 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptPNP: Integrating Prehensile and Non-Prehensile Skills for Adaptive Robotic Manipulation
Nov 14, 2025Non-prehensile (NP) manipulation, in which robots alter object states without forming stable grasps (for example, pushing, poking, or sliding), significantly broadens robotic manipulation capabilities when grasping is infeasible or insufficient. However, enabling a unified framework that generalizes across different tasks, objects, and environments while seamlessly integrating non-prehensile and prehensile (P) actions remains challenging: robots must determine when to invoke NP skills, select the appropriate primitive for each context, and compose P and NP strategies into robust, multi-step plans. We introduce ApaptPNP, a vision-language model (VLM)-empowered task and motion planning framework that systematically selects and combines P and NP skills to accomplish diverse manipulation objectives. Our approach leverages a VLM to interpret visual scene observations and textual task descriptions, generating a high-level plan skeleton that prescribes the sequence and coordination of P and NP actions. A digital-twin based object-centric intermediate layer predicts desired object poses, enabling proactive mental rehearsal of manipulation sequences. Finally, a control module synthesizes low-level robot commands, with continuous execution feedback enabling online task plan refinement and adaptive replanning through the VLM. We evaluate ApaptPNP across representative P&NP hybrid manipulation tasks in both simulation and real-world environments. These results underscore the potential of hybrid P&NP manipulation as a crucial step toward general-purpose, human-level robotic manipulation capabilities. Project Website: https://sites.google.com/view/adaptpnp/home
DexSinGrasp: Learning a Unified Policy for Dexterous Object Singulation and Grasping in Cluttered Environments
Apr 06, 2025Grasping objects in cluttered environments remains a fundamental yet challenging problem in robotic manipulation. While prior works have explored learning-based synergies between pushing and grasping for two-fingered grippers, few have leveraged the high degrees of freedom (DoF) in dexterous hands to perform efficient singulation for grasping in cluttered settings. In this work, we introduce DexSinGrasp, a unified policy for dexterous object singulation and grasping. DexSinGrasp enables high-dexterity object singulation to facilitate grasping, significantly improving efficiency and effectiveness in cluttered environments. We incorporate clutter arrangement curriculum learning to enhance success rates and generalization across diverse clutter conditions, while policy distillation enables a deployable vision-based grasping strategy. To evaluate our approach, we introduce a set of cluttered grasping tasks with varying object arrangements and occlusion levels. Experimental results show that our method outperforms baselines in both efficiency and grasping success rate, particularly in dense clutter. Codes, appendix, and videos are available on our project website https://nus-lins-lab.github.io/dexsingweb/.
MetaFold: Language-Guided Multi-Category Garment Folding Framework via Trajectory Generation and Foundation Model
Mar 11, 2025
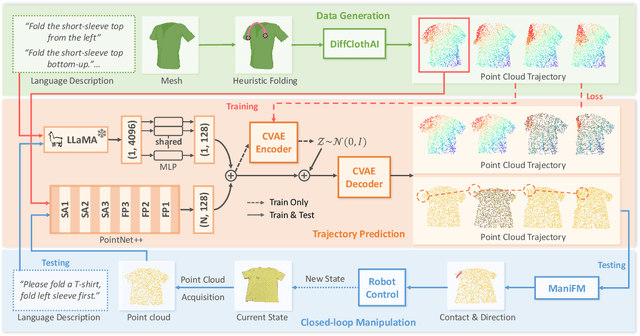

Garment folding is a common yet challenging task in robotic manipulation. The deformability of garments leads to a vast state space and complex dynamics, which complicates precise and fine-grained manipulation. Previous approaches often rely on predefined key points or demonstrations, limiting their generalization across diverse garment categories. This paper presents a framework, MetaFold, that disentangles task planning from action prediction, learning each independently to enhance model generalization. It employs language-guided point cloud trajectory generation for task planning and a low-level foundation model for action prediction. This structure facilitates multi-category learning, enabling the model to adapt flexibly to various user instructions and folding tasks. Experimental results demonstrate the superiority of our proposed framework. Supplementary materials are available on our website: https://meta-fold.github.io/.
TelePhantom: A User-Friendly Teleoperation System with Virtual Assistance for Enhanced Effectiveness
Dec 18, 2024



Dexterous manipulation is a critical area of robotics. In this field, teleoperation faces three key challenges: user-friendliness for novices, safety assurance, and transferability across different platforms. While collecting real robot dexterous manipulation data by teleoperation to train robots has shown impressive results on diverse tasks, due to the morphological differences between human and robot hands, it is not only hard for new users to understand the action mapping but also raises potential safety concerns during operation. To address these limitations, we introduce TelePhantom. This teleoperation system offers real-time visual feedback on robot actions based on human user inputs, with a total hardware cost of less than $1,000. TelePhantom allows the user to see a virtual robot that represents the outcome of the user's next movement. By enabling flexible switching between command visualization and actual execution, this system helps new users learn how to demonstrate quickly and safely. We demonstrate its superiority over other teleoperation systems across five tasks, emphasize its ease of use, and highlight its ease of deployment across diverse input sensors and robotic platforms. We will release our code and a deployment document on our website: https://telephantom.github.io/.
$\mathcal{D(R,O)}$ Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
Oct 02, 2024



Dexterous grasping is a fundamental yet challenging skill in robotic manipulation, requiring precise interaction between robotic hands and objects. In this paper, we present $\mathcal{D(R,O)}$ Grasp, a novel framework that models the interaction between the robotic hand in its grasping pose and the object, enabling broad generalization across various robot hands and object geometries. Our model takes the robot hand's description and object point cloud as inputs and efficiently predicts kinematically valid and stable grasps, demonstrating strong adaptability to diverse robot embodiments and object geometries. Extensive experiments conducted in both simulated and real-world environments validate the effectiveness of our approach, with significant improvements in success rate, grasp diversity, and inference speed across multiple robotic hands. Our method achieves an average success rate of 87.53% in simulation in less than one second, tested across three different dexterous robotic hands. In real-world experiments using the LeapHand, the method also demonstrates an average success rate of 89%. $\mathcal{D(R,O)}$ Grasp provides a robust solution for dexterous grasping in complex and varied environments. The code, appendix, and videos are available on our project website at https://nus-lins-lab.github.io/drograspweb/.
MASQ: Multi-Agent Reinforcement Learning for Single Quadruped Robot Locomotion
Aug 25, 2024

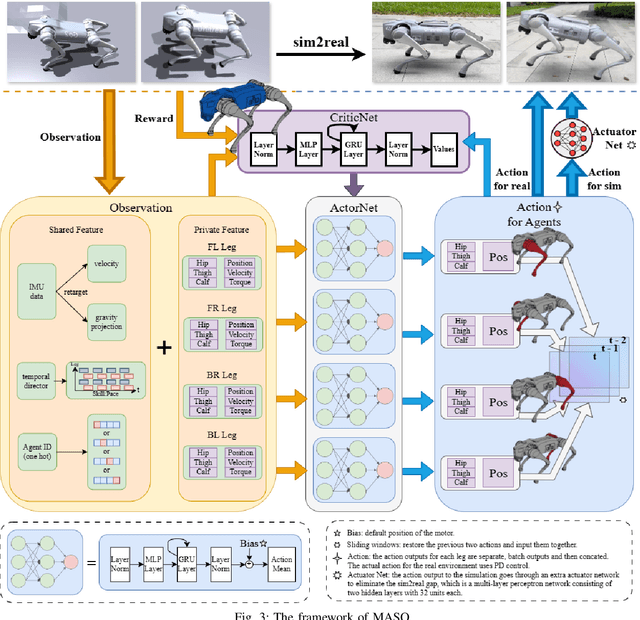
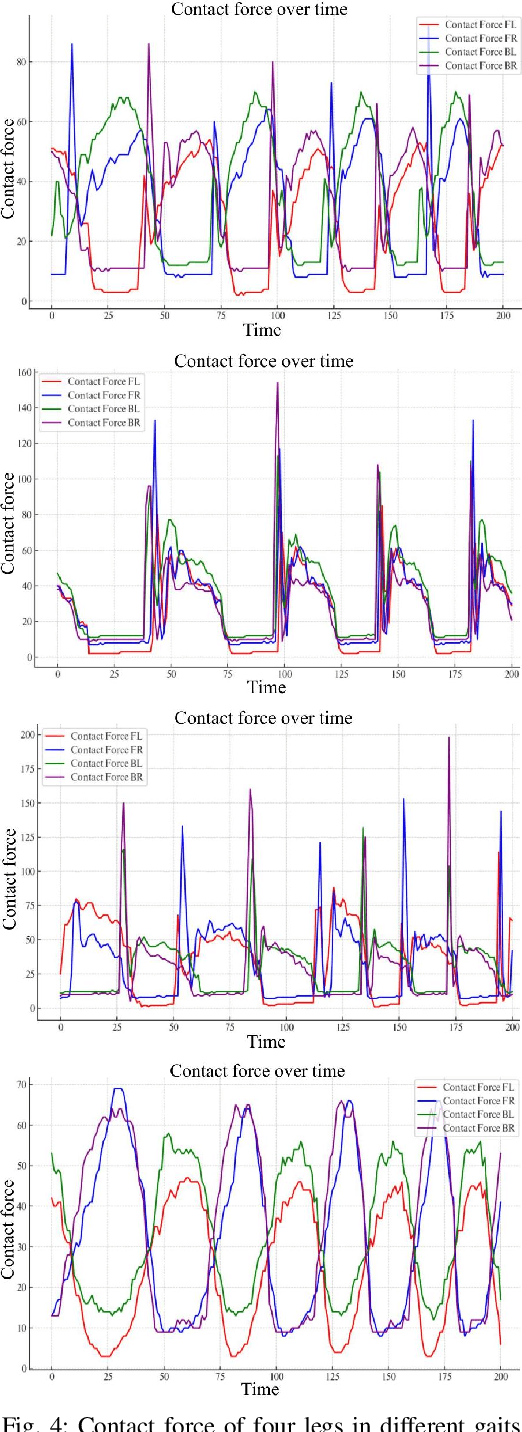
This paper proposes a novel method to improve locomotion learning for a single quadruped robot using multi-agent deep reinforcement learning (MARL). Many existing methods use single-agent reinforcement learning for an individual robot or MARL for the cooperative task in multi-robot systems. Unlike existing methods, this paper proposes using MARL for the locomotion learning of a single quadruped robot. We develop a learning structure called Multi-Agent Reinforcement Learning for Single Quadruped Robot Locomotion (MASQ), considering each leg as an agent to explore the action space of the quadruped robot, sharing a global critic, and learning collaboratively. Experimental results indicate that MASQ not only speeds up learning convergence but also enhances robustness in real-world settings, suggesting that applying MASQ to single robots such as quadrupeds could surpass traditional single-robot reinforcement learning approaches. Our study provides insightful guidance on integrating MARL with single-robot locomotion learning.
Multi-Agent Target Assignment and Path Finding for Intelligent Warehouse: A Cooperative Multi-Agent Deep Reinforcement Learning Perspective
Aug 25, 2024



Multi-agent target assignment and path planning (TAPF) are two key problems in intelligent warehouse. However, most literature only addresses one of these two problems separately. In this study, we propose a method to simultaneously solve target assignment and path planning from a perspective of cooperative multi-agent deep reinforcement learning (RL). To the best of our knowledge, this is the first work to model the TAPF problem for intelligent warehouse to cooperative multi-agent deep RL, and the first to simultaneously address TAPF based on multi-agent deep RL. Furthermore, previous literature rarely considers the physical dynamics of agents. In this study, the physical dynamics of the agents is considered. Experimental results show that our method performs well in various task settings, which means that the target assignment is solved reasonably well and the planned path is almost shortest. Moreover, our method is more time-efficient than baselines.