 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards an Agent-First Web: Redesigning the Web for AI Agents
Jun 17, 2026The World Wide Web was built on an assumption held for three decades: the primary consumer of web content is a human being. This permeates every layer; its access model presumes human visitors, its economics rest on human attention, and its content targets human perception. The rapid emergence of AI agents as intermediaries between humans and web content invalidates this assumption. Yet the web resists agents through blanket blocking, CAPTCHA-based exclusion, and economic models that treat agent access as extraction rather than legitimate interaction. This paper proposes a principled redesign across three layers. At the access layer, agents acting for humans should inherit equivalent access rights, governed by rate limiting and agent identification metadata in HTTP requests, analogous to browser headers, alongside a dual-layer architecture serving human-readable and agent-optimized content from the same domain. At the economic layer, we propose an intent-based tier framework grounded in the agent-as-human-proxy principle: an agent's economic obligation mirrors that of the human it represents. A token-based subscription model meters content in tokens rather than pageviews, alongside a commissioned content economy anchoring AI content production in human intentionality. At the content layer, we identify epistemic recursion, the self-referential loop in which AI-generated content is consumed by agents to produce further content, progressively detaching web knowledge from human ground truth. We propose the Agent Text Markup Language (ATML), a four-level human supervision tier model, and a cryptographic provenance chain to counter this threat. Together these constitute ten design principles for an agent-first internet, one in which agents are first-class citizens whose integration requires renegotiating the web's foundational social contract across access, economics, and content.
MindGap: A Conversational AI Framework for Upstream Neuroplastic Intervention in Post-Traumatic Stress Disorder
May 14, 2026Post-Traumatic Stress Disorder (PTSD) is fundamentally a neuroplastic problem traumatic contact events encode over-reactive neural pathways through Hebbian long-term potentiation, producing hair-triggered amygdala-HPA stress cascades that fire before conscious awareness can intercept them. Existing therapeutic approaches, prolonged exposure, EMDR, cognitive behavioural therapy, operate predominantly downstream of the reactive cascade, teaching patients to tolerate or reframe distress after it has arisen. While clinically valuable, these suppression-based approaches do not produce the upstream pathway dissolution that constitutes lasting structural neural reorganisation. This paper proposes MindGap, a privacy-preserving on-device conversational AI framework that delivers structured neuroplastic rehabilitation for PTSD through the practice of dependent origination, a Buddhist psychological framework that identifies the precise moment between the pre-cognitive affective signal and the reactive elaboration that follows as the site of therapeutic intervention. MindGap guides patients through three progressive layers of observation at this feeling tone gap: noticing the bare affective signal before reactive elaboration, recognising it as self-arising rather than caused by the stimulus, and recognising the conditioned implicit belief beneath the feeling. Each layer corresponds to progressively deeper prefrontal regulatory engagement and progressively deeper long-term depression-mediated weakening of the reactive pathway, producing genuine upstream dissolution rather than downstream suppression. Running entirely on-device with no data egress, MindGap delivers daily calibrated exposure sessions through a fine-tuned lightweight large language model, making it deployable in sensitive clinical and military contexts where cloud-based solutions are not permitted.
Think Before You Act -- A Neurocognitive Governance Model for Autonomous AI Agents
Apr 28, 2026The rapid deployment of autonomous AI agents across enterprise, healthcare, and safety-critical environments has created a fundamental governance gap. Existing approaches, runtime guardrails, training-time alignment, and post-hoc auditing treat governance as an external constraint rather than an internalized behavioral principle, leaving agents vulnerable to unsafe and irreversible actions. We address this gap by drawing on how humans self-govern naturally: before acting, humans engage deliberate cognitive processes grounded in executive function, inhibitory control, and internalized organizational rules to evaluate whether an intended action is permissible, requires modification, or demands escalation. This paper proposes a neurocognitive governance framework that formally maps this human self-governance process to LLM-driven agent reasoning, establishing a structural parallel between the human brain and the large language model as the cognitive core of an agent. We formalize a Pre-Action Governance Reasoning Loop (PAGRL) in which agents consult a four-layer governance rule set: global, workflow-specific, agent-specific, and situational before every consequential action, mirroring how human organizations structure compliance hierarchies across enterprise, department, and role levels. Implemented on a production-grade retail supply chain workflow, the framework achieves 95% compliance accuracy and zero false escalations to human oversight, demonstrating that embedding governance into agent reasoning produces more consistent, explainable, and auditable compliance than external enforcement. This work offers a principled foundation for autonomous AI agents that govern themselves the way humans do: not because rules are imposed upon them, but because deliberation is embedded in how they think.
Flowr -- Scaling Up Retail Supply Chain Operations Through Agentic AI in Large Scale Supermarket Chains
Apr 07, 2026Retail supply chain operations in supermarket chains involve continuous, high-volume manual workflows spanning demand forecasting, procurement, supplier coordination, and inventory replenishment, processes that are repetitive, decision-intensive, and difficult to scale without significant human effort. Despite growing investment in data analytics, the decision-making and coordination layers of these workflows remain predominantly manual, reactive, and fragmented across outlets, distribution centers, and supplier networks. This paper introduces Flowr, a novel agentic AI framework for automating end-to-end retail supply chain workflows in large-scale supermarket operations. Flowr systematically decomposes manual supply chain operations into specialized AI agents, each responsible for a clearly defined cognitive role, enabling automation of processes previously dependent on continuous human coordination. To ensure task accuracy and adherence to responsible AI principles, the framework employs a consortium of fine-tuned, domain-specialized large language models coordinated by a central reasoning LLM. Central to the framework is a human-in-the-loop orchestration model in which supply chain managers supervise and intervene across workflow stages via a Model Context Protocol (MCP)-enabled interface, preserving accountability and organizational control. Evaluation demonstrates that Flowr significantly reduces manual coordination overhead, improves demand-supply alignment, and enables proactive exception handling at a scale unachievable through manual processes. The framework was validated in collaboration with a large-scale supermarket chain and is domain-independent, offering a generalizable blueprint for agentic AI-driven supply chain automation across large-scale enterprise settings.
AI Trust OS -- A Continuous Governance Framework for Autonomous AI Observability and Zero-Trust Compliance in Enterprise Environments
Apr 06, 2026The accelerating adoption of large language models, retrieval-augmented generation pipelines, and multi-agent AI workflows has created a structural governance crisis. Organizations cannot govern what they cannot see, and existing compliance methodologies built for deterministic web applications provide no mechanism for discovering or continuously validating AI systems that emerge across engineering teams without formal oversight. The result is a widening trust gap between what regulators demand as proof of AI governance maturity and what organizations can demonstrate. This paper proposes AI Trust OS, a governance architecture for continuous, autonomous AI observability and zero-trust compliance. AI Trust OS reconceptualizes compliance as an always-on, telemetry-driven operating layer in which AI systems are discovered through observability signals, control assertions are collected by automated probes, and trust artifacts are synthesized continuously. The framework rests on four principles: proactive discovery, telemetry evidence over manual attestation, continuous posture over point-in-time audit, and architecture-backed proof over policy-document trust. The framework operates through a zero-trust telemetry boundary in which ephemeral read-only probes validate structural metadata without ingressing source code or payload-level PII. An AI Observability Extractor Agent scans LangSmith and Datadog LLM telemetry, automatically registering undocumented AI systems and shifting governance from organizational self-report to empirical machine observation. Evaluated across ISO 42001, the EU AI Act, SOC 2, GDPR, and HIPAA, the paper argues that telemetry-first AI governance represents a categorical architectural shift in how enterprise trust is produced and demonstrated.
Towards Responsible and Explainable AI Agents with Consensus-Driven Reasoning
Dec 25, 2025Agentic AI represents a major shift in how autonomous systems reason, plan, and execute multi-step tasks through the coordination of Large Language Models (LLMs), Vision Language Models (VLMs), tools, and external services. While these systems enable powerful new capabilities, increasing autonomy introduces critical challenges related to explainability, accountability, robustness, and governance, especially when agent outputs influence downstream actions or decisions. Existing agentic AI implementations often emphasize functionality and scalability, yet provide limited mechanisms for understanding decision rationale or enforcing responsibility across agent interactions. This paper presents a Responsible(RAI) and Explainable(XAI) AI Agent Architecture for production-grade agentic workflows based on multi-model consensus and reasoning-layer governance. In the proposed design, a consortium of heterogeneous LLM and VLM agents independently generates candidate outputs from a shared input context, explicitly exposing uncertainty, disagreement, and alternative interpretations. A dedicated reasoning agent then performs structured consolidation across these outputs, enforcing safety and policy constraints, mitigating hallucinations and bias, and producing auditable, evidence-backed decisions. Explainability is achieved through explicit cross-model comparison and preserved intermediate outputs, while responsibility is enforced through centralized reasoning-layer control and agent-level constraints. We evaluate the architecture across multiple real-world agentic AI workflows, demonstrating that consensus-driven reasoning improves robustness, transparency, and operational trust across diverse application domains. This work provides practical guidance for designing agentic AI systems that are autonomous and scalable, yet responsible and explainable by construction.
A Practical Guide for Designing, Developing, and Deploying Production-Grade Agentic AI Workflows
Dec 09, 2025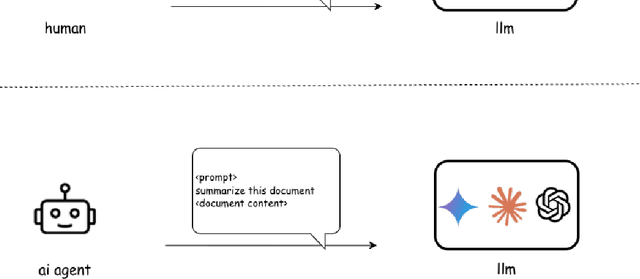
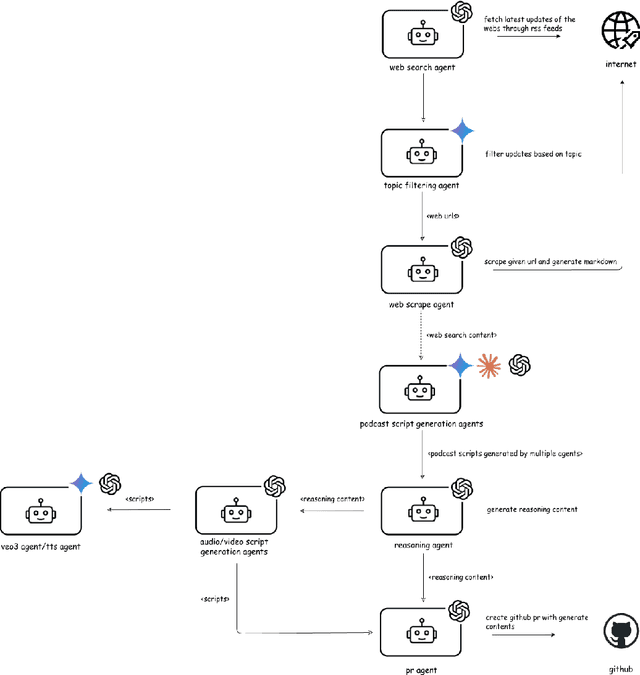

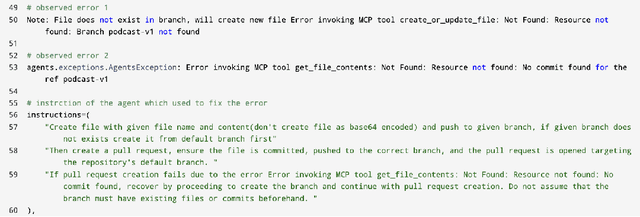
Agentic AI marks a major shift in how autonomous systems reason, plan, and execute multi-step tasks. Unlike traditional single model prompting, agentic workflows integrate multiple specialized agents with different Large Language Models(LLMs), tool-augmented capabilities, orchestration logic, and external system interactions to form dynamic pipelines capable of autonomous decision-making and action. As adoption accelerates across industry and research, organizations face a central challenge: how to design, engineer, and operate production-grade agentic AI workflows that are reliable, observable, maintainable, and aligned with safety and governance requirements. This paper provides a practical, end-to-end guide for designing, developing, and deploying production-quality agentic AI systems. We introduce a structured engineering lifecycle encompassing workflow decomposition, multi-agent design patterns, Model Context Protocol(MCP), and tool integration, deterministic orchestration, Responsible-AI considerations, and environment-aware deployment strategies. We then present nine core best practices for engineering production-grade agentic AI workflows, including tool-first design over MCP, pure-function invocation, single-tool and single-responsibility agents, externalized prompt management, Responsible-AI-aligned model-consortium design, clean separation between workflow logic and MCP servers, containerized deployment for scalable operations, and adherence to the Keep it Simple, Stupid (KISS) principle to maintain simplicity and robustness. To demonstrate these principles in practice, we present a comprehensive case study: a multimodal news-analysis and media-generation workflow. By combining architectural guidance, operational patterns, and practical implementation insights, this paper offers a foundational reference to build robust, extensible, and production-ready agentic AI workflows.
Standardization of Neuromuscular Reflex Analysis -- Role of Fine-Tuned Vision-Language Model Consortium and OpenAI gpt-oss Reasoning LLM Enabled Decision Support System
Aug 17, 2025



Accurate assessment of neuromuscular reflexes, such as the H-reflex, plays a critical role in sports science, rehabilitation, and clinical neurology. Traditional analysis of H-reflex EMG waveforms is subject to variability and interpretation bias among clinicians and researchers, limiting reliability and standardization. To address these challenges, we propose a Fine-Tuned Vision-Language Model (VLM) Consortium and a reasoning Large-Language Model (LLM)-enabled Decision Support System for automated H-reflex waveform interpretation and diagnosis. Our approach leverages multiple VLMs, each fine-tuned on curated datasets of H-reflex EMG waveform images annotated with clinical observations, recovery timelines, and athlete metadata. These models are capable of extracting key electrophysiological features and predicting neuromuscular states, including fatigue, injury, and recovery, directly from EMG images and contextual metadata. Diagnostic outputs from the VLM consortium are aggregated using a consensus-based method and refined by a specialized reasoning LLM, which ensures robust, transparent, and explainable decision support for clinicians and sports scientists. The end-to-end platform orchestrates seamless communication between the VLM ensemble and the reasoning LLM, integrating prompt engineering strategies and automated reasoning workflows using LLM Agents. Experimental results demonstrate that this hybrid system delivers highly accurate, consistent, and interpretable H-reflex assessments, significantly advancing the automation and standardization of neuromuscular diagnostics. To our knowledge, this work represents the first integration of a fine-tuned VLM consortium with a reasoning LLM for image-based H-reflex analysis, laying the foundation for next-generation AI-assisted neuromuscular assessment and athlete monitoring platforms.
Proactive Privacy Amnesia for Large Language Models: Safeguarding PII with Negligible Impact on Model Utility
Feb 24, 2025With the rise of large language models (LLMs), increasing research has recognized their risk of leaking personally identifiable information (PII) under malicious attacks. Although efforts have been made to protect PII in LLMs, existing methods struggle to balance privacy protection with maintaining model utility. In this paper, inspired by studies of amnesia in cognitive science, we propose a novel approach, Proactive Privacy Amnesia (PPA), to safeguard PII in LLMs while preserving their utility. This mechanism works by actively identifying and forgetting key memories most closely associated with PII in sequences, followed by a memory implanting using suitable substitute memories to maintain the LLM's functionality. We conduct evaluations across multiple models to protect common PII, such as phone numbers and physical addresses, against prevalent PII-targeted attacks, demonstrating the superiority of our method compared with other existing defensive techniques. The results show that our PPA method completely eliminates the risk of phone number exposure by 100% and significantly reduces the risk of physical address exposure by 9.8% - 87.6%, all while maintaining comparable model utility performance.
FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning
Sep 12, 2024



Federated Learning (FL) provides a strong privacy guarantee by enabling local training across edge devices without training data sharing, and Federated Adversarial Training (FAT) further enhances the robustness against adversarial examples, promoting a step toward trustworthy artificial intelligence. However, FAT requires a large model to preserve high accuracy while achieving strong robustness, and it is impractically slow when directly training with memory-constrained edge devices due to the memory-swapping latency. Moreover, existing memory-efficient FL methods suffer from poor accuracy and weak robustness in FAT because of inconsistent local and global models, i.e., objective inconsistency. In this paper, we propose FedProphet, a novel FAT framework that can achieve memory efficiency, adversarial robustness, and objective consistency simultaneously. FedProphet partitions the large model into small cascaded modules such that the memory-constrained devices can conduct adversarial training module-by-module. A strong convexity regularization is derived to theoretically guarantee the robustness of the whole model, and we show that the strong robustness implies low objective inconsistency in FedProphet. We also develop a training coordinator on the server of FL, with Adaptive Perturbation Adjustment for utility-robustness balance and Differentiated Module Assignment for objective inconsistency mitigation. FedProphet empirically shows a significant improvement in both accuracy and robustness compared to previous memory-efficient methods, achieving almost the same performance of end-to-end FAT with 80% memory reduction and up to 10.8x speedup in training time.