 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld-Value-Action Model: Implicit Planning for Vision-Language-Action Systems
Apr 16, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for building embodied agents that ground perception and language into action. However, most existing approaches rely on direct action prediction, lacking the ability to reason over long-horizon trajectories and evaluate their consequences, which limits performance in complex decision-making tasks. In this work, we introduce World-Value-Action (WAV) model, a unified framework that enables implicit planning in VLA systems. Rather than performing explicit trajectory optimization, WAV model learn a structured latent representation of future trajectories conditioned on visual observations and language instructions. A learned world model predicts future states, while a trajectory value function evaluates their long-horizon utility. Action generation is then formulated as inference in this latent space, where the model progressively concentrates probability mass on high-value and dynamically feasible trajectories. We provide a theoretical perspective showing that planning directly in action space suffers from an exponential decay in the probability of feasible trajectories as the horizon increases. In contrast, latent-space inference reshapes the search distribution toward feasible regions, enabling efficient long-horizon decision making. Extensive simulations and real-world experiments demonstrate that the WAV model consistently outperforms state-of-the-art methods, achieving significant improvements in task success rate, generalization ability, and robustness, especially in long-horizon and compositional scenarios.
VAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
Mar 19, 2026Video action models are an appealing foundation for Vision--Language--Action systems because they can learn visual dynamics from large-scale video data and transfer this knowledge to downstream robot control. Yet current diffusion-based video predictors are trained with likelihood-surrogate objectives, which encourage globally plausible predictions without explicitly optimizing the precision-critical visual dynamics needed for manipulation. This objective mismatch often leads to subtle errors in object pose, spatial relations, and contact timing that can be amplified by downstream policies. We propose VAMPO, a post-training framework that directly improves visual dynamics in video action models through policy optimization. Our key idea is to formulate multi-step denoising as a sequential decision process and optimize the denoising policy with rewards defined over expert visual dynamics in latent space. To make this optimization practical, we introduce an Euler Hybrid sampler that injects stochasticity only at the first denoising step, enabling tractable low-variance policy-gradient estimation while preserving the coherence of the remaining denoising trajectory. We further combine this design with GRPO and a verifiable non-adversarial reward. Across diverse simulated and real-world manipulation tasks, VAMPO improves task-relevant visual dynamics, leading to better downstream action generation and stronger generalization. The homepage is https://vampo-robot.github.io/VAMPO/.
VORL-EXPLORE: A Hybrid Learning Planning Approach to Multi-Robot Exploration in Dynamic Environments
Mar 09, 2026Hierarchical multi-robot exploration commonly decouples frontier allocation from local navigation, which can make the system brittle in dense and dynamic environments. Because the allocator lacks direct awareness of execution difficulty, robots may cluster at bottlenecks, trigger oscillatory replanning, and generate redundant coverage. We propose VORL-EXPLORE, a hybrid learning and planning framework that addresses this limitation through execution fidelity, a shared estimate of local navigability that couples task allocation with motion execution. This fidelity signal is incorporated into a fidelity-coupled Voronoi objective with inter-robot repulsion to reduce contention before it emerges. It also drives a risk-aware adaptive arbitration mechanism between global A* guidance and a reactive reinforcement learning policy, balancing long-range efficiency with safe interaction in confined spaces. The framework further supports online self-supervised recalibration of the fidelity model using pseudo-labels derived from recent progress and safety outcomes, enabling adaptation to non-stationary obstacles without manual risk tuning. We evaluate this capability separately in a dedicated severe-traffic ablation. Extensive experiments in randomized grids and a Gazebo factory scenario show high success rates, shorter path length, lower overlap, and robust collision avoidance. The source code will be made publicly available upon acceptance.
CMR: Contractive Mapping Embeddings for Robust Humanoid Locomotion on Unstructured Terrains
Feb 03, 2026Robust disturbance rejection remains a longstanding challenge in humanoid locomotion, particularly on unstructured terrains where sensing is unreliable and model mismatch is pronounced. While perception information, such as height map, enhances terrain awareness, sensor noise and sim-to-real gaps can destabilize policies in practice. In this work, we provide theoretical analysis that bounds the return gap under observation noise, when the induced latent dynamics are contractive. Furthermore, we present Contractive Mapping for Robustness (CMR) framework that maps high-dimensional, disturbance-prone observations into a latent space, where local perturbations are attenuated over time. Specifically, this approach couples contrastive representation learning with Lipschitz regularization to preserve task-relevant geometry while explicitly controlling sensitivity. Notably, the formulation can be incorporated into modern deep reinforcement learning pipelines as an auxiliary loss term with minimal additional technical effort required. Further, our extensive humanoid experiments show that CMR potently outperforms other locomotion algorithms under increased noise.
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025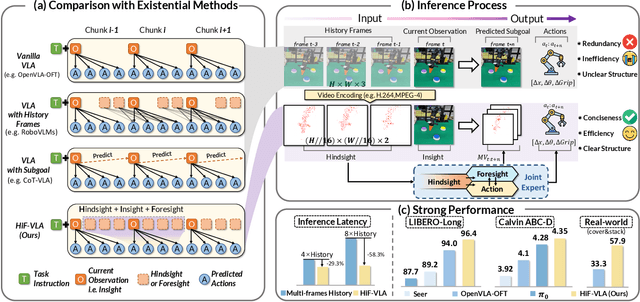
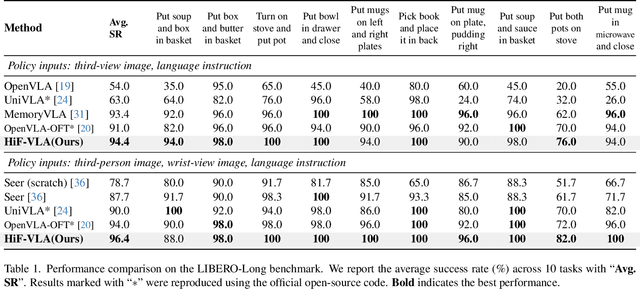
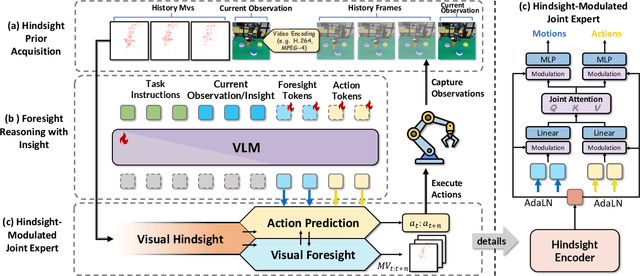
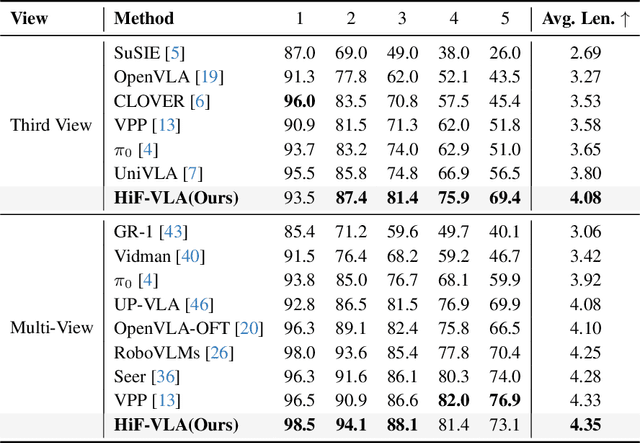
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
Integrating Trajectory Optimization and Reinforcement Learning for Quadrupedal Jumping with Terrain-Adaptive Landing
Sep 16, 2025Jumping constitutes an essential component of quadruped robots' locomotion capabilities, which includes dynamic take-off and adaptive landing. Existing quadrupedal jumping studies mainly focused on the stance and flight phase by assuming a flat landing ground, which is impractical in many real world cases. This work proposes a safe landing framework that achieves adaptive landing on rough terrains by combining Trajectory Optimization (TO) and Reinforcement Learning (RL) together. The RL agent learns to track the reference motion generated by TO in the environments with rough terrains. To enable the learning of compliant landing skills on challenging terrains, a reward relaxation strategy is synthesized to encourage exploration during landing recovery period. Extensive experiments validate the accurate tracking and safe landing skills benefiting from our proposed method in various scenarios.
Robust Online Residual Refinement via Koopman-Guided Dynamics Modeling
Sep 16, 2025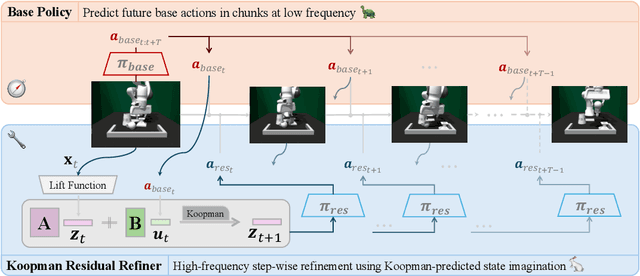
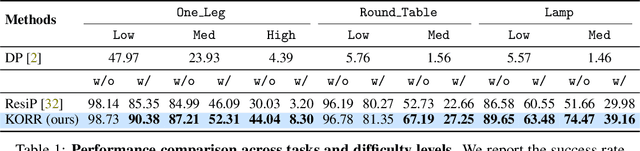


Imitation learning (IL) enables efficient skill acquisition from demonstrations but often struggles with long-horizon tasks and high-precision control due to compounding errors. Residual policy learning offers a promising, model-agnostic solution by refining a base policy through closed-loop corrections. However, existing approaches primarily focus on local corrections to the base policy, lacking a global understanding of state evolution, which limits robustness and generalization to unseen scenarios. To address this, we propose incorporating global dynamics modeling to guide residual policy updates. Specifically, we leverage Koopman operator theory to impose linear time-invariant structure in a learned latent space, enabling reliable state transitions and improved extrapolation for long-horizon prediction and unseen environments. We introduce KORR (Koopman-guided Online Residual Refinement), a simple yet effective framework that conditions residual corrections on Koopman-predicted latent states, enabling globally informed and stable action refinement. We evaluate KORR on long-horizon, fine-grained robotic furniture assembly tasks under various perturbations. Results demonstrate consistent gains in performance, robustness, and generalization over strong baselines. Our findings further highlight the potential of Koopman-based modeling to bridge modern learning methods with classical control theory.
Efficient Online RL Fine Tuning with Offline Pre-trained Policy Only
May 22, 2025Improving the performance of pre-trained policies through online reinforcement learning (RL) is a critical yet challenging topic. Existing online RL fine-tuning methods require continued training with offline pretrained Q-functions for stability and performance. However, these offline pretrained Q-functions commonly underestimate state-action pairs beyond the offline dataset due to the conservatism in most offline RL methods, which hinders further exploration when transitioning from the offline to the online setting. Additionally, this requirement limits their applicability in scenarios where only pre-trained policies are available but pre-trained Q-functions are absent, such as in imitation learning (IL) pre-training. To address these challenges, we propose a method for efficient online RL fine-tuning using solely the offline pre-trained policy, eliminating reliance on pre-trained Q-functions. We introduce PORL (Policy-Only Reinforcement Learning Fine-Tuning), which rapidly initializes the Q-function from scratch during the online phase to avoid detrimental pessimism. Our method not only achieves competitive performance with advanced offline-to-online RL algorithms and online RL approaches that leverage data or policies prior, but also pioneers a new path for directly fine-tuning behavior cloning (BC) policies.
Learning Robotic Policy with Imagined Transition: Mitigating the Trade-off between Robustness and Optimality
Mar 13, 2025Existing quadrupedal locomotion learning paradigms usually rely on extensive domain randomization to alleviate the sim2real gap and enhance robustness. It trains policies with a wide range of environment parameters and sensor noises to perform reliably under uncertainty. However, since optimal performance under ideal conditions often conflicts with the need to handle worst-case scenarios, there is a trade-off between optimality and robustness. This trade-off forces the learned policy to prioritize stability in diverse and challenging conditions over efficiency and accuracy in ideal ones, leading to overly conservative behaviors that sacrifice peak performance. In this paper, we propose a two-stage framework that mitigates this trade-off by integrating policy learning with imagined transitions. This framework enhances the conventional reinforcement learning (RL) approach by incorporating imagined transitions as demonstrative inputs. These imagined transitions are derived from an optimal policy and a dynamics model operating within an idealized setting. Our findings indicate that this approach significantly mitigates the domain randomization-induced negative impact of existing RL algorithms. It leads to accelerated training, reduced tracking errors within the distribution, and enhanced robustness outside the distribution.
TDMPBC: Self-Imitative Reinforcement Learning for Humanoid Robot Control
Feb 24, 2025Complex high-dimensional spaces with high Degree-of-Freedom and complicated action spaces, such as humanoid robots equipped with dexterous hands, pose significant challenges for reinforcement learning (RL) algorithms, which need to wisely balance exploration and exploitation under limited sample budgets. In general, feasible regions for accomplishing tasks within complex high-dimensional spaces are exceedingly narrow. For instance, in the context of humanoid robot motion control, the vast majority of space corresponds to falling, while only a minuscule fraction corresponds to standing upright, which is conducive to the completion of downstream tasks. Once the robot explores into a potentially task-relevant region, it should place greater emphasis on the data within that region. Building on this insight, we propose the $\textbf{S}$elf-$\textbf{I}$mitative $\textbf{R}$einforcement $\textbf{L}$earning ($\textbf{SIRL}$) framework, where the RL algorithm also imitates potentially task-relevant trajectories. Specifically, trajectory return is utilized to determine its relevance to the task and an additional behavior cloning is adopted whose weight is dynamically adjusted based on the trajectory return. As a result, our proposed algorithm achieves 120% performance improvement on the challenging HumanoidBench with 5% extra computation overhead. With further visualization, we find the significant performance gain does lead to meaningful behavior improvement that several tasks are solved successfully.