 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Embodied Chain-of-Thought for Generalizable Robot Manipulation
Jun 03, 2026Embodied chain-of-thought (CoT) aims to bridge linguistic reasoning and robotic control, but its effective form and integration strategy remain underexplored. In this paper, we revisit embodied CoT for vision-language-action (VLA) models at large scale. We construct the largest embodied CoT corpus to date, comprising 978,743 trajectories, 226.3M samples, and 2592.5 hours of robot data. Through extensive experiments, we find that effective embodied CoT should ground high-level semantic understanding into concrete action guidance, such as end-effector movement descriptions and image-space trajectories, while high-level reasoning alone brings only marginal gains. We further show that explicit CoT does not scale reliably when used as an autoregressive action prefix, as it suffers from compounding inference errors and unstable reasoning-action coupling. To address these limitations, we propose ERVLA, a VLA model that uses embodied CoT as representation-shaping supervision rather than mandatory test-time reasoning. ERVLA is trained with a reasoning-dropout strategy, enabling the model to absorb rich reasoning traces during training while predicting actions directly without CoT decoding during inference. This design improves scalability with increasing pre-training data and avoids autoregressive instability. ERVLA achieves state-of-the-art performance on LIBERO-Plus with an 86.9% success rate and reaches 53.2% success rate on VLABench, demonstrating strong out-of-distribution generalization. In real-robot experiments, ERVLA further outperforms competitive state-of-the-art baselines, especially on tasks requiring semantic disambiguation and long-horizon execution.
CUBic: Coordinated Unified Bimanual Perception and Control Framework
May 13, 2026Recent advances in visuomotor policy learning have enabled robots to perform control directly from visual inputs. Yet, extending such end-to-end learning from single-arm to bimanual manipulation remains challenging due to the need for both independent perception and coordinated interaction between arms. Existing methods typically favor one side -- either decoupling the two arms to avoid interference or enforcing strong cross-arm coupling for coordination -- thus lacking a unified treatment. We propose CUBic, a Coordinated and Unified framework for Bimanual perception and control that reformulates bimanual coordination as a unified perceptual modeling problem. CUBic learns a shared tokenized representation bridging perception and control, where independence and coordination emerge intrinsically from structure rather than from hand-crafted coupling. Our approach integrates three components: unidirectional perception aggregation, bidirectional perception coordination through two codebooks with shared mapping, and a unified perception-to-control diffusion policy. Extensive experiments on the RoboTwin benchmark show that CUBic consistently surpasses standard baselines, achieving marked improvements in coordination accuracy and task success rates over state-of-the-art visuomotor baselines.
CapVector: Learning Transferable Capability Vectors in Parametric Space for Vision-Language-Action Models
May 11, 2026This paper proposes a novel approach to address the challenge that pretrained VLA models often fail to effectively improve performance and reduce adaptation costs during standard supervised finetuning (SFT). Some advanced finetuning methods with auxiliary training objectives can improve performance and reduce the number of convergence steps. However, they typically incur significant computational overhead due to the additional losses from auxiliary objectives. To simultaneously achieve the enhanced capabilities of auxiliary training with the simplicity of standard SFT, we decouple the two objectives of auxiliary-objective SFT within the parameter space, namely, enhancing general capabilities and fitting task-specific action distributions. To deliver the goal, we only need to train the model to converge on a small-scale task set using two distinct training strategies, resulting in two finetuned models. The parameters' difference between the two models can then be interpreted as capability vectors provided by auxiliary objectives. These vectors are then merged with pretrained parameters to form a capability-enhanced meta model. Moreover, when standard SFT is augmented with a lightweight orthogonal regularization loss, the merged model attains performance comparable to auxiliary finetuned baselines with reduced computational overhead. Internal and external experiments demonstrate that our capability vectors (1) are effective and versatile across diverse models, (2) can generalize to novel environments and embodiments out of the box.
RoboMemArena: A Comprehensive and Challenging Robotic Memory Benchmark
May 11, 2026Memory is a critical component of robotic intelligence, as robots must rely on past observations and actions to accomplish long-horizon tasks in partially observable environments. However, existing robotic memory benchmarks still lack multimodal annotations for memory formation, provide limited task coverage and structural complexity, and remain restricted to simulation without real-world evaluation. We address this gap with RoboMemArena, a large-scale benchmark of 26 tasks, with average trajectory lengths exceeding 1,000 steps per task and 68.9% of subtasks being memory-dependent. The generation pipeline leverages a vision-language model (VLM) to design and compose subtasks, generates full trajectories through atomic functions, and provides memory-related annotations, including subtask instructions and native keyframe annotations, while paired real-world memory tasks support physical evaluation. We further design PrediMem, a dual-system VLA in which a high-level VLM planner manages a memory bank with recent and keyframe buffers and uses a predictive coding head to improve sensitivity to task dynamics. Extensive experiments on RoboMemArena show that PrediMem outperforms all baselines and provides insights into memory management, model architecture, and scaling laws for complex memory systems.
MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
Mar 27, 2026Vision-Language-Action (VLA) models aim to control robots for manipulation from visual observations and natural-language instructions. However, existing hierarchical and autoregressive paradigms often introduce architectural overhead, suffer from temporal inconsistency and long-horizon error accumulation, and lack a mechanism to capture environment dynamics without extra modules. To this end, we present MMaDA-VLA, a fully native pre-trained large diffusion VLA model that unifies multi-modal understanding and generation in a single framework. Our key idea is a native discrete diffusion formulation that embeds language, images, and continuous robot controls into one discrete token space and trains a single backbone with masked token denoising to jointly generate a future goal observation and an action chunk in parallel. Iterative denoising enables global, order-free refinement, improving long-horizon consistency while grounding actions in predicted future visual outcomes without auxiliary world models. Experiments across simulation benchmarks and real-world tasks show state-of-the-art performance, achieving 98.0% average success on LIBERO and 4.78 average length on CALVIN.
Fast-dVLA: Accelerating Discrete Diffusion VLA to Real-Time Performance
Mar 27, 2026This paper proposes a novel approach to address the challenge that pretrained VLA models often fail to effectively improve performance and reduce adaptation costs during standard supervised finetuning (SFT). Some advanced finetuning methods with auxiliary training objectives can improve performance and reduce the number of convergence steps. However, they typically incur significant computational overhead due to the additional losses from auxiliary tasks. To simultaneously achieve the enhanced capabilities of auxiliary training with the simplicity of standard SFT, we decouple the two objectives of auxiliary task training within the parameter space, namely, enhancing general capabilities and fitting task-specific action distributions. To deliver this goal, we only need to train the model to converge on a small-scale task set using two distinct training strategies. The difference between the resulting model parameters can then be interpreted as capability vectors provided by auxiliary tasks. These vectors are then merged with pretrained parameters to form a capability-enhanced meta model. Moreover, when standard SFT is augmented with a lightweight orthogonal regularization loss, the merged model attains performance comparable to auxiliary finetuned baselines with reduced computational overhead. Experimental results demonstrate that this approach is highly effective across diverse robot tasks. Project page: https://chris1220313648.github.io/Fast-dVLA/
VAMPO: Policy Optimization for Improving Visual Dynamics in Video Action Models
Mar 19, 2026Video action models are an appealing foundation for Vision--Language--Action systems because they can learn visual dynamics from large-scale video data and transfer this knowledge to downstream robot control. Yet current diffusion-based video predictors are trained with likelihood-surrogate objectives, which encourage globally plausible predictions without explicitly optimizing the precision-critical visual dynamics needed for manipulation. This objective mismatch often leads to subtle errors in object pose, spatial relations, and contact timing that can be amplified by downstream policies. We propose VAMPO, a post-training framework that directly improves visual dynamics in video action models through policy optimization. Our key idea is to formulate multi-step denoising as a sequential decision process and optimize the denoising policy with rewards defined over expert visual dynamics in latent space. To make this optimization practical, we introduce an Euler Hybrid sampler that injects stochasticity only at the first denoising step, enabling tractable low-variance policy-gradient estimation while preserving the coherence of the remaining denoising trajectory. We further combine this design with GRPO and a verifiable non-adversarial reward. Across diverse simulated and real-world manipulation tasks, VAMPO improves task-relevant visual dynamics, leading to better downstream action generation and stronger generalization. The homepage is https://vampo-robot.github.io/VAMPO/.
Rethinking the Practicality of Vision-language-action Model: A Comprehensive Benchmark and An Improved Baseline
Feb 26, 2026Vision-Language-Action (VLA) models have emerged as a generalist robotic agent. However, existing VLAs are hindered by excessive parameter scales, prohibitive pre-training requirements, and limited applicability to diverse embodiments. To improve the practicality of VLAs, we propose a comprehensive benchmark and an improved baseline. First, we propose CEBench, a new benchmark spanning diverse embodiments in both simulation and the real world with consideration of domain randomization. We collect 14.4k simulated trajectories and 1.6k real-world expert-curated trajectories to support training on CEBench. Second, using CEBench as our testbed, we study three critical aspects of VLAs' practicality and offer several key findings. Informed by these findings, we introduce LLaVA-VLA, a lightweight yet powerful VLA designed for practical deployment on consumer-grade GPUs. Architecturally, it integrates a compact VLM backbone with multi-view perception, proprioceptive tokenization, and action chunking. To eliminate reliance on costly pre-training, LLaVA-VLA adopts a two-stage training paradigm including post-training and fine-tuning. Furthermore, LLaVA-VLA extends the action space to unify navigation and manipulation. Experiments across embodiments demonstrate the capabilities of generalization and versatility of LLaVA-VLA , while real-world mobile manipulation experiments establish it as the first end-to-end VLA model for mobile manipulation. We will open-source all datasets, codes, and checkpoints upon acceptance to foster reproducibility and future research.
Embodied Robot Manipulation in the Era of Foundation Models: Planning and Learning Perspectives
Dec 28, 2025Recent advances in vision, language, and multimodal learning have substantially accelerated progress in robotic foundation models, with robot manipulation remaining a central and challenging problem. This survey examines robot manipulation from an algorithmic perspective and organizes recent learning-based approaches within a unified abstraction of high-level planning and low-level control. At the high level, we extend the classical notion of task planning to include reasoning over language, code, motion, affordances, and 3D representations, emphasizing their role in structured and long-horizon decision making. At the low level, we propose a training-paradigm-oriented taxonomy for learning-based control, organizing existing methods along input modeling, latent representation learning, and policy learning. Finally, we identify open challenges and prospective research directions related to scalability, data efficiency, multimodal physical interaction, and safety. Together, these analyses aim to clarify the design space of modern foundation models for robotic manipulation.
HiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025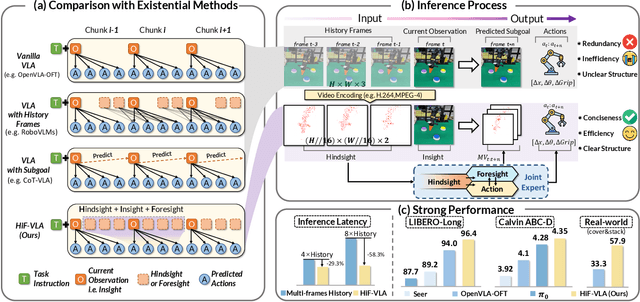
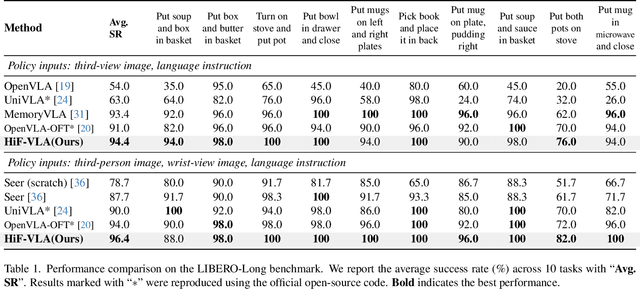
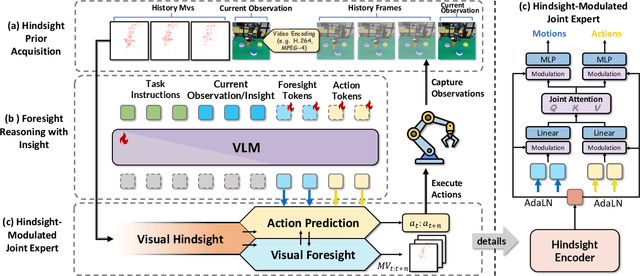
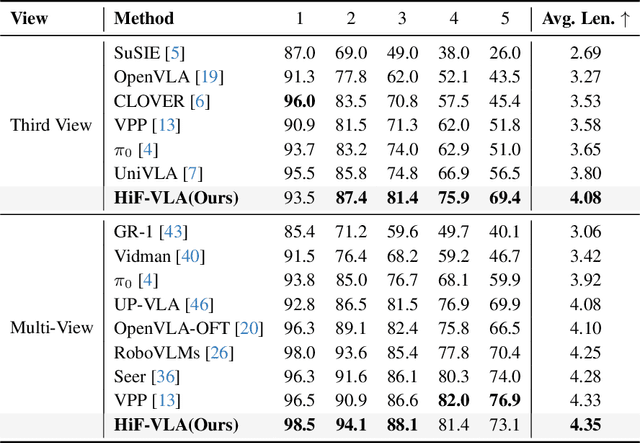
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.