 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFCPE: A Fast Context-based Pitch Estimation Model
Sep 18, 2025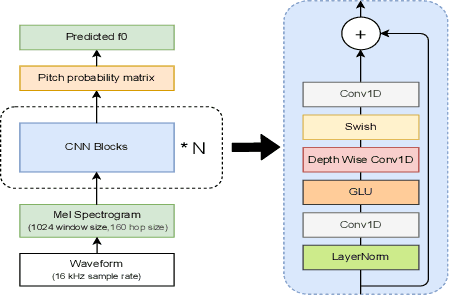
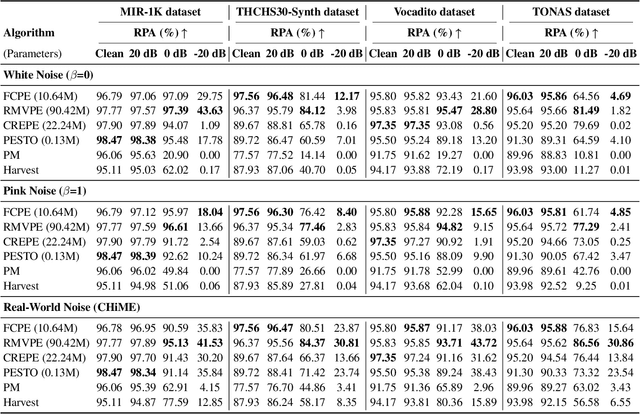
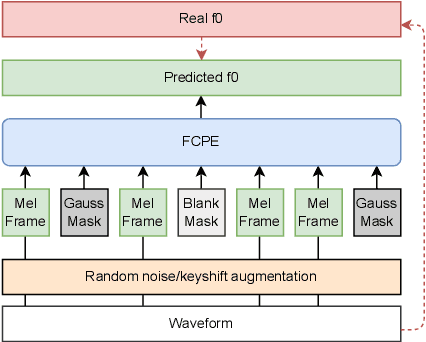

Pitch estimation (PE) in monophonic audio is crucial for MIDI transcription and singing voice conversion (SVC), but existing methods suffer significant performance degradation under noise. In this paper, we propose FCPE, a fast context-based pitch estimation model that employs a Lynx-Net architecture with depth-wise separable convolutions to effectively capture mel spectrogram features while maintaining low computational cost and robust noise tolerance. Experiments show that our method achieves 96.79\% Raw Pitch Accuracy (RPA) on the MIR-1K dataset, on par with the state-of-the-art methods. The Real-Time Factor (RTF) is 0.0062 on a single RTX 4090 GPU, which significantly outperforms existing algorithms in efficiency. Code is available at https://github.com/CNChTu/FCPE.
Rethinking Target Label Conditioning in Adversarial Attacks: A 2D Tensor-Guided Generative Approach
Apr 19, 2025Compared to single-target adversarial attacks, multi-target attacks have garnered significant attention due to their ability to generate adversarial images for multiple target classes simultaneously. Existing generative approaches for multi-target attacks mainly analyze the effect of the use of target labels on noise generation from a theoretical perspective, lacking practical validation and comprehensive summarization. To address this gap, we first identify and validate that the semantic feature quality and quantity are critical factors affecting the transferability of targeted attacks: 1) Feature quality refers to the structural and detailed completeness of the implanted target features, as deficiencies may result in the loss of key discriminative information; 2) Feature quantity refers to the spatial sufficiency of the implanted target features, as inadequacy limits the victim model's attention to this feature. Based on these findings, we propose the 2D Tensor-Guided Adversarial Fusion (2D-TGAF) framework, which leverages the powerful generative capabilities of diffusion models to encode target labels into two-dimensional semantic tensors for guiding adversarial noise generation. Additionally, we design a novel masking strategy tailored for the training process, ensuring that parts of the generated noise retain complete semantic information about the target class. Extensive experiments on the standard ImageNet dataset demonstrate that 2D-TGAF consistently surpasses state-of-the-art methods in attack success rates, both on normally trained models and across various defense mechanisms.
Analyzable Chain-of-Musical-Thought Prompting for High-Fidelity Music Generation
Mar 25, 2025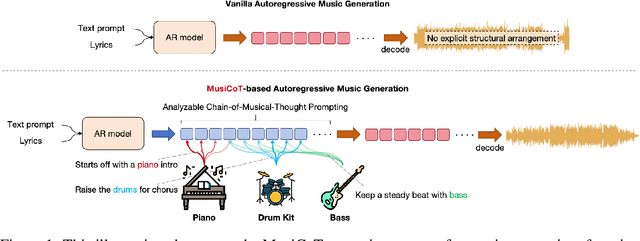
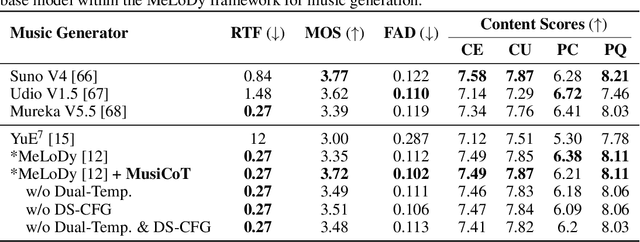
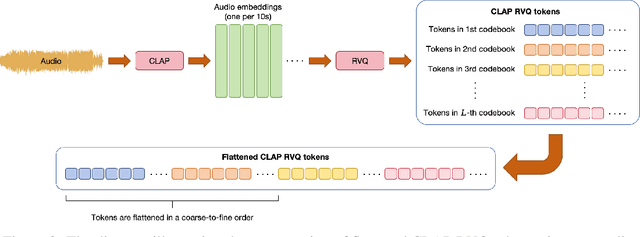
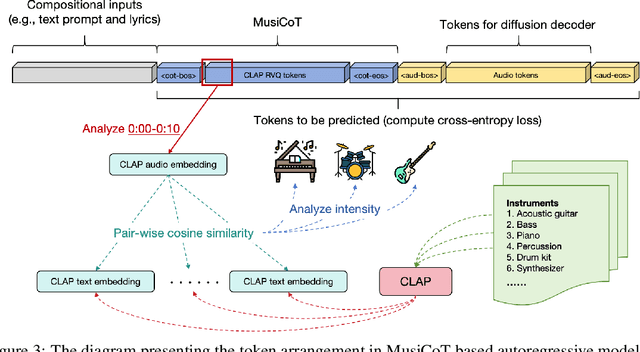
Autoregressive (AR) models have demonstrated impressive capabilities in generating high-fidelity music. However, the conventional next-token prediction paradigm in AR models does not align with the human creative process in music composition, potentially compromising the musicality of generated samples. To overcome this limitation, we introduce MusiCoT, a novel chain-of-thought (CoT) prompting technique tailored for music generation. MusiCoT empowers the AR model to first outline an overall music structure before generating audio tokens, thereby enhancing the coherence and creativity of the resulting compositions. By leveraging the contrastive language-audio pretraining (CLAP) model, we establish a chain of "musical thoughts", making MusiCoT scalable and independent of human-labeled data, in contrast to conventional CoT methods. Moreover, MusiCoT allows for in-depth analysis of music structure, such as instrumental arrangements, and supports music referencing -- accepting variable-length audio inputs as optional style references. This innovative approach effectively addresses copying issues, positioning MusiCoT as a vital practical method for music prompting. Our experimental results indicate that MusiCoT consistently achieves superior performance across both objective and subjective metrics, producing music quality that rivals state-of-the-art generation models. Our samples are available at https://MusiCoT.github.io/.
A Hybrid Defense Strategy for Boosting Adversarial Robustness in Vision-Language Models
Oct 18, 2024The robustness of Vision-Language Models (VLMs) such as CLIP is critical for their deployment in safety-critical applications like autonomous driving, healthcare diagnostics, and security systems, where accurate interpretation of visual and textual data is essential. However, these models are highly susceptible to adversarial attacks, which can severely compromise their performance and reliability in real-world scenarios. Previous methods have primarily focused on improving robustness through adversarial training and generating adversarial examples using models like FGSM, AutoAttack, and DeepFool. However, these approaches often rely on strong assumptions, such as fixed perturbation norms or predefined attack patterns, and involve high computational complexity, making them challenging to implement in practical settings. In this paper, we propose a novel adversarial training framework that integrates multiple attack strategies and advanced machine learning techniques to significantly enhance the robustness of VLMs against a broad range of adversarial attacks. Experiments conducted on real-world datasets, including CIFAR-10 and CIFAR-100, demonstrate that the proposed method significantly enhances model robustness. The fine-tuned CLIP model achieved an accuracy of 43.5% on adversarially perturbed images, compared to only 4% for the baseline model. The neural network model achieved a high accuracy of 98% in these challenging classification tasks, while the XGBoost model reached a success rate of 85.26% in prediction tasks.
An End-to-End Approach for Chord-Conditioned Song Generation
Sep 10, 2024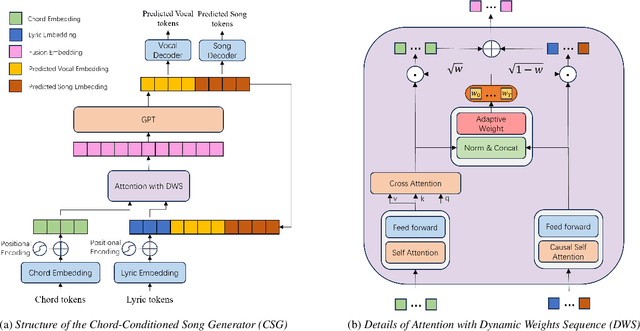
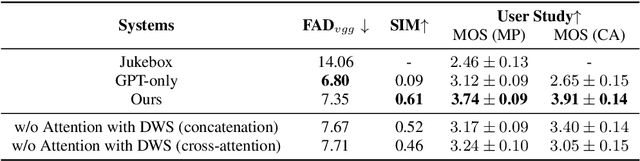
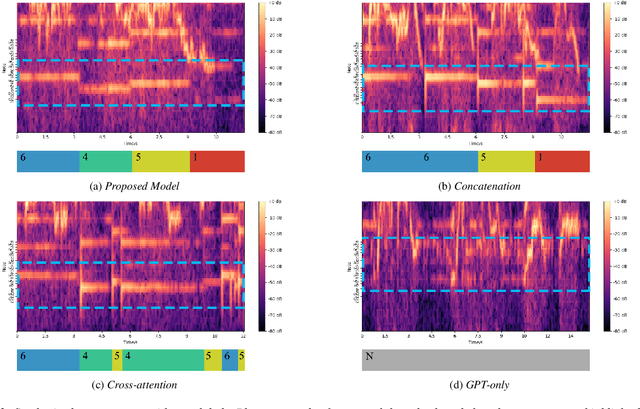
The Song Generation task aims to synthesize music composed of vocals and accompaniment from given lyrics. While the existing method, Jukebox, has explored this task, its constrained control over the generations often leads to deficiency in music performance. To mitigate the issue, we introduce an important concept from music composition, namely chords, to song generation networks. Chords form the foundation of accompaniment and provide vocal melody with associated harmony. Given the inaccuracy of automatic chord extractors, we devise a robust cross-attention mechanism augmented with dynamic weight sequence to integrate extracted chord information into song generations and reduce frame-level flaws, and propose a novel model termed Chord-Conditioned Song Generator (CSG) based on it. Experimental evidence demonstrates our proposed method outperforms other approaches in terms of musical performance and control precision of generated songs.
SongCreator: Lyrics-based Universal Song Generation
Sep 09, 2024
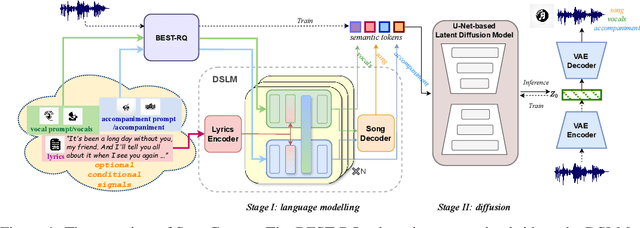
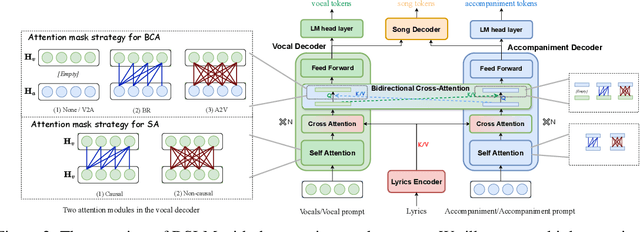

Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and an additional attention mask strategy for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various song-related generation tasks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different prompts, exhibiting its potential applicability. Our samples are available at https://songcreator.github.io/.
WebCanvas: Benchmarking Web Agents in Online Environments
Jun 18, 2024For web agents to be practically useful, they must adapt to the continuously evolving web environment characterized by frequent updates to user interfaces and content. However, most existing benchmarks only capture the static aspects of the web. To bridge this gap, we introduce WebCanvas, an innovative online evaluation framework for web agents that effectively addresses the dynamic nature of web interactions. WebCanvas contains three main components to facilitate realistic assessments: (1) A novel evaluation metric which reliably capture critical intermediate actions or states necessary for task completions while disregarding noise caused by insignificant events or changed web-elements. (2) A benchmark dataset called Mind2Web-Live, a refined version of original Mind2Web static dataset containing 542 tasks with 2439 intermediate evaluation states; (3) Lightweight and generalizable annotation tools and testing pipelines that enables the community to collect and maintain the high-quality, up-to-date dataset. Building on WebCanvas, we open-source an agent framework with extensible modules for reasoning, providing a foundation for the community to conduct online inference and evaluations. Our best-performing agent achieves a task success rate of 23.1% and a task completion rate of 48.8% on the Mind2Web-Live test set. Additionally, we analyze the performance discrepancies across various websites, domains, and experimental environments. We encourage the community to contribute further insights on online agent evaluation, thereby advancing this field of research.
Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly
Apr 30, 2024



Video anomaly understanding (VAU) aims to automatically comprehend unusual occurrences in videos, thereby enabling various applications such as traffic surveillance and industrial manufacturing. While existing VAU benchmarks primarily concentrate on anomaly detection and localization, our focus is on more practicality, prompting us to raise the following crucial questions: "what anomaly occurred?", "why did it happen?", and "how severe is this abnormal event?". In pursuit of these answers, we present a comprehensive benchmark for Causation Understanding of Video Anomaly (CUVA). Specifically, each instance of the proposed benchmark involves three sets of human annotations to indicate the "what", "why" and "how" of an anomaly, including 1) anomaly type, start and end times, and event descriptions, 2) natural language explanations for the cause of an anomaly, and 3) free text reflecting the effect of the abnormality. In addition, we also introduce MMEval, a novel evaluation metric designed to better align with human preferences for CUVA, facilitating the measurement of existing LLMs in comprehending the underlying cause and corresponding effect of video anomalies. Finally, we propose a novel prompt-based method that can serve as a baseline approach for the challenging CUVA. We conduct extensive experiments to show the superiority of our evaluation metric and the prompt-based approach. Our code and dataset are available at https://github.com/fesvhtr/CUVA.
Understanding (Generalized) Label Smoothing when Learning with Noisy Labels
Jun 09, 2021



Label smoothing (LS) is an arising learning paradigm that uses the positively weighted average of both the hard training labels and uniformly distributed soft labels. It was shown that LS serves as a regularizer for training data with hard labels and therefore improves the generalization of the model. Later it was reported LS even helps with improving robustness when learning with noisy labels. However, we observe that the advantage of LS vanishes when we operate in a high label noise regime. Puzzled by the observation, we proceeded to discover that several proposed learning-with-noisy-labels solutions in the literature instead relate more closely to negative label smoothing (NLS), which defines as using a negative weight to combine the hard and soft labels! We show that NLS functions substantially differently from LS in their achieved model confidence. To differentiate the two cases, we will call LS the positive label smoothing (PLS), and this paper unifies PLS and NLS into generalized label smoothing (GLS). We provide understandings for the properties of GLS when learning with noisy labels. Among other established properties, we theoretically show NLS is considered more beneficial when the label noise rates are high. We provide experimental results to support our findings too.