 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleTex: Style Image-Guided Texture Generation for 3D Models
Nov 01, 2024
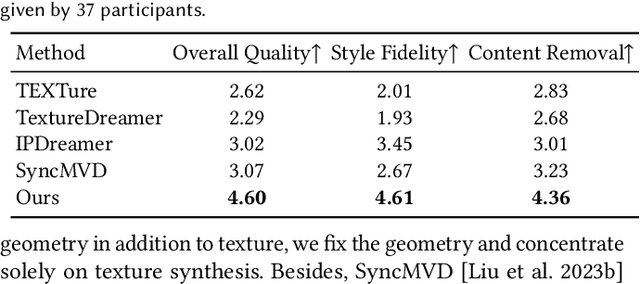
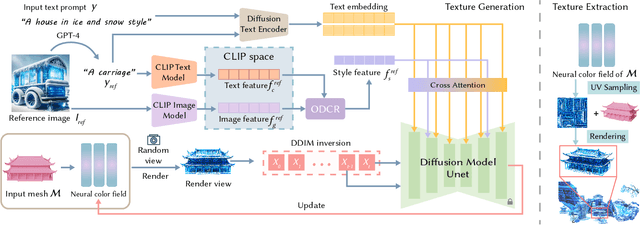
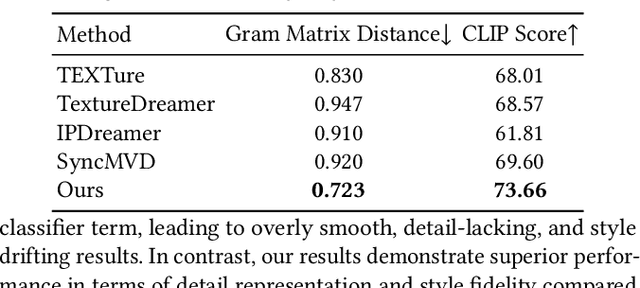
Style-guided texture generation aims to generate a texture that is harmonious with both the style of the reference image and the geometry of the input mesh, given a reference style image and a 3D mesh with its text description. Although diffusion-based 3D texture generation methods, such as distillation sampling, have numerous promising applications in stylized games and films, it requires addressing two challenges: 1) decouple style and content completely from the reference image for 3D models, and 2) align the generated texture with the color tone, style of the reference image, and the given text prompt. To this end, we introduce StyleTex, an innovative diffusion-model-based framework for creating stylized textures for 3D models. Our key insight is to decouple style information from the reference image while disregarding content in diffusion-based distillation sampling. Specifically, given a reference image, we first decompose its style feature from the image CLIP embedding by subtracting the embedding's orthogonal projection in the direction of the content feature, which is represented by a text CLIP embedding. Our novel approach to disentangling the reference image's style and content information allows us to generate distinct style and content features. We then inject the style feature into the cross-attention mechanism to incorporate it into the generation process, while utilizing the content feature as a negative prompt to further dissociate content information. Finally, we incorporate these strategies into StyleTex to obtain stylized textures. The resulting textures generated by StyleTex retain the style of the reference image, while also aligning with the text prompts and intrinsic details of the given 3D mesh. Quantitative and qualitative experiments show that our method outperforms existing baseline methods by a significant margin.