 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNFPO: Stabilized Policy Optimization of Normalizing Flow for Robotic Policy Learning
Mar 12, 2026Deep Reinforcement Learning (DRL) has experienced significant advancements in recent years and has been widely used in many fields. In DRL-based robotic policy learning, however, current de facto policy parameterization is still multivariate Gaussian (with diagonal covariance matrix), which lacks the ability to model multi-modal distribution. In this work, we explore the adoption of a modern network architecture, i.e. Normalizing Flow (NF) as the policy parameterization for its ability of multi-modal modeling, closed form of log probability and low computation and memory overhead. However, naively training NF in online Reinforcement Learning (RL) usually leads to training instability. We provide a detailed analysis for this phenomenon and successfully address it via simple but effective technique. With extensive experiments in multiple simulation environments, we show our method, NFPO could obtain robust and strong performance in widely used robotic learning tasks and successfully transfer into real-world robots.
TDMPBC: Self-Imitative Reinforcement Learning for Humanoid Robot Control
Feb 24, 2025Complex high-dimensional spaces with high Degree-of-Freedom and complicated action spaces, such as humanoid robots equipped with dexterous hands, pose significant challenges for reinforcement learning (RL) algorithms, which need to wisely balance exploration and exploitation under limited sample budgets. In general, feasible regions for accomplishing tasks within complex high-dimensional spaces are exceedingly narrow. For instance, in the context of humanoid robot motion control, the vast majority of space corresponds to falling, while only a minuscule fraction corresponds to standing upright, which is conducive to the completion of downstream tasks. Once the robot explores into a potentially task-relevant region, it should place greater emphasis on the data within that region. Building on this insight, we propose the $\textbf{S}$elf-$\textbf{I}$mitative $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SIRL}$) framework, where the RL algorithm also imitates potentially task-relevant trajectories. Specifically, trajectory return is utilized to determine its relevance to the task and an additional behavior cloning is adopted whose weight is dynamically adjusted based on the trajectory return. As a result, our proposed algorithm achieves 120% performance improvement on the challenging HumanoidBench with 5% extra computation overhead. With further visualization, we find the significant performance gain does lead to meaningful behavior improvement that several tasks are solved successfully.
RSG: Fast Learning Adaptive Skills for Quadruped Robots by Skill Graph
Nov 10, 2023Developing robotic intelligent systems that can adapt quickly to unseen wild situations is one of the critical challenges in pursuing autonomous robotics. Although some impressive progress has been made in walking stability and skill learning in the field of legged robots, their ability to fast adaptation is still inferior to that of animals in nature. Animals are born with massive skills needed to survive, and can quickly acquire new ones, by composing fundamental skills with limited experience. Inspired by this, we propose a novel framework, named Robot Skill Graph (RSG) for organizing massive fundamental skills of robots and dexterously reusing them for fast adaptation. Bearing a structure similar to the Knowledge Graph (KG), RSG is composed of massive dynamic behavioral skills instead of static knowledge in KG and enables discovering implicit relations that exist in be-tween of learning context and acquired skills of robots, serving as a starting point for understanding subtle patterns existing in robots' skill learning. Extensive experimental results demonstrate that RSG can provide rational skill inference upon new tasks and environments and enable quadruped robots to adapt to new scenarios and learn new skills rapidly.
Beyond Reward: Offline Preference-guided Policy Optimization
May 25, 2023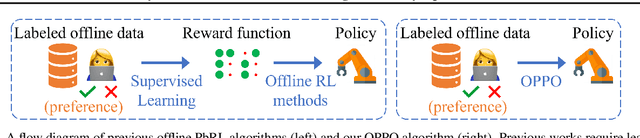
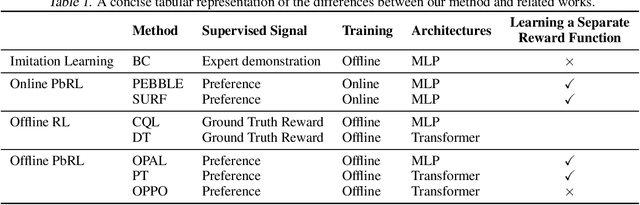
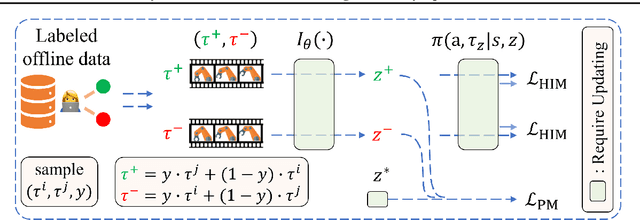
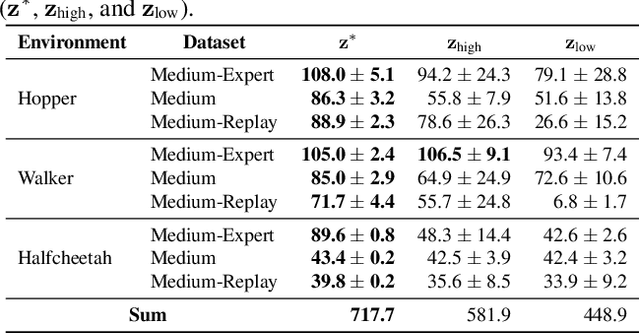
This study focuses on the topic of offline preference-based reinforcement learning (PbRL), a variant of conventional reinforcement learning that dispenses with the need for online interaction or specification of reward functions. Instead, the agent is provided with pre-existing offline trajectories and human preferences between pairs of trajectories to extract the dynamics and task information, respectively. Since the dynamics and task information are orthogonal, a naive approach would involve using preference-based reward learning followed by an off-the-shelf offline RL algorithm. However, this requires the separate learning of a scalar reward function, which is assumed to be an information bottleneck. To address this issue, we propose the offline preference-guided policy optimization (OPPO) paradigm, which models offline trajectories and preferences in a one-step process, eliminating the need for separately learning a reward function. OPPO achieves this by introducing an offline hindsight information matching objective for optimizing a contextual policy and a preference modeling objective for finding the optimal context. OPPO further integrates a well-performing decision policy by optimizing the two objectives iteratively. Our empirical results demonstrate that OPPO effectively models offline preferences and outperforms prior competing baselines, including offline RL algorithms performed over either true or pseudo reward function specifications. Our code is available at https://github.com/bkkgbkjb/OPPO .