 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Perception Gap: A Lightweight Coarse-to-Fine Architecture for Edge Audio Systems
Jan 22, 2026Deploying Audio-Language Models (Audio-LLMs) on edge infrastructure exposes a persistent tension between perception depth and computational efficiency. Lightweight local models tend to produce passive perception - generic summaries that miss the subtle evidence required for multi-step audio reasoning - while indiscriminate cloud offloading incurs unacceptable latency, bandwidth cost, and privacy risk. We propose CoFi-Agent (Tool-Augmented Coarse-to-Fine Agent), a hybrid architecture targeting edge servers and gateways. It performs fast local perception and triggers conditional forensic refinement only when uncertainty is detected. CoFi-Agent runs an initial single-pass on a local 7B Audio-LLM, then a cloud controller gates difficult cases and issues lightweight plans for on-device tools such as temporal re-listening and local ASR. On the MMAR benchmark, CoFi-Agent improves accuracy from 27.20% to 53.60%, while achieving a better accuracy-efficiency trade-off than an always-on investigation pipeline. Overall, CoFi-Agent bridges the perception gap via tool-enabled, conditional edge-cloud collaboration under practical system constraints.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025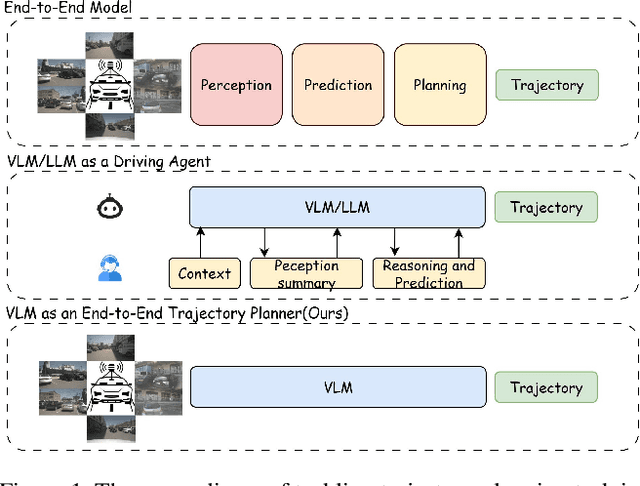
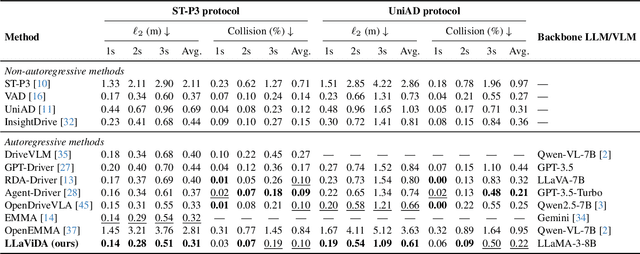
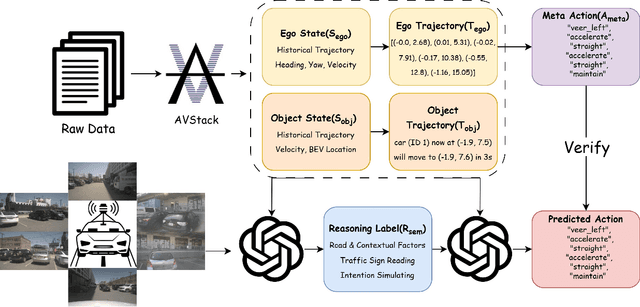
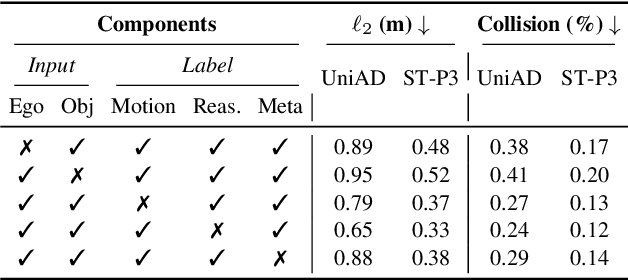
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
FractalCloud: A Fractal-Inspired Architecture for Efficient Large-Scale Point Cloud Processing
Nov 10, 2025Three-dimensional (3D) point clouds are increasingly used in applications such as autonomous driving, robotics, and virtual reality (VR). Point-based neural networks (PNNs) have demonstrated strong performance in point cloud analysis, originally targeting small-scale inputs. However, as PNNs evolve to process large-scale point clouds with hundreds of thousands of points, all-to-all computation and global memory access in point cloud processing introduce substantial overhead, causing $O(n^2)$ computational complexity and memory traffic where n is the number of points}. Existing accelerators, primarily optimized for small-scale workloads, overlook this challenge and scale poorly due to inefficient partitioning and non-parallel architectures. To address these issues, we propose FractalCloud, a fractal-inspired hardware architecture for efficient large-scale 3D point cloud processing. FractalCloud introduces two key optimizations: (1) a co-designed Fractal method for shape-aware and hardware-friendly partitioning, and (2) block-parallel point operations that decompose and parallelize all point operations. A dedicated hardware design with on-chip fractal and flexible parallelism further enables fully parallel processing within limited memory resources. Implemented in 28 nm technology as a chip layout with a core area of 1.5 $mm^2$, FractalCloud achieves 21.7x speedup and 27x energy reduction over state-of-the-art accelerators while maintaining network accuracy, demonstrating its scalability and efficiency for PNN inference.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.
SADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
CROP: Circuit Retrieval and Optimization with Parameter Guidance using LLMs
Jul 02, 2025Modern very large-scale integration (VLSI) design requires the implementation of integrated circuits using electronic design automation (EDA) tools. Due to the complexity of EDA algorithms, the vast parameter space poses a huge challenge to chip design optimization, as the combination of even moderate numbers of parameters creates an enormous solution space to explore. Manual parameter selection remains industrial practice despite being excessively laborious and limited by expert experience. To address this issue, we present CROP, the first large language model (LLM)-powered automatic VLSI design flow tuning framework. Our approach includes: (1) a scalable methodology for transforming RTL source code into dense vector representations, (2) an embedding-based retrieval system for matching designs with semantically similar circuits, and (3) a retrieval-augmented generation (RAG)-enhanced LLM-guided parameter search system that constrains the search process with prior knowledge from similar designs. Experiment results demonstrate CROP's ability to achieve superior quality-of-results (QoR) with fewer iterations than existing approaches on industrial designs, including a 9.9% reduction in power consumption.
LaMAGIC2: Advanced Circuit Formulations for Language Model-Based Analog Topology Generation
Jun 11, 2025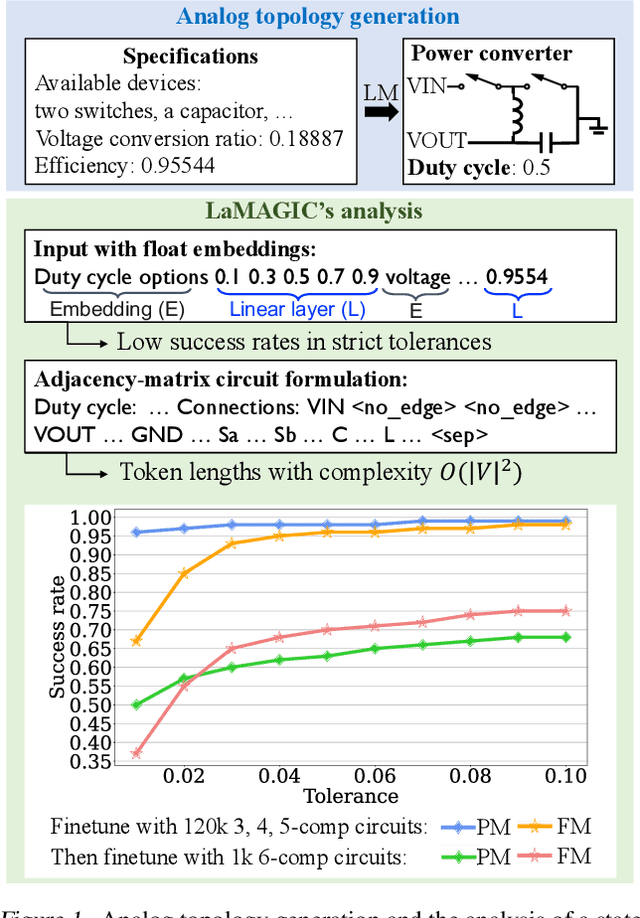

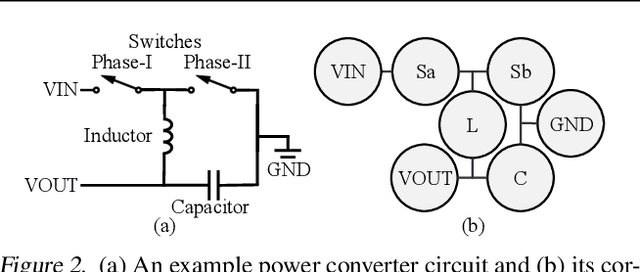

Automation of analog topology design is crucial due to customized requirements of modern applications with heavily manual engineering efforts. The state-of-the-art work applies a sequence-to-sequence approach and supervised finetuning on language models to generate topologies given user specifications. However, its circuit formulation is inefficient due to O(|V |2) token length and suffers from low precision sensitivity to numeric inputs. In this work, we introduce LaMAGIC2, a succinct float-input canonical formulation with identifier (SFCI) for language model-based analog topology generation. SFCI addresses these challenges by improving component-type recognition through identifier-based representations, reducing token length complexity to O(|V |), and enhancing numeric precision sensitivity for better performance under tight tolerances. Our experiments demonstrate that LaMAGIC2 achieves 34% higher success rates under a tight tolerance of 0.01 and 10X lower MSEs compared to a prior method. LaMAGIC2 also exhibits better transferability for circuits with more vertices with up to 58.5% improvement. These advancements establish LaMAGIC2 as a robust framework for analog topology generation.
MoE-GPS: Guidlines for Prediction Strategy for Dynamic Expert Duplication in MoE Load Balancing
Jun 09, 2025In multi-GPU Mixture-of-Experts (MoE) network, experts are distributed across different GPUs, which creates load imbalance as each expert processes different number of tokens. Recent works improve MoE inference load balance by dynamically duplicating popular experts to more GPUs to process excessive tokens, which requires predicting the distribution before routing. In this paper, we discuss the tradeoff of prediction strategies, accuracies, overhead, and end-to-end system performance. We propose MoE-GPS, a framework that guides the selection of the optimal predictor design under various system configurations, by quantifying the performance impact to system-level model runtime. Specifically, we advocate for Distribution-Only Prediction, a prediction strategy that only predicts overall token distribution which significantly reduces overhead compared to the traditional Token-to-Expert Prediction. On Mixtral 8x7B MMLU dataset, MoE-GPS suggests Distribution-Only Prediction which improves end-to-end inference performance by more than 23% compared with Token-to-Expert Prediction.
CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models
May 25, 2025Vision-Language Models (VLMs) excel across diverse tasks but suffer from high inference costs in time and memory. Token sparsity mitigates inefficiencies in token usage, while neuron sparsity reduces high-dimensional computations, both offering promising solutions to enhance efficiency. Recently, these two sparsity paradigms have evolved largely in parallel, fostering the prevailing assumption that they function independently. However, a fundamental yet underexplored question remains: Do they truly operate in isolation, or is there a deeper underlying interplay that has yet to be uncovered? In this paper, we conduct the first comprehensive investigation into this question. By introducing and analyzing the matching mechanism between Core Neurons and Core Tokens, we found that key neurons and tokens for inference mutually influence and reinforce each other. Building on this insight, we propose CoreMatching, a co-adaptive sparse inference framework, which leverages the synergy between token and neuron sparsity to enhance inference efficiency. Through theoretical analysis and efficiency evaluations, we demonstrate that the proposed method surpasses state-of-the-art baselines on ten image understanding tasks and three hardware devices. Notably, on the NVIDIA Titan Xp, it achieved 5x FLOPs reduction and a 10x overall speedup. Code is released at https://github.com/wangqinsi1/2025-ICML-CoreMatching/tree/main.
CONCORD: Concept-Informed Diffusion for Dataset Distillation
May 23, 2025Dataset distillation (DD) has witnessed significant progress in creating small datasets that encapsulate rich information from large original ones. Particularly, methods based on generative priors show promising performance, while maintaining computational efficiency and cross-architecture generalization. However, the generation process lacks explicit controllability for each sample. Previous distillation methods primarily match the real distribution from the perspective of the entire dataset, whereas overlooking concept completeness at the instance level. The missing or incorrectly represented object details cannot be efficiently compensated due to the constrained sample amount typical in DD settings. To this end, we propose incorporating the concept understanding of large language models (LLMs) to perform Concept-Informed Diffusion (CONCORD) for dataset distillation. Specifically, distinguishable and fine-grained concepts are retrieved based on category labels to inform the denoising process and refine essential object details. By integrating these concepts, the proposed method significantly enhances both the controllability and interpretability of the distilled image generation, without relying on pre-trained classifiers. We demonstrate the efficacy of CONCORD by achieving state-of-the-art performance on ImageNet-1K and its subsets. The code implementation is released in https://github.com/vimar-gu/CONCORD.