them easy to animate and fast to infer. To restore the texture, we use a latent diffusion model and show how such model can be trained in the neural texture space. The use of the diffusion model allows us to realistically reconstruct large unseen regions such as the back of a person given the frontal view. The models in our pipeline are trained using 2D images and videos only. In the experiments, our approach achieves state-of-the-art rendering quality and good generalization to new poses and viewpoints. In particular, the approach improves state-of-the-art on the SnapshotPeople public benchmark.
AmphibianDetector: adaptive computation for moving objects detection
Nov 15, 2020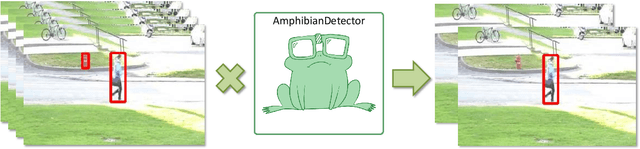

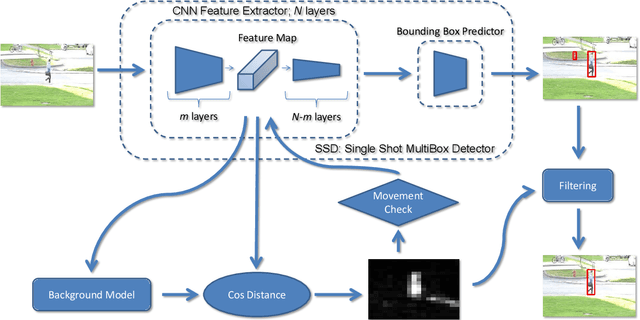

Convolutional neural networks (CNN) allow achieving the highest accuracy for the task of object detection in images. Major challenges in further development of object detectors are false-positive detections and high demand of processing power. In this paper, we propose an approach to object detection, which makes it possible to reduce the number of false-positive detections by processing only moving objects and reduce required processing power for algorithm inference. The proposed approach is modification of the CNN already trained for object detection task. This method can be used to improve the accuracy of an existing system by applying minor changes to the existing algorithm. The efficiency of the proposed approach was demonstrated on the open dataset "CDNet2014 pedestrian". The implementation of the method proposed in the article is available on the GitHub: https://github.com/david-svitov/AmphibianDetector
MarginDistillation: distillation for margin-based softmax
Mar 05, 2020
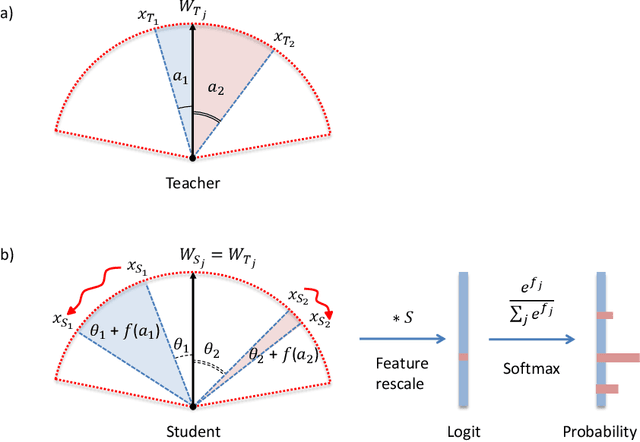
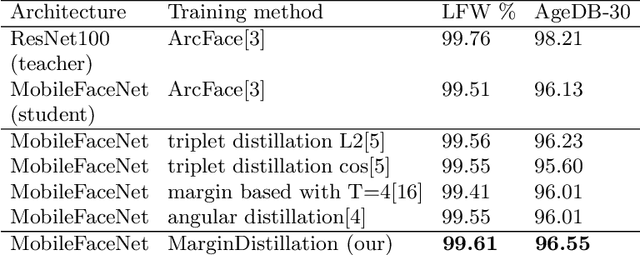
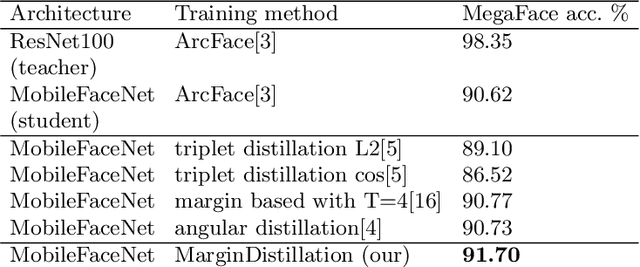
The usage of convolutional neural networks (CNNs) in conjunction with a margin-based softmax approach demonstrates a state-of-the-art performance for the face recognition problem. Recently, lightweight neural network models trained with the margin-based softmax have been introduced for the face identification task for edge devices. In this paper, we propose a novel distillation method for lightweight neural network architectures that outperforms other known methods for the face recognition task on LFW, AgeDB-30 and Megaface datasets. The idea of the proposed method is to use class centers from the teacher network for the student network. Then the student network is trained to get the same angles between the class centers and the face embeddings, predicted by the teacher network.
Low-Power Computer Vision: Status, Challenges, Opportunities
Apr 15, 2019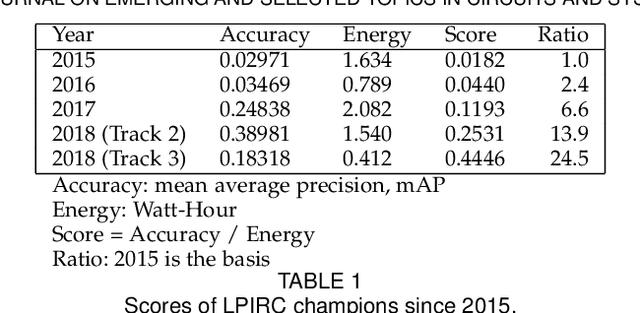
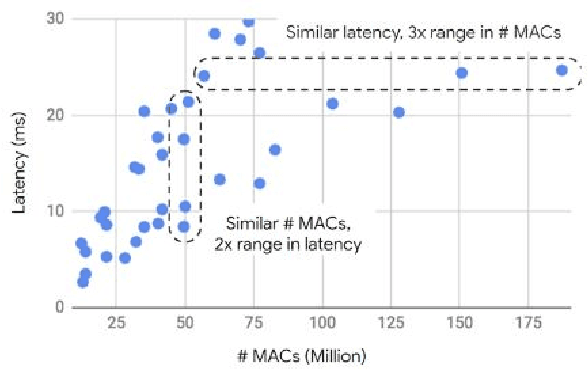
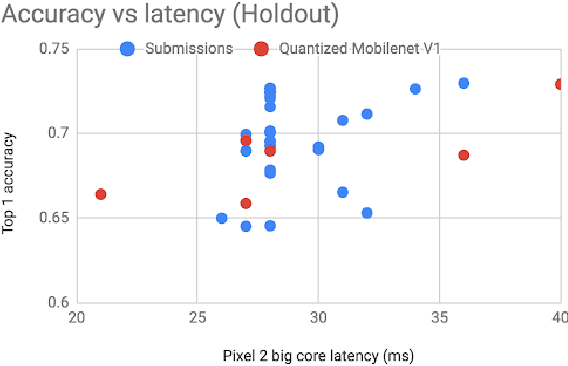
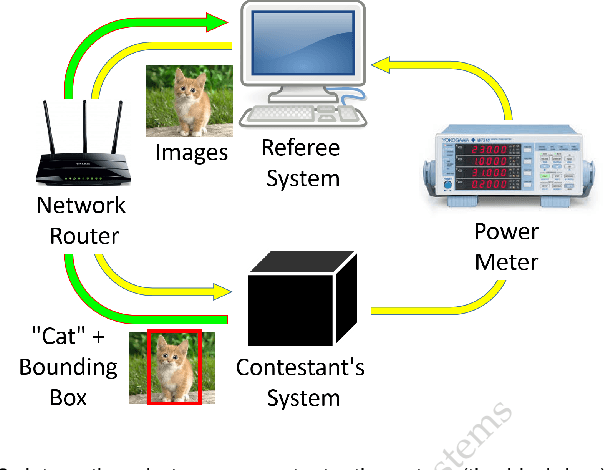
Computer vision has achieved impressive progress in recent years. Meanwhile, mobile phones have become the primary computing platforms for millions of people. In addition to mobile phones, many autonomous systems rely on visual data for making decisions and some of these systems have limited energy (such as unmanned aerial vehicles also called drones and mobile robots). These systems rely on batteries and energy efficiency is critical. This article serves two main purposes: (1) Examine the state-of-the-art for low-power solutions to detect objects in images. Since 2015, the IEEE Annual International Low-Power Image Recognition Challenge (LPIRC) has been held to identify the most energy-efficient computer vision solutions. This article summarizes 2018 winners' solutions. (2) Suggest directions for research as well as opportunities for low-power computer vision.
2018 Low-Power Image Recognition Challenge
Oct 03, 2018The Low-Power Image Recognition Challenge (LPIRC, https://rebootingcomputing.ieee.org/lpirc) is an annual competition started in 2015. The competition identifies the best technologies that can classify and detect objects in images efficiently (short execution time and low energy consumption) and accurately (high precision). Over the four years, the winners' scores have improved more than 24 times. As computer vision is widely used in many battery-powered systems (such as drones and mobile phones), the need for low-power computer vision will become increasingly important. This paper summarizes LPIRC 2018 by describing the three different tracks and the winners' solutions.