 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Data Augmentation with Multi-armed Bandit: Sample-Efficient Embedding Calibration for Implicit Pattern Recognition
Feb 22, 2026Recognizing implicit visual and textual patterns is essential in many real-world applications of modern AI. However, tackling long-tail pattern recognition tasks remains challenging for current pre-trained foundation models such as LLMs and VLMs. While finetuning pre-trained models can improve accuracy in recognizing implicit patterns, it is usually infeasible due to a lack of training data and high computational overhead. In this paper, we propose ADAMAB, an efficient embedding calibration framework for few-shot pattern recognition. To maximally reduce the computational costs, ADAMAB trains embedder-agnostic light-weight calibrators on top of fixed embedding models without accessing their parameters. To mitigate the need for large-scale training data, we introduce an adaptive data augmentation strategy based on the Multi-Armed Bandit (MAB) mechanism. With a modified upper confidence bound algorithm, ADAMAB diminishes the gradient shifting and offers theoretically guaranteed convergence in few-shot training. Our multi-modal experiments justify the superior performance of ADAMAB, with up to 40% accuracy improvement when training with less than 5 initial data samples of each class.
Proactive Privacy Amnesia for Large Language Models: Safeguarding PII with Negligible Impact on Model Utility
Feb 24, 2025With the rise of large language models (LLMs), increasing research has recognized their risk of leaking personally identifiable information (PII) under malicious attacks. Although efforts have been made to protect PII in LLMs, existing methods struggle to balance privacy protection with maintaining model utility. In this paper, inspired by studies of amnesia in cognitive science, we propose a novel approach, Proactive Privacy Amnesia (PPA), to safeguard PII in LLMs while preserving their utility. This mechanism works by actively identifying and forgetting key memories most closely associated with PII in sequences, followed by a memory implanting using suitable substitute memories to maintain the LLM's functionality. We conduct evaluations across multiple models to protect common PII, such as phone numbers and physical addresses, against prevalent PII-targeted attacks, demonstrating the superiority of our method compared with other existing defensive techniques. The results show that our PPA method completely eliminates the risk of phone number exposure by 100% and significantly reduces the risk of physical address exposure by 9.8% - 87.6%, all while maintaining comparable model utility performance.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking
Feb 18, 2025



Large Reasoning Models (LRMs) have recently extended their powerful reasoning capabilities to safety checks-using chain-of-thought reasoning to decide whether a request should be answered. While this new approach offers a promising route for balancing model utility and safety, its robustness remains underexplored. To address this gap, we introduce Malicious-Educator, a benchmark that disguises extremely dangerous or malicious requests beneath seemingly legitimate educational prompts. Our experiments reveal severe security flaws in popular commercial-grade LRMs, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking. For instance, although OpenAI's o1 model initially maintains a high refusal rate of about 98%, subsequent model updates significantly compromise its safety; and attackers can easily extract criminal strategies from DeepSeek-R1 and Gemini 2.0 Flash Thinking without any additional tricks. To further highlight these vulnerabilities, we propose Hijacking Chain-of-Thought (H-CoT), a universal and transferable attack method that leverages the model's own displayed intermediate reasoning to jailbreak its safety reasoning mechanism. Under H-CoT, refusal rates sharply decline-dropping from 98% to below 2%-and, in some instances, even transform initially cautious tones into ones that are willing to provide harmful content. We hope these findings underscore the urgent need for more robust safety mechanisms to preserve the benefits of advanced reasoning capabilities without compromising ethical standards.
FedProphet: Memory-Efficient Federated Adversarial Training via Theoretic-Robustness and Low-Inconsistency Cascade Learning
Sep 12, 2024



Federated Learning (FL) provides a strong privacy guarantee by enabling local training across edge devices without training data sharing, and Federated Adversarial Training (FAT) further enhances the robustness against adversarial examples, promoting a step toward trustworthy artificial intelligence. However, FAT requires a large model to preserve high accuracy while achieving strong robustness, and it is impractically slow when directly training with memory-constrained edge devices due to the memory-swapping latency. Moreover, existing memory-efficient FL methods suffer from poor accuracy and weak robustness in FAT because of inconsistent local and global models, i.e., objective inconsistency. In this paper, we propose FedProphet, a novel FAT framework that can achieve memory efficiency, adversarial robustness, and objective consistency simultaneously. FedProphet partitions the large model into small cascaded modules such that the memory-constrained devices can conduct adversarial training module-by-module. A strong convexity regularization is derived to theoretically guarantee the robustness of the whole model, and we show that the strong robustness implies low objective inconsistency in FedProphet. We also develop a training coordinator on the server of FL, with Adaptive Perturbation Adjustment for utility-robustness balance and Differentiated Module Assignment for objective inconsistency mitigation. FedProphet empirically shows a significant improvement in both accuracy and robustness compared to previous memory-efficient methods, achieving almost the same performance of end-to-end FAT with 80% memory reduction and up to 10.8x speedup in training time.
FADE: Enabling Large-Scale Federated Adversarial Training on Resource-Constrained Edge Devices
Sep 08, 2022
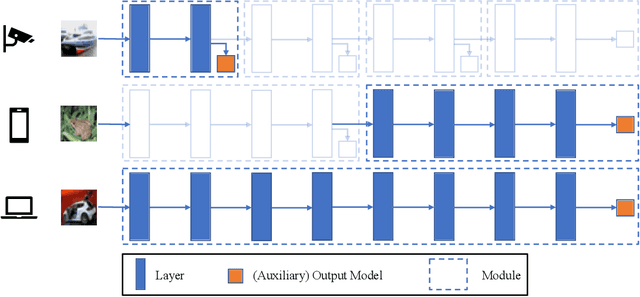
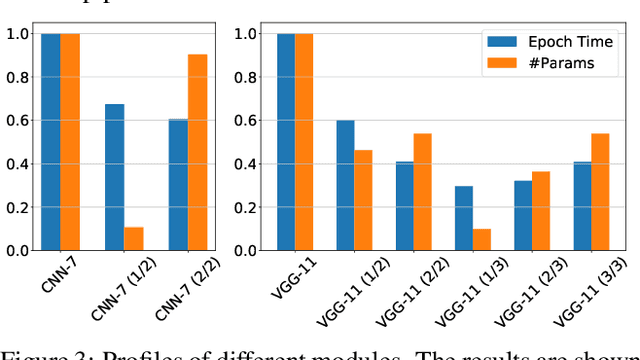
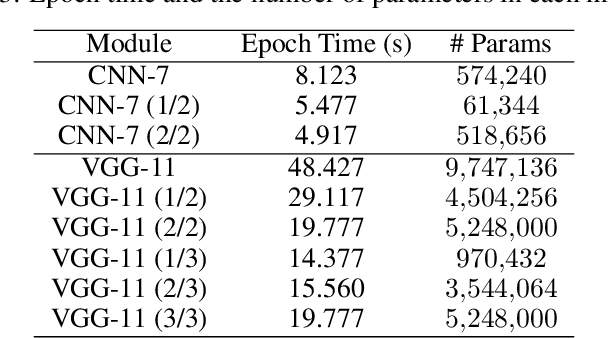
Adversarial Training (AT) has been proven to be an effective method of introducing strong adversarial robustness into deep neural networks. However, the high computational cost of AT prohibits the deployment of large-scale AT on resource-constrained edge devices, e.g., with limited computing power and small memory footprint, in Federated Learning (FL) applications. Very few previous studies have tried to tackle these constraints in FL at the same time. In this paper, we propose a new framework named Federated Adversarial Decoupled Learning (FADE) to enable AT on resource-constrained edge devices in FL. FADE reduces the computation and memory usage by applying Decoupled Greedy Learning (DGL) to federated adversarial training such that each client only needs to perform AT on a small module of the entire model in each communication round. In addition, we improve vanilla DGL by adding an auxiliary weight decay to alleviate objective inconsistency and achieve better performance. FADE offers a theoretical guarantee for the adversarial robustness and convergence. The experimental results also show that FADE can significantly reduce the computing resources consumed by AT while maintaining almost the same accuracy and robustness as fully joint training.