 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Online Residual Refinement via Koopman-Guided Dynamics Modeling
Sep 16, 2025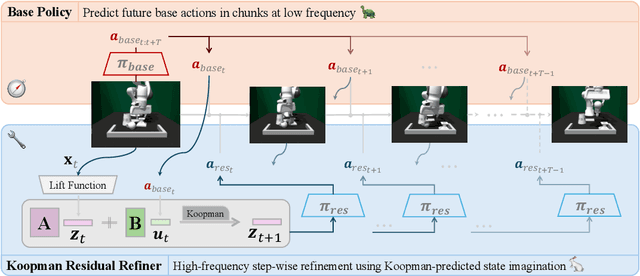
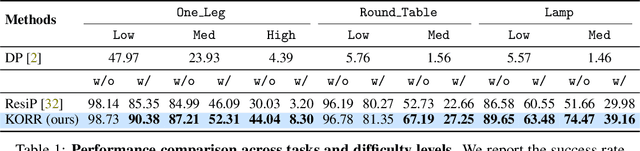


Imitation learning (IL) enables efficient skill acquisition from demonstrations but often struggles with long-horizon tasks and high-precision control due to compounding errors. Residual policy learning offers a promising, model-agnostic solution by refining a base policy through closed-loop corrections. However, existing approaches primarily focus on local corrections to the base policy, lacking a global understanding of state evolution, which limits robustness and generalization to unseen scenarios. To address this, we propose incorporating global dynamics modeling to guide residual policy updates. Specifically, we leverage Koopman operator theory to impose linear time-invariant structure in a learned latent space, enabling reliable state transitions and improved extrapolation for long-horizon prediction and unseen environments. We introduce KORR (Koopman-guided Online Residual Refinement), a simple yet effective framework that conditions residual corrections on Koopman-predicted latent states, enabling globally informed and stable action refinement. We evaluate KORR on long-horizon, fine-grained robotic furniture assembly tasks under various perturbations. Results demonstrate consistent gains in performance, robustness, and generalization over strong baselines. Our findings further highlight the potential of Koopman-based modeling to bridge modern learning methods with classical control theory.
Unveiling the Potential of Vision-Language-Action Models with Open-Ended Multimodal Instructions
May 16, 2025Vision-Language-Action (VLA) models have recently become highly prominent in the field of robotics. Leveraging vision-language foundation models trained on large-scale internet data, the VLA model can generate robotic actions directly from visual observations and human instructions through a single end-to-end neural network. Despite their effectiveness, current VLA models usually accept only one form of human prompting, language instructions, which may constrain their applicability in open-ended human-robot interactions. For example, a user might expect the robot to retrieve an object shown in an image, follow an instruction written on the whiteboard, or imitate a behavior demonstrated in a video, rather than relying solely on language-based descriptions. To address this gap, we introduce OE-VLA, which explores the potential of VLA models for open-ended multimodal instructions. Extensive results demonstrate that our OE-VLA not only achieves comparable performance to traditional VLA models with linguistic input but also delivers impressive results across four additional categories of open-ended tasks. The proposed methodology could significantly expand the applications of VLA models across various everyday scenarios and facilitate human-robot interaction.
Learning Robotic Policy with Imagined Transition: Mitigating the Trade-off between Robustness and Optimality
Mar 13, 2025Existing quadrupedal locomotion learning paradigms usually rely on extensive domain randomization to alleviate the sim2real gap and enhance robustness. It trains policies with a wide range of environment parameters and sensor noises to perform reliably under uncertainty. However, since optimal performance under ideal conditions often conflicts with the need to handle worst-case scenarios, there is a trade-off between optimality and robustness. This trade-off forces the learned policy to prioritize stability in diverse and challenging conditions over efficiency and accuracy in ideal ones, leading to overly conservative behaviors that sacrifice peak performance. In this paper, we propose a two-stage framework that mitigates this trade-off by integrating policy learning with imagined transitions. This framework enhances the conventional reinforcement learning (RL) approach by incorporating imagined transitions as demonstrative inputs. These imagined transitions are derived from an optimal policy and a dynamics model operating within an idealized setting. Our findings indicate that this approach significantly mitigates the domain randomization-induced negative impact of existing RL algorithms. It leads to accelerated training, reduced tracking errors within the distribution, and enhanced robustness outside the distribution.
VLAS: Vision-Language-Action Model With Speech Instructions For Customized Robot Manipulation
Feb 19, 2025Vision-language-action models (VLAs) have become increasingly popular in robot manipulation for their end-to-end design and remarkable performance. However, existing VLAs rely heavily on vision-language models (VLMs) that only support text-based instructions, neglecting the more natural speech modality for human-robot interaction. Traditional speech integration methods usually involves a separate speech recognition system, which complicates the model and introduces error propagation. Moreover, the transcription procedure would lose non-semantic information in the raw speech, such as voiceprint, which may be crucial for robots to successfully complete customized tasks. To overcome above challenges, we propose VLAS, a novel end-to-end VLA that integrates speech recognition directly into the robot policy model. VLAS allows the robot to understand spoken commands through inner speech-text alignment and produces corresponding actions to fulfill the task. We also present two new datasets, SQA and CSI, to support a three-stage tuning process for speech instructions, which empowers VLAS with the ability of multimodal interaction across text, image, speech, and robot actions. Taking a step further, a voice retrieval-augmented generation (RAG) paradigm is designed to enable our model to effectively handle tasks that require individual-specific knowledge. Our extensive experiments show that VLAS can effectively accomplish robot manipulation tasks with diverse speech commands, offering a seamless and customized interaction experience.
CARP: Visuomotor Policy Learning via Coarse-to-Fine Autoregressive Prediction
Dec 09, 2024



In robotic visuomotor policy learning, diffusion-based models have achieved significant success in improving the accuracy of action trajectory generation compared to traditional autoregressive models. However, they suffer from inefficiency due to multiple denoising steps and limited flexibility from complex constraints. In this paper, we introduce Coarse-to-Fine AutoRegressive Policy (CARP), a novel paradigm for visuomotor policy learning that redefines the autoregressive action generation process as a coarse-to-fine, next-scale approach. CARP decouples action generation into two stages: first, an action autoencoder learns multi-scale representations of the entire action sequence; then, a GPT-style transformer refines the sequence prediction through a coarse-to-fine autoregressive process. This straightforward and intuitive approach produces highly accurate and smooth actions, matching or even surpassing the performance of diffusion-based policies while maintaining efficiency on par with autoregressive policies. We conduct extensive evaluations across diverse settings, including single-task and multi-task scenarios on state-based and image-based simulation benchmarks, as well as real-world tasks. CARP achieves competitive success rates, with up to a 10% improvement, and delivers 10x faster inference compared to state-of-the-art policies, establishing a high-performance, efficient, and flexible paradigm for action generation in robotic tasks.