 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Contact Sensing for Robust Robot-to-Human Object Handover
May 06, 2026Robot-to-human object handover is an essential skill for robot assistants, from serving drinks at home to passing surgical tools in the operating room. We expect robots to perform handover robustly -- to release the object only after a firm human grasp while ignoring incidental touches. Existing passive-sensing methods struggle to generalize across diverse objects and human behaviors, as they lack informative perturbations to disambiguate different contact conditions, such as firm grasp versus incidental touch. We propose an active sensing approach for robust handovers: the robot applies information-gathering motions and senses the resulting human-applied forces to infer the contact state. A firm grasp produces forces in multiple directions, while an accidental touch does not. To capture this distinction, we model the contact state with a Bayesian linear model: a distribution over piecewise-linear mappings from robot motions to human-applied forces. This model enables firm grasp detection and active information gathering. In experiments with 12 participants and 30 diverse rigid objects, our method achieved a 97.5% success rate -- over 30% higher than two common baselines.
FingerEye: Continuous and Unified Vision-Tactile Sensing for Dexterous Manipulation
Apr 22, 2026Dexterous robotic manipulation requires comprehensive perception across all phases of interaction: pre-contact, contact initiation, and post-contact. Such continuous feedback allows a robot to adapt its actions throughout interaction. However, many existing tactile sensors, such as GelSight and its variants, only provide feedback after contact is established, limiting a robot's ability to precisely initiate contact. We introduce FingerEye, a compact and cost-effective sensor that provides continuous vision-tactile feedback throughout the interaction process. FingerEye integrates binocular RGB cameras to provide close-range visual perception with implicit stereo depth. Upon contact, external forces and torques deform a compliant ring structure; these deformations are captured via marker-based pose estimation and serve as a proxy for contact wrench sensing. This design enables a perception stream that smoothly transitions from pre-contact visual cues to post-contact tactile feedback. Building on this sensing capability, we develop a vision-tactile imitation learning policy that fuses signals from multiple FingerEye sensors to learn dexterous manipulation behaviors from limited real-world data. We further develop a digital twin of our sensor and robot platform to improve policy generalization. By combining real demonstrations with visually augmented simulated observations for representation learning, the learned policies become more robust to object appearance variations. Together, these design aspects enable dexterous manipulation across diverse object properties and interaction regimes, including coin standing, chip picking, letter retrieving, and syringe manipulation. The hardware design, code, appendix, and videos are available on our project website: https://nus-lins-lab.github.io/FingerEyeWeb/
Contact Coverage-Guided Exploration for General-Purpose Dexterous Manipulation
Mar 11, 2026Deep Reinforcement learning (DRL) has achieved remarkable success in domains with well-defined reward structures, such as Atari games and locomotion. In contrast, dexterous manipulation lacks general-purpose reward formulations and typically depends on task-specific, handcrafted priors to guide hand-object interactions. We propose Contact Coverage-Guided Exploration (CCGE), a general exploration method designed for general-purpose dexterous manipulation tasks. CCGE represents contact state as the intersection between object surface points and predefined hand keypoints, encouraging dexterous hands to discover diverse and novel contact patterns, namely which fingers contact which object regions. It maintains a contact counter conditioned on discretized object states obtained via learned hash codes, capturing how frequently each finger interacts with different object regions. This counter is leveraged in two complementary ways: (1) to assign a count-based contact coverage reward that promotes exploration of novel contact patterns, and (2) an energy-based reaching reward that guides the agent toward under-explored contact regions. We evaluate CCGE on a diverse set of dexterous manipulation tasks, including cluttered object singulation, constrained object retrieval, in-hand reorientation, and bimanual manipulation. Experimental results show that CCGE substantially improves training efficiency and success rates over existing exploration methods, and that the contact patterns learned with CCGE transfer robustly to real-world robotic systems. Project page is https://contact-coverage-guided-exploration.github.io.
Towards Human-Like Manipulation through RL-Augmented Teleoperation and Mixture-of-Dexterous-Experts VLA
Mar 09, 2026While Vision-Language-Action (VLA) models have demonstrated remarkable success in robotic manipulation, their application has largely been confined to low-degree-of-freedom end-effectors performing simple, vision-guided pick-and-place tasks. Extending these models to human-like, bimanual dexterous manipulation-specifically contact-rich in-hand operations-introduces critical challenges in high-fidelity data acquisition, multi-skill learning, and multimodal sensory fusion. In this paper, we propose an integrated framework to address these bottlenecks, built upon two components. First, we introduce IMCopilot (In-hand Manipulation Copilot), a suite of reinforcement learning-trained atomic skills that plays a dual role: it acts as a shared-autonomy assistant to simplify teleoperation data collection, and it serves as a callable low-level execution primitive for the VLA. Second, we present MoDE-VLA (Mixture-of-Dexterous-Experts VLA), an architecture that seamlessly integrates heterogeneous force and tactile modalities into a pretrained VLA backbone. By utilizing a residual injection mechanism, MoDE-VLA enables contact-aware refinement without degrading the model's pretrained knowledge. We validate our approach on four tasks of escalating complexity, demonstrating doubled success rate improvement over the baseline in dexterous contact-rich tasks.
DexRepNet++: Learning Dexterous Robotic Manipulation with Geometric and Spatial Hand-Object Representations
Feb 25, 2026Robotic dexterous manipulation is a challenging problem due to high degrees of freedom (DoFs) and complex contacts of multi-fingered robotic hands. Many existing deep reinforcement learning (DRL) based methods aim at improving sample efficiency in high-dimensional output action spaces. However, existing works often overlook the role of representations in achieving generalization of a manipulation policy in the complex input space during the hand-object interaction. In this paper, we propose DexRep, a novel hand-object interaction representation to capture object surface features and spatial relations between hands and objects for dexterous manipulation skill learning. Based on DexRep, policies are learned for three dexterous manipulation tasks, i.e. grasping, in-hand reorientation, bimanual handover, and extensive experiments are conducted to verify the effectiveness. In simulation, for grasping, the policy learned with 40 objects achieves a success rate of 87.9% on more than 5000 unseen objects of diverse categories, significantly surpassing existing work trained with thousands of objects; for the in-hand reorientation and handover tasks, the policies also boost the success rates and other metrics of existing hand-object representations by 20% to 40%. The grasp policies with DexRep are deployed to the real world under multi-camera and single-camera setups and demonstrate a small sim-to-real gap.
* Accepted by IEEE Transactions on Robotics (T-RO), 2026
Bi-Adapt: Few-shot Bimanual Adaptation for Novel Categories of 3D Objects via Semantic Correspondence
Feb 09, 2026Bimanual manipulation is imperative yet challenging for robots to execute complex tasks, requiring coordinated collaboration between two arms. However, existing methods for bimanual manipulation often rely on costly data collection and training, struggling to generalize to unseen objects in novel categories efficiently. In this paper, we present Bi-Adapt, a novel framework designed for efficient generalization for bimanual manipulation via semantic correspondence. Bi-Adapt achieves cross-category affordance mapping by leveraging the strong capability of vision foundation models. Fine-tuning with restricted data on novel categories, Bi-Adapt exhibits notable generalization to out-of-category objects in a zero-shot manner. Extensive experiments conducted in both simulation and real-world environments validate the effectiveness of our approach and demonstrate its high efficiency, achieving a high success rate on different benchmark tasks across novel categories with limited data. Project website: https://biadapt-project.github.io/
DSVM-UNet : Enhancing VM-UNet with Dual Self-distillation for Medical Image Segmentation
Jan 27, 2026Vision Mamba models have been extensively researched in various fields, which address the limitations of previous models by effectively managing long-range dependencies with a linear-time overhead. Several prospective studies have further designed Vision Mamba based on UNet(VM-UNet) for medical image segmentation. These approaches primarily focus on optimizing architectural designs by creating more complex structures to enhance the model's ability to perceive semantic features. In this paper, we propose a simple yet effective approach to improve the model by Dual Self-distillation for VM-UNet (DSVM-UNet) without any complex architectural designs. To achieve this goal, we develop double self-distillation methods to align the features at both the global and local levels. Extensive experiments conducted on the ISIC2017, ISIC2018, and Synapse benchmarks demonstrate that our approach achieves state-of-the-art performance while maintaining computational efficiency. Code is available at https://github.com/RoryShao/DSVM-UNet.git.
* 5 pages, 1 figures
LiDARDraft: Generating LiDAR Point Cloud from Versatile Inputs
Dec 23, 2025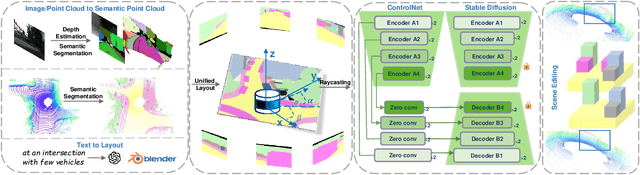
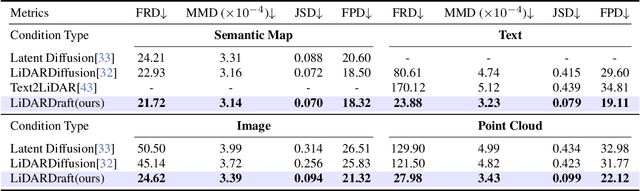
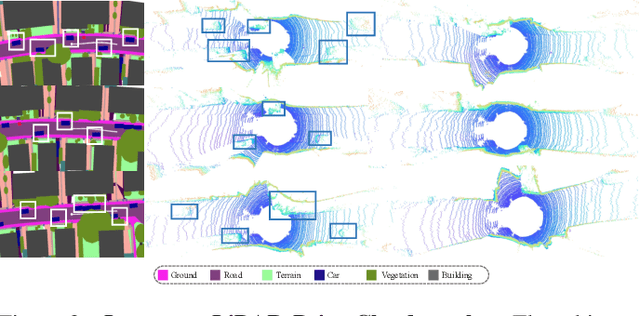
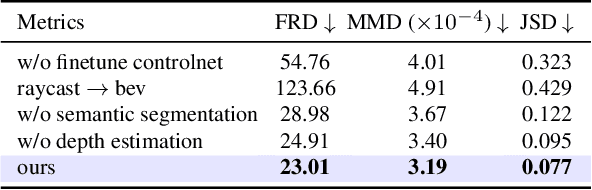
Generating realistic and diverse LiDAR point clouds is crucial for autonomous driving simulation. Although previous methods achieve LiDAR point cloud generation from user inputs, they struggle to attain high-quality results while enabling versatile controllability, due to the imbalance between the complex distribution of LiDAR point clouds and the simple control signals. To address the limitation, we propose LiDARDraft, which utilizes the 3D layout to build a bridge between versatile conditional signals and LiDAR point clouds. The 3D layout can be trivially generated from various user inputs such as textual descriptions and images. Specifically, we represent text, images, and point clouds as unified 3D layouts, which are further transformed into semantic and depth control signals. Then, we employ a rangemap-based ControlNet to guide LiDAR point cloud generation. This pixel-level alignment approach demonstrates excellent performance in controllable LiDAR point clouds generation, enabling "simulation from scratch", allowing self-driving environments to be created from arbitrary textual descriptions, images and sketches.
ManiLong-Shot: Interaction-Aware One-Shot Imitation Learning for Long-Horizon Manipulation
Dec 18, 2025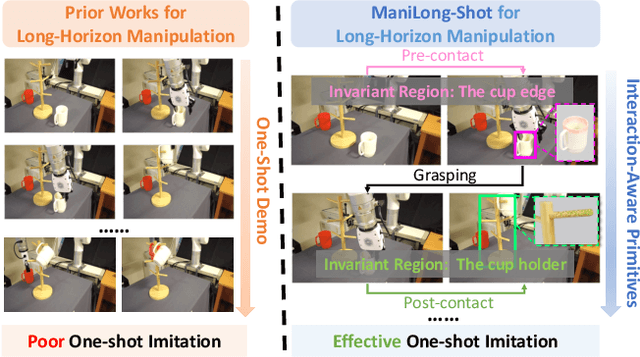

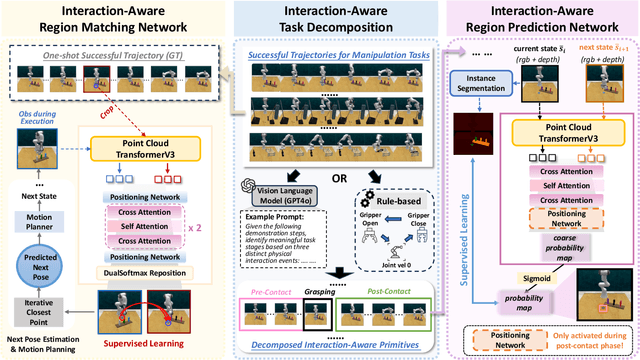
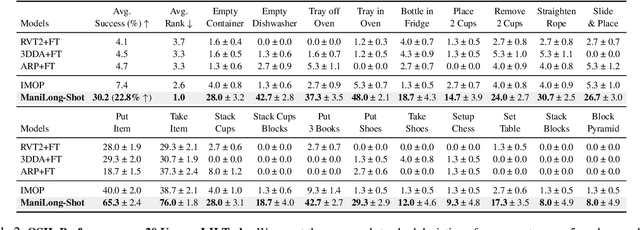
One-shot imitation learning (OSIL) offers a promising way to teach robots new skills without large-scale data collection. However, current OSIL methods are primarily limited to short-horizon tasks, thus limiting their applicability to complex, long-horizon manipulations. To address this limitation, we propose ManiLong-Shot, a novel framework that enables effective OSIL for long-horizon prehensile manipulation tasks. ManiLong-Shot structures long-horizon tasks around physical interaction events, reframing the problem as sequencing interaction-aware primitives instead of directly imitating continuous trajectories. This primitive decomposition can be driven by high-level reasoning from a vision-language model (VLM) or by rule-based heuristics derived from robot state changes. For each primitive, ManiLong-Shot predicts invariant regions critical to the interaction, establishes correspondences between the demonstration and the current observation, and computes the target end-effector pose, enabling effective task execution. Extensive simulation experiments show that ManiLong-Shot, trained on only 10 short-horizon tasks, generalizes to 20 unseen long-horizon tasks across three difficulty levels via one-shot imitation, achieving a 22.8% relative improvement over the SOTA. Additionally, real-robot experiments validate ManiLong-Shot's ability to robustly execute three long-horizon manipulation tasks via OSIL, confirming its practical applicability.
LISN: Language-Instructed Social Navigation with VLM-based Controller Modulating
Dec 10, 2025Towards human-robot coexistence, socially aware navigation is significant for mobile robots. Yet existing studies on this area focus mainly on path efficiency and pedestrian collision avoidance, which are essential but represent only a fraction of social navigation. Beyond these basics, robots must also comply with user instructions, aligning their actions to task goals and social norms expressed by humans. In this work, we present LISN-Bench, the first simulation-based benchmark for language-instructed social navigation. Built on Rosnav-Arena 3.0, it is the first standardized social navigation benchmark to incorporate instruction following and scene understanding across diverse contexts. To address this task, we further propose Social-Nav-Modulator, a fast-slow hierarchical system where a VLM agent modulates costmaps and controller parameters. Decoupling low-level action generation from the slower VLM loop reduces reliance on high-frequency VLM inference while improving dynamic avoidance and perception adaptability. Our method achieves an average success rate of 91.3%, which is greater than 63% than the most competitive baseline, with most of the improvements observed in challenging tasks such as following a person in a crowd and navigating while strictly avoiding instruction-forbidden regions. The project website is at: https://social-nav.github.io/LISN-project/