 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Potential of Vision-Language-Action Models with Open-Ended Multimodal Instructions
May 16, 2025Vision-Language-Action (VLA) models have recently become highly prominent in the field of robotics. Leveraging vision-language foundation models trained on large-scale internet data, the VLA model can generate robotic actions directly from visual observations and human instructions through a single end-to-end neural network. Despite their effectiveness, current VLA models usually accept only one form of human prompting, language instructions, which may constrain their applicability in open-ended human-robot interactions. For example, a user might expect the robot to retrieve an object shown in an image, follow an instruction written on the whiteboard, or imitate a behavior demonstrated in a video, rather than relying solely on language-based descriptions. To address this gap, we introduce OE-VLA, which explores the potential of VLA models for open-ended multimodal instructions. Extensive results demonstrate that our OE-VLA not only achieves comparable performance to traditional VLA models with linguistic input but also delivers impressive results across four additional categories of open-ended tasks. The proposed methodology could significantly expand the applications of VLA models across various everyday scenarios and facilitate human-robot interaction.
StyleTex: Style Image-Guided Texture Generation for 3D Models
Nov 01, 2024
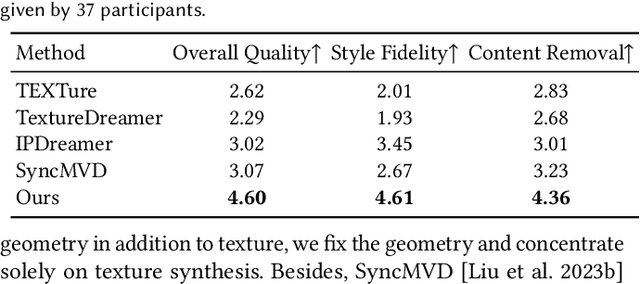
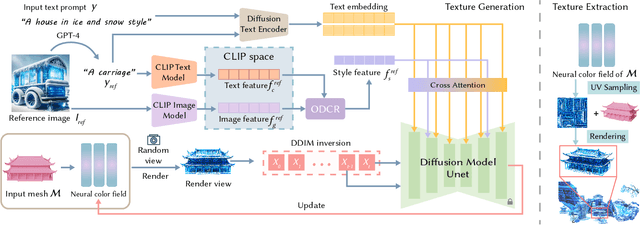
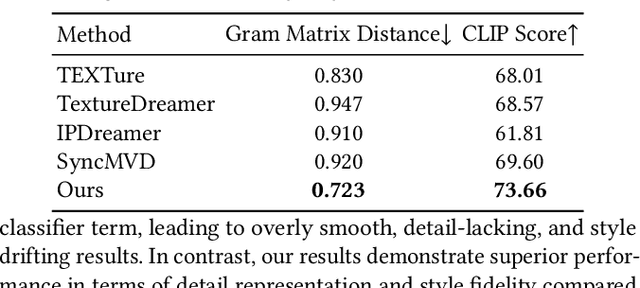
Style-guided texture generation aims to generate a texture that is harmonious with both the style of the reference image and the geometry of the input mesh, given a reference style image and a 3D mesh with its text description. Although diffusion-based 3D texture generation methods, such as distillation sampling, have numerous promising applications in stylized games and films, it requires addressing two challenges: 1) decouple style and content completely from the reference image for 3D models, and 2) align the generated texture with the color tone, style of the reference image, and the given text prompt. To this end, we introduce StyleTex, an innovative diffusion-model-based framework for creating stylized textures for 3D models. Our key insight is to decouple style information from the reference image while disregarding content in diffusion-based distillation sampling. Specifically, given a reference image, we first decompose its style feature from the image CLIP embedding by subtracting the embedding's orthogonal projection in the direction of the content feature, which is represented by a text CLIP embedding. Our novel approach to disentangling the reference image's style and content information allows us to generate distinct style and content features. We then inject the style feature into the cross-attention mechanism to incorporate it into the generation process, while utilizing the content feature as a negative prompt to further dissociate content information. Finally, we incorporate these strategies into StyleTex to obtain stylized textures. The resulting textures generated by StyleTex retain the style of the reference image, while also aligning with the text prompts and intrinsic details of the given 3D mesh. Quantitative and qualitative experiments show that our method outperforms existing baseline methods by a significant margin.
Promoting CNNs with Cross-Architecture Knowledge Distillation for Efficient Monocular Depth Estimation
Apr 25, 2024



Recently, the performance of monocular depth estimation (MDE) has been significantly boosted with the integration of transformer models. However, the transformer models are usually computationally-expensive, and their effectiveness in light-weight models are limited compared to convolutions. This limitation hinders their deployment on resource-limited devices. In this paper, we propose a cross-architecture knowledge distillation method for MDE, dubbed DisDepth, to enhance efficient CNN models with the supervision of state-of-the-art transformer models. Concretely, we first build a simple framework of convolution-based MDE, which is then enhanced with a novel local-global convolution module to capture both local and global information in the image. To effectively distill valuable information from the transformer teacher and bridge the gap between convolution and transformer features, we introduce a method to acclimate the teacher with a ghost decoder. The ghost decoder is a copy of the student's decoder, and adapting the teacher with the ghost decoder aligns the features to be student-friendly while preserving their original performance. Furthermore, we propose an attentive knowledge distillation loss that adaptively identifies features valuable for depth estimation. This loss guides the student to focus more on attentive regions, improving its performance. Extensive experiments on KITTI and NYU Depth V2 datasets demonstrate the effectiveness of DisDepth. Our method achieves significant improvements on various efficient backbones, showcasing its potential for efficient monocular depth estimation.