 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025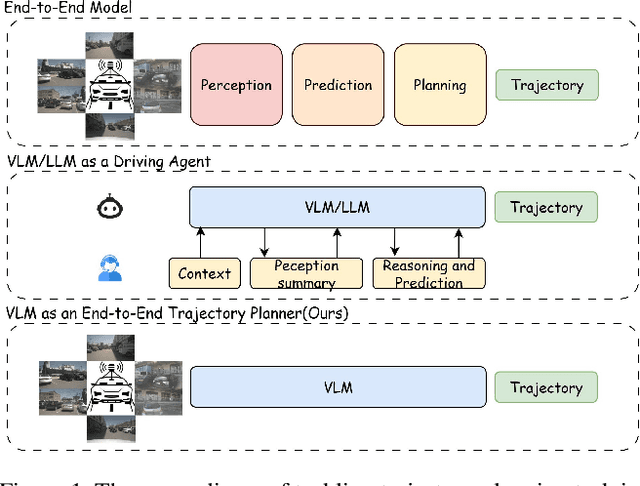
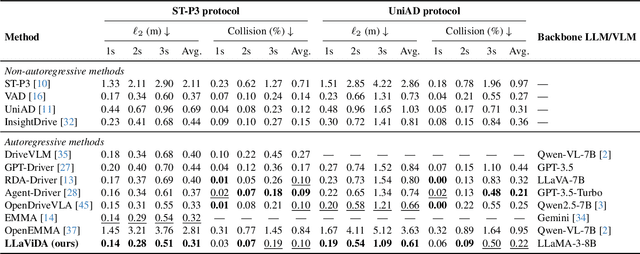
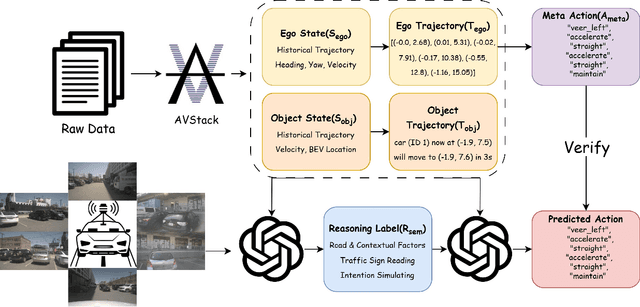
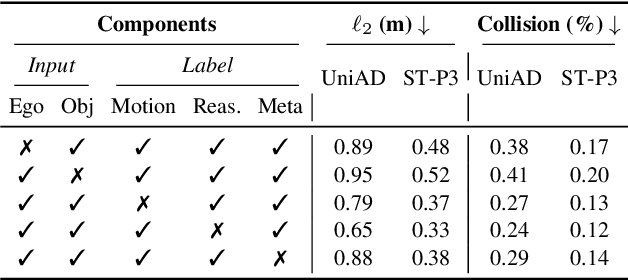
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Voice Evaluation of Reasoning Ability: Diagnosing the Modality-Induced Performance Gap
Sep 30, 2025We present Voice Evaluation of Reasoning Ability (VERA), a benchmark for evaluating reasoning ability in voice-interactive systems under real-time conversational constraints. VERA comprises 2,931 voice-native episodes derived from established text benchmarks and organized into five tracks (Math, Web, Science, Long-Context, Factual). Each item is adapted for speech interaction while preserving reasoning difficulty. VERA enables direct text-voice comparison within model families and supports analysis of how architectural choices affect reliability. We assess 12 contemporary voice systems alongside strong text baselines and observe large, consistent modality gaps: on competition mathematics a leading text model attains 74.8% accuracy while its voice counterpart reaches 6.1%; macro-averaged across tracks the best text models achieve 54.0% versus 11.3% for voice. Latency-accuracy analyses reveal a low-latency plateau, where fast voice systems cluster around ~10% accuracy, while approaching text performance requires sacrificing real-time interaction. Diagnostic experiments indicate that common mitigations are insufficient. Increasing "thinking time" yields negligible gains; a decoupled cascade that separates reasoning from narration improves accuracy but still falls well short of text and introduces characteristic grounding/consistency errors. Failure analyses further show distinct error signatures across native streaming, end-to-end, and cascade designs. VERA provides a reproducible testbed and targeted diagnostics for architectures that decouple thinking from speaking, offering a principled way to measure progress toward real-time voice assistants that are both fluent and reliably reasoned.
CoreMatching: A Co-adaptive Sparse Inference Framework with Token and Neuron Pruning for Comprehensive Acceleration of Vision-Language Models
May 25, 2025Vision-Language Models (VLMs) excel across diverse tasks but suffer from high inference costs in time and memory. Token sparsity mitigates inefficiencies in token usage, while neuron sparsity reduces high-dimensional computations, both offering promising solutions to enhance efficiency. Recently, these two sparsity paradigms have evolved largely in parallel, fostering the prevailing assumption that they function independently. However, a fundamental yet underexplored question remains: Do they truly operate in isolation, or is there a deeper underlying interplay that has yet to be uncovered? In this paper, we conduct the first comprehensive investigation into this question. By introducing and analyzing the matching mechanism between Core Neurons and Core Tokens, we found that key neurons and tokens for inference mutually influence and reinforce each other. Building on this insight, we propose CoreMatching, a co-adaptive sparse inference framework, which leverages the synergy between token and neuron sparsity to enhance inference efficiency. Through theoretical analysis and efficiency evaluations, we demonstrate that the proposed method surpasses state-of-the-art baselines on ten image understanding tasks and three hardware devices. Notably, on the NVIDIA Titan Xp, it achieved 5x FLOPs reduction and a 10x overall speedup. Code is released at https://github.com/wangqinsi1/2025-ICML-CoreMatching/tree/main.
HippoMM: Hippocampal-inspired Multimodal Memory for Long Audiovisual Event Understanding
Apr 14, 2025Comprehending extended audiovisual experiences remains a fundamental challenge for computational systems. Current approaches struggle with temporal integration and cross-modal associations that humans accomplish effortlessly through hippocampal-cortical networks. We introduce HippoMM, a biologically-inspired architecture that transforms hippocampal mechanisms into computational advantages for multimodal understanding. HippoMM implements three key innovations: (i) hippocampus-inspired pattern separation and completion specifically designed for continuous audiovisual streams, (ii) short-to-long term memory consolidation that transforms perceptual details into semantic abstractions, and (iii) cross-modal associative retrieval pathways enabling modality-crossing queries. Unlike existing retrieval systems with static indexing schemes, HippoMM dynamically forms integrated episodic representations through adaptive temporal segmentation and dual-process memory encoding. Evaluations on our challenging HippoVlog benchmark demonstrate that HippoMM significantly outperforms state-of-the-art approaches (78.2% vs. 64.2% accuracy) while providing substantially faster response times (20.4s vs. 112.5s). Our results demonstrate that translating neuroscientific memory principles into computational architectures provides a promising foundation for next-generation multimodal understanding systems. The code and benchmark dataset are publicly available at https://github.com/linyueqian/HippoMM.
Keyframe-oriented Vision Token Pruning: Enhancing Efficiency of Large Vision Language Models on Long-Form Video Processing
Mar 13, 2025Vision language models (VLMs) demonstrate strong capabilities in jointly processing visual and textual data. However, they often incur substantial computational overhead due to redundant visual information, particularly in long-form video scenarios. Existing approaches predominantly focus on either vision token pruning, which may overlook spatio-temporal dependencies, or keyframe selection, which identifies informative frames but discards others, thus disrupting contextual continuity. In this work, we propose KVTP (Keyframe-oriented Vision Token Pruning), a novel framework that overcomes the drawbacks of token pruning and keyframe selection. By adaptively assigning pruning rates based on frame relevance to the query, KVTP effectively retains essential contextual information while significantly reducing redundant computation. To thoroughly evaluate the long-form video understanding capacities of VLMs, we curated and reorganized subsets from VideoMME, EgoSchema, and NextQA into a unified benchmark named SparseKV-QA that highlights real-world scenarios with sparse but crucial events. Our experiments with VLMs of various scales show that KVTP can reduce token usage by 80% without compromising spatiotemporal and contextual consistency, significantly cutting computation while maintaining the performance. These results demonstrate our approach's effectiveness in efficient long-video processing, facilitating more scalable VLM deployment.
H-CoT: Hijacking the Chain-of-Thought Safety Reasoning Mechanism to Jailbreak Large Reasoning Models, Including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking
Feb 18, 2025



Large Reasoning Models (LRMs) have recently extended their powerful reasoning capabilities to safety checks-using chain-of-thought reasoning to decide whether a request should be answered. While this new approach offers a promising route for balancing model utility and safety, its robustness remains underexplored. To address this gap, we introduce Malicious-Educator, a benchmark that disguises extremely dangerous or malicious requests beneath seemingly legitimate educational prompts. Our experiments reveal severe security flaws in popular commercial-grade LRMs, including OpenAI o1/o3, DeepSeek-R1, and Gemini 2.0 Flash Thinking. For instance, although OpenAI's o1 model initially maintains a high refusal rate of about 98%, subsequent model updates significantly compromise its safety; and attackers can easily extract criminal strategies from DeepSeek-R1 and Gemini 2.0 Flash Thinking without any additional tricks. To further highlight these vulnerabilities, we propose Hijacking Chain-of-Thought (H-CoT), a universal and transferable attack method that leverages the model's own displayed intermediate reasoning to jailbreak its safety reasoning mechanism. Under H-CoT, refusal rates sharply decline-dropping from 98% to below 2%-and, in some instances, even transform initially cautious tones into ones that are willing to provide harmful content. We hope these findings underscore the urgent need for more robust safety mechanisms to preserve the benefits of advanced reasoning capabilities without compromising ethical standards.
Dobi-SVD: Differentiable SVD for LLM Compression and Some New Perspectives
Feb 04, 2025



We provide a new LLM-compression solution via SVD, unlocking new possibilities for LLM compression beyond quantization and pruning. We point out that the optimal use of SVD lies in truncating activations, rather than merely using activations as an optimization distance. Building on this principle, we address three critical challenges in SVD-based LLM compression: including (1) How can we determine the optimal activation truncation position for each weight matrix in LLMs? (2) How can we efficiently reconstruct the weight matrices based on truncated activations? (3) How can we address the inherent "injection" nature that results in the information loss of the SVD? We propose Dobi-SVD, which establishes a new, principled approach to SVD-based LLM compression.
CoreInfer: Accelerating Large Language Model Inference with Semantics-Inspired Adaptive Sparse Activation
Oct 23, 2024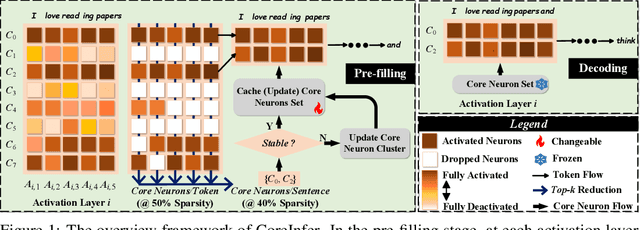

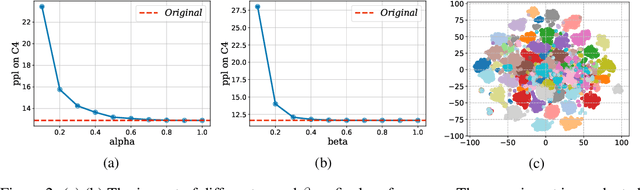

Large language models (LLMs) with billions of parameters have sparked a new wave of exciting AI applications. However, their high computational costs and memory demands during inference pose significant challenges. Adaptive sparse activation inference, which activates only a small number of neurons for each token, offers a novel way to accelerate model inference without degrading performance, showing great potential for resource-constrained hardware devices. Nevertheless, existing methods predict activated neurons based on individual tokens with additional MLP, which involve frequent changes in activation maps and resource calls, limiting the acceleration benefits of sparse activation. In this paper, we introduce CoreInfer, an MLP-free adaptive sparse activation inference method based on sentence-level prediction. Specifically, we propose the concept of sentence-wise core neurons, which refers to the subset of neurons most critical for a given sentence, and empirically demonstrate its effectiveness. To determine the core neurons, we explore the correlation between core neurons and the sentence's semantics. Remarkably, we discovered that core neurons exhibit both stability and similarity in relation to the sentence's semantics -- an insight overlooked by previous studies. Building on this finding, we further design two semantic-based methods for predicting core neurons to fit different input scenarios. In CoreInfer, the core neurons are determined during the pre-filling stage and fixed during the encoding stage, enabling zero-cost sparse inference. We evaluated the model generalization and task generalization of CoreInfer across various models and tasks. Notably, on an NVIDIA TITAN XP GPU, CoreInfer achieved a 10.33 times and 2.72 times speedup compared to the Huggingface implementation and PowerInfer, respectively.
Diff-Transfer: Model-based Robotic Manipulation Skill Transfer via Differentiable Physics Simulation
Oct 10, 2023



The capability to transfer mastered skills to accomplish a range of similar yet novel tasks is crucial for intelligent robots. In this work, we introduce $\textit{Diff-Transfer}$, a novel framework leveraging differentiable physics simulation to efficiently transfer robotic skills. Specifically, $\textit{Diff-Transfer}$ discovers a feasible path within the task space that brings the source task to the target task. At each pair of adjacent points along this task path, which is two sub-tasks, $\textit{Diff-Transfer}$ adapts known actions from one sub-task to tackle the other sub-task successfully. The adaptation is guided by the gradient information from differentiable physics simulations. We propose a novel path-planning method to generate sub-tasks, leveraging $Q$-learning with a task-level state and reward. We implement our framework in simulation experiments and execute four challenging transfer tasks on robotic manipulation, demonstrating the efficacy of $\textit{Diff-Transfer}$ through comprehensive experiments. Supplementary and Videos are on the website https://sites.google.com/view/difftransfer