 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossViewDiff: A Cross-View Diffusion Model for Satellite-to-Street View Synthesis
Aug 27, 2024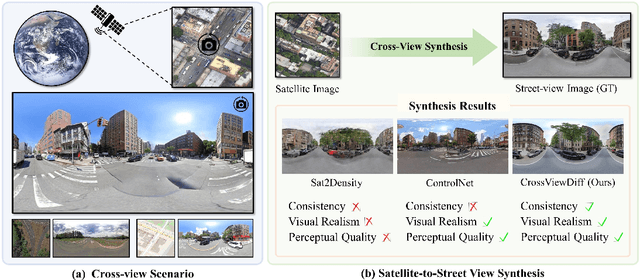
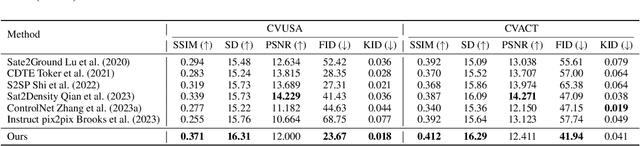


Satellite-to-street view synthesis aims at generating a realistic street-view image from its corresponding satellite-view image. Although stable diffusion models have exhibit remarkable performance in a variety of image generation applications, their reliance on similar-view inputs to control the generated structure or texture restricts their application to the challenging cross-view synthesis task. In this work, we propose CrossViewDiff, a cross-view diffusion model for satellite-to-street view synthesis. To address the challenges posed by the large discrepancy across views, we design the satellite scene structure estimation and cross-view texture mapping modules to construct the structural and textural controls for street-view image synthesis. We further design a cross-view control guided denoising process that incorporates the above controls via an enhanced cross-view attention module. To achieve a more comprehensive evaluation of the synthesis results, we additionally design a GPT-based scoring method as a supplement to standard evaluation metrics. We also explore the effect of different data sources (e.g., text, maps, building heights, and multi-temporal satellite imagery) on this task. Results on three public cross-view datasets show that CrossViewDiff outperforms current state-of-the-art on both standard and GPT-based evaluation metrics, generating high-quality street-view panoramas with more realistic structures and textures across rural, suburban, and urban scenes. The code and models of this work will be released at https://opendatalab.github.io/CrossViewDiff/.
Promoting CNNs with Cross-Architecture Knowledge Distillation for Efficient Monocular Depth Estimation
Apr 25, 2024



Recently, the performance of monocular depth estimation (MDE) has been significantly boosted with the integration of transformer models. However, the transformer models are usually computationally-expensive, and their effectiveness in light-weight models are limited compared to convolutions. This limitation hinders their deployment on resource-limited devices. In this paper, we propose a cross-architecture knowledge distillation method for MDE, dubbed DisDepth, to enhance efficient CNN models with the supervision of state-of-the-art transformer models. Concretely, we first build a simple framework of convolution-based MDE, which is then enhanced with a novel local-global convolution module to capture both local and global information in the image. To effectively distill valuable information from the transformer teacher and bridge the gap between convolution and transformer features, we introduce a method to acclimate the teacher with a ghost decoder. The ghost decoder is a copy of the student's decoder, and adapting the teacher with the ghost decoder aligns the features to be student-friendly while preserving their original performance. Furthermore, we propose an attentive knowledge distillation loss that adaptively identifies features valuable for depth estimation. This loss guides the student to focus more on attentive regions, improving its performance. Extensive experiments on KITTI and NYU Depth V2 datasets demonstrate the effectiveness of DisDepth. Our method achieves significant improvements on various efficient backbones, showcasing its potential for efficient monocular depth estimation.
SG-BEV: Satellite-Guided BEV Fusion for Cross-View Semantic Segmentation
Apr 03, 2024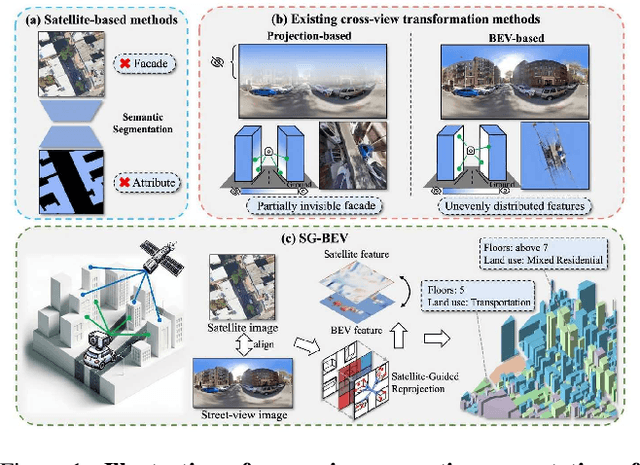

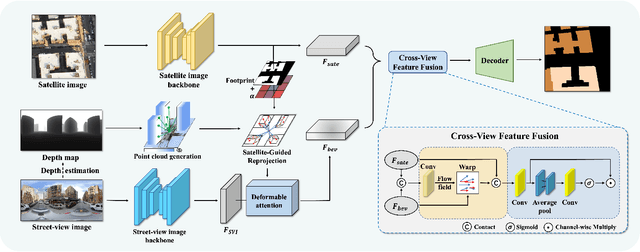

This paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using satellite and street-view image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code and datasets of this work will be released at https://github.com/yejy53/SG-BEV.