 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Vision Overrides Language: Evaluating and Mitigating Counterfactual Failures in VLAs
Feb 19, 2026Vision-Language-Action models (VLAs) promise to ground language instructions in robot control, yet in practice often fail to faithfully follow language. When presented with instructions that lack strong scene-specific supervision, VLAs suffer from counterfactual failures: they act based on vision shortcuts induced by dataset biases, repeatedly executing well-learned behaviors and selecting objects frequently seen during training regardless of language intent. To systematically study it, we introduce LIBERO-CF, the first counterfactual benchmark for VLAs that evaluates language following capability by assigning alternative instructions under visually plausible LIBERO layouts. Our evaluation reveals that counterfactual failures are prevalent yet underexplored across state-of-the-art VLAs. We propose Counterfactual Action Guidance (CAG), a simple yet effective dual-branch inference scheme that explicitly regularizes language conditioning in VLAs. CAG combines a standard VLA policy with a language-unconditioned Vision-Action (VA) module, enabling counterfactual comparison during action selection. This design reduces reliance on visual shortcuts, improves robustness on under-observed tasks, and requires neither additional demonstrations nor modifications to existing architectures or pretrained models. Extensive experiments demonstrate its plug-and-play integration across diverse VLAs and consistent improvements. For example, on LIBERO-CF, CAG improves $π_{0.5}$ by 9.7% in language following accuracy and 3.6% in task success on under-observed tasks using a training-free strategy, with further gains of 15.5% and 8.5%, respectively, when paired with a VA model. In real-world evaluations, CAG reduces counterfactual failures of 9.4% and improves task success by 17.2% on average.
One Hand to Rule Them All: Canonical Representations for Unified Dexterous Manipulation
Feb 18, 2026Dexterous manipulation policies today largely assume fixed hand designs, severely restricting their generalization to new embodiments with varied kinematic and structural layouts. To overcome this limitation, we introduce a parameterized canonical representation that unifies a broad spectrum of dexterous hand architectures. It comprises a unified parameter space and a canonical URDF format, offering three key advantages. 1) The parameter space captures essential morphological and kinematic variations for effective conditioning in learning algorithms. 2) A structured latent manifold can be learned over our space, where interpolations between embodiments yield smooth and physically meaningful morphology transitions. 3) The canonical URDF standardizes the action space while preserving dynamic and functional properties of the original URDFs, enabling efficient and reliable cross-embodiment policy learning. We validate these advantages through extensive analysis and experiments, including grasp policy replay, VAE latent encoding, and cross-embodiment zero-shot transfer. Specifically, we train a VAE on the unified representation to obtain a compact, semantically rich latent embedding, and develop a grasping policy conditioned on the canonical representation that generalizes across dexterous hands. We demonstrate, through simulation and real-world tasks on unseen morphologies (e.g., 81.9% zero-shot success rate on 3-finger LEAP Hand), that our framework unifies both the representational and action spaces of structurally diverse hands, providing a scalable foundation for cross-hand learning toward universal dexterous manipulation.
Coordinated guidance and control for multiple parafoil system landing
May 24, 2025
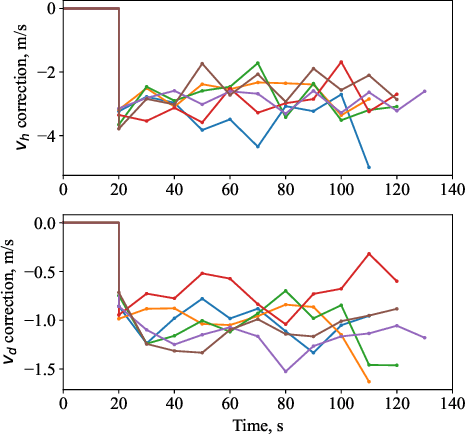
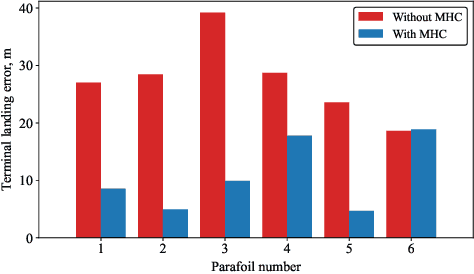
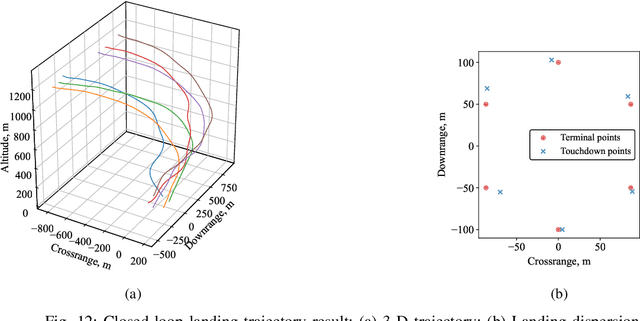
Multiple parafoil landing is an enabling technology for massive supply delivery missions. However, it is still an open question to design a collision-free, computation-efficient guidance and control method for unpowered parafoils. To address this issue, this paper proposes a coordinated guidance and control method for multiple parafoil landing. First, the multiple parafoil landing process is formulated as a trajectory optimization problem. Then, the landing point allocation algorithm is designed to assign the landing point to each parafoil. In order to guarantee flight safety, the collision-free trajectory replanning algorithm is designed. On this basis, the nonlinear model predictive control algorithm is adapted to leverage the nonlinear dynamics model for trajectory tracking. Finally, the parafoil kinematic model is utilized to reduce the computational burden of trajectory calculation, and kinematic model is updated by the moving horizon correction algorithm to improve the trajectory accuracy. Simulation results demonstrate the effectiveness and computational efficiency of the proposed coordinated guidance and control method for the multiple parafoil landing.
MetaFold: Language-Guided Multi-Category Garment Folding Framework via Trajectory Generation and Foundation Model
Mar 11, 2025
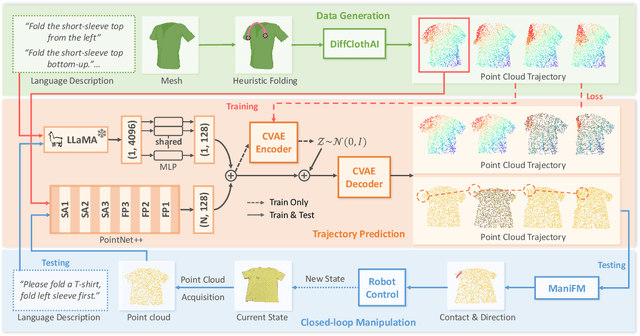
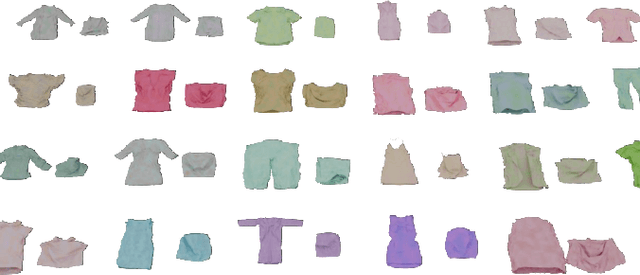

Garment folding is a common yet challenging task in robotic manipulation. The deformability of garments leads to a vast state space and complex dynamics, which complicates precise and fine-grained manipulation. Previous approaches often rely on predefined key points or demonstrations, limiting their generalization across diverse garment categories. This paper presents a framework, MetaFold, that disentangles task planning from action prediction, learning each independently to enhance model generalization. It employs language-guided point cloud trajectory generation for task planning and a low-level foundation model for action prediction. This structure facilitates multi-category learning, enabling the model to adapt flexibly to various user instructions and folding tasks. Experimental results demonstrate the superiority of our proposed framework. Supplementary materials are available on our website: https://meta-fold.github.io/.
TelePhantom: A User-Friendly Teleoperation System with Virtual Assistance for Enhanced Effectiveness
Dec 18, 2024



Dexterous manipulation is a critical area of robotics. In this field, teleoperation faces three key challenges: user-friendliness for novices, safety assurance, and transferability across different platforms. While collecting real robot dexterous manipulation data by teleoperation to train robots has shown impressive results on diverse tasks, due to the morphological differences between human and robot hands, it is not only hard for new users to understand the action mapping but also raises potential safety concerns during operation. To address these limitations, we introduce TelePhantom. This teleoperation system offers real-time visual feedback on robot actions based on human user inputs, with a total hardware cost of less than $1,000. TelePhantom allows the user to see a virtual robot that represents the outcome of the user's next movement. By enabling flexible switching between command visualization and actual execution, this system helps new users learn how to demonstrate quickly and safely. We demonstrate its superiority over other teleoperation systems across five tasks, emphasize its ease of use, and highlight its ease of deployment across diverse input sensors and robotic platforms. We will release our code and a deployment document on our website: https://telephantom.github.io/.
$\mathcal{D(R,O)}$ Grasp: A Unified Representation of Robot and Object Interaction for Cross-Embodiment Dexterous Grasping
Oct 02, 2024



Dexterous grasping is a fundamental yet challenging skill in robotic manipulation, requiring precise interaction between robotic hands and objects. In this paper, we present $\mathcal{D(R,O)}$ Grasp, a novel framework that models the interaction between the robotic hand in its grasping pose and the object, enabling broad generalization across various robot hands and object geometries. Our model takes the robot hand's description and object point cloud as inputs and efficiently predicts kinematically valid and stable grasps, demonstrating strong adaptability to diverse robot embodiments and object geometries. Extensive experiments conducted in both simulated and real-world environments validate the effectiveness of our approach, with significant improvements in success rate, grasp diversity, and inference speed across multiple robotic hands. Our method achieves an average success rate of 87.53% in simulation in less than one second, tested across three different dexterous robotic hands. In real-world experiments using the LeapHand, the method also demonstrates an average success rate of 89%. $\mathcal{D(R,O)}$ Grasp provides a robust solution for dexterous grasping in complex and varied environments. The code, appendix, and videos are available on our project website at https://nus-lins-lab.github.io/drograspweb/.
Enhanced Object Tracking by Self-Supervised Auxiliary Depth Estimation Learning
May 23, 2024



RGB-D tracking significantly improves the accuracy of object tracking. However, its dependency on real depth inputs and the complexity involved in multi-modal fusion limit its applicability across various scenarios. The utilization of depth information in RGB-D tracking inspired us to propose a new method, named MDETrack, which trains a tracking network with an additional capability to understand the depth of scenes, through supervised or self-supervised auxiliary Monocular Depth Estimation learning. The outputs of MDETrack's unified feature extractor are fed to the side-by-side tracking head and auxiliary depth estimation head, respectively. The auxiliary module will be discarded in inference, thus keeping the same inference speed. We evaluated our models with various training strategies on multiple datasets, and the results show an improved tracking accuracy even without real depth. Through these findings we highlight the potential of depth estimation in enhancing object tracking performance.
QUAR-VLA: Vision-Language-Action Model for Quadruped Robots
Dec 22, 2023
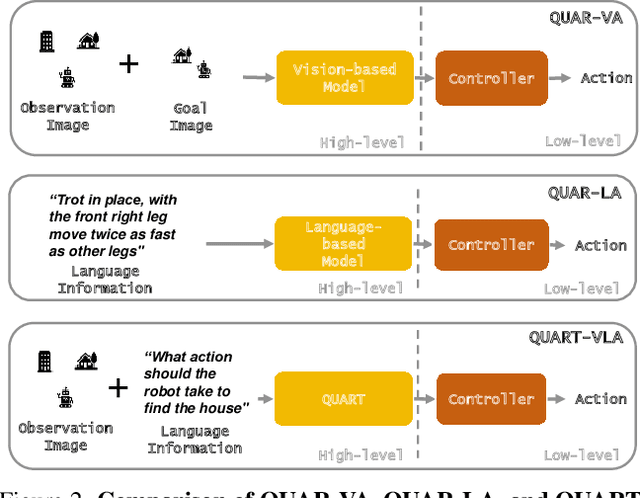

The important manifestation of robot intelligence is the ability to naturally interact and autonomously make decisions. Traditional approaches to robot control often compartmentalize perception, planning, and decision-making, simplifying system design but limiting the synergy between different information streams. This compartmentalization poses challenges in achieving seamless autonomous reasoning, decision-making, and action execution. To address these limitations, a novel paradigm, named Vision-Language-Action tasks for QUAdruped Robots (QUAR-VLA), has been introduced in this paper. This approach tightly integrates visual information and instructions to generate executable actions, effectively merging perception, planning, and decision-making. The central idea is to elevate the overall intelligence of the robot. Within this framework, a notable challenge lies in aligning fine-grained instructions with visual perception information. This emphasizes the complexity involved in ensuring that the robot accurately interprets and acts upon detailed instructions in harmony with its visual observations. Consequently, we propose QUAdruped Robotic Transformer (QUART), a family of VLA models to integrate visual information and instructions from diverse modalities as input and generates executable actions for real-world robots and present QUAdruped Robot Dataset (QUARD), a large-scale multi-task dataset including navigation, complex terrain locomotion, and whole-body manipulation tasks for training QUART models. Our extensive evaluation (4000 evaluation trials) shows that our approach leads to performant robotic policies and enables QUART to obtain a range of emergent capabilities.
RSG: Fast Learning Adaptive Skills for Quadruped Robots by Skill Graph
Nov 10, 2023Developing robotic intelligent systems that can adapt quickly to unseen wild situations is one of the critical challenges in pursuing autonomous robotics. Although some impressive progress has been made in walking stability and skill learning in the field of legged robots, their ability to fast adaptation is still inferior to that of animals in nature. Animals are born with massive skills needed to survive, and can quickly acquire new ones, by composing fundamental skills with limited experience. Inspired by this, we propose a novel framework, named Robot Skill Graph (RSG) for organizing massive fundamental skills of robots and dexterously reusing them for fast adaptation. Bearing a structure similar to the Knowledge Graph (KG), RSG is composed of massive dynamic behavioral skills instead of static knowledge in KG and enables discovering implicit relations that exist in be-tween of learning context and acquired skills of robots, serving as a starting point for understanding subtle patterns existing in robots' skill learning. Extensive experimental results demonstrate that RSG can provide rational skill inference upon new tasks and environments and enable quadruped robots to adapt to new scenarios and learn new skills rapidly.
Beyond OOD State Actions: Supported Cross-Domain Offline Reinforcement Learning
Jun 22, 2023



Offline reinforcement learning (RL) aims to learn a policy using only pre-collected and fixed data. Although avoiding the time-consuming online interactions in RL, it poses challenges for out-of-distribution (OOD) state actions and often suffers from data inefficiency for training. Despite many efforts being devoted to addressing OOD state actions, the latter (data inefficiency) receives little attention in offline RL. To address this, this paper proposes the cross-domain offline RL, which assumes offline data incorporate additional source-domain data from varying transition dynamics (environments), and expects it to contribute to the offline data efficiency. To do so, we identify a new challenge of OOD transition dynamics, beyond the common OOD state actions issue, when utilizing cross-domain offline data. Then, we propose our method BOSA, which employs two support-constrained objectives to address the above OOD issues. Through extensive experiments in the cross-domain offline RL setting, we demonstrate BOSA can greatly improve offline data efficiency: using only 10\% of the target data, BOSA could achieve {74.4\%} of the SOTA offline RL performance that uses 100\% of the target data. Additionally, we also show BOSA can be effortlessly plugged into model-based offline RL and noising data augmentation techniques (used for generating source-domain data), which naturally avoids the potential dynamics mismatch between target-domain data and newly generated source-domain data.