 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasonCLIP-58M: Visually Grounded Commonsense Reasoning Supervision for CLIP
Jun 25, 2026CLIP and its variants are widely adopted visual backbones in multimodal systems, but their pretraining remains dominated by descriptive image-text alignment. As downstream applications increasingly demand visually grounded commonsense inference and compositional reasoning, it remains unclear whether CLIP-style encoders can support such reasoning without architectural changes. To address this, we present ReasonCLIP-58M, a continual pretraining framework that integrates large-scale reasoning supervision into CLIP-style models through our two-stage strategy, which progressively integrates reasoning signals while preserving descriptive alignment, followed by category-structured reasoning supervision. To support this framework, we construct two complementary datasets and a benchmark: ReasonLite-42M, with open-form, visually verifiable reasoning captions; ReasonPro-16M, with category-specific reasoning supervision; and RCLIP-Bench for diagnostic evaluation of visually grounded reasoning. We train a family of ReasonCLIP that improves visually grounded commonsense and compositional reasoning while also enhancing zero-shot retrieval performance. As a drop-in visual encoder for multimodal large language models such as LLaVA-NeXT, ReasonCLIP delivers consistent gains without additional inference cost, demonstrating that structured reasoning supervision enhances the expressive capacity of CLIP-style visual representations. All datasets, models, and training code are available at https://github.com/RISys-Lab/ReasonCLIP.
EgoHandICL: Egocentric 3D Hand Reconstruction with In-Context Learning
Jan 27, 2026Robust 3D hand reconstruction in egocentric vision is challenging due to depth ambiguity, self-occlusion, and complex hand-object interactions. Prior methods mitigate these issues by scaling training data or adding auxiliary cues, but they often struggle in unseen contexts. We present EgoHandICL, the first in-context learning (ICL) framework for 3D hand reconstruction that improves semantic alignment, visual consistency, and robustness under challenging egocentric conditions. EgoHandICL introduces complementary exemplar retrieval guided by vision-language models (VLMs), an ICL-tailored tokenizer for multimodal context, and a masked autoencoder (MAE)-based architecture trained with hand-guided geometric and perceptual objectives. Experiments on ARCTIC and EgoExo4D show consistent gains over state-of-the-art methods. We also demonstrate real-world generalization and improve EgoVLM hand-object interaction reasoning by using reconstructed hands as visual prompts. Code and data: https://github.com/Nicous20/EgoHandICL
Trade-offs in Image Generation: How Do Different Dimensions Interact?
Jul 29, 2025Model performance in text-to-image (T2I) and image-to-image (I2I) generation often depends on multiple aspects, including quality, alignment, diversity, and robustness. However, models' complex trade-offs among these dimensions have rarely been explored due to (1) the lack of datasets that allow fine-grained quantification of these trade-offs, and (2) the use of a single metric for multiple dimensions. To bridge this gap, we introduce TRIG-Bench (Trade-offs in Image Generation), which spans 10 dimensions (Realism, Originality, Aesthetics, Content, Relation, Style, Knowledge, Ambiguity, Toxicity, and Bias), contains 40,200 samples, and covers 132 pairwise dimensional subsets. Furthermore, we develop TRIGScore, a VLM-as-judge metric that automatically adapts to various dimensions. Based on TRIG-Bench and TRIGScore, we evaluate 14 models across T2I and I2I tasks. In addition, we propose the Relation Recognition System to generate the Dimension Trade-off Map (DTM) that visualizes the trade-offs among model-specific capabilities. Our experiments demonstrate that DTM consistently provides a comprehensive understanding of the trade-offs between dimensions for each type of generative model. Notably, we show that the model's dimension-specific weaknesses can be mitigated through fine-tuning on DTM to enhance overall performance. Code is available at: https://github.com/fesvhtr/TRIG
EgoLife: Towards Egocentric Life Assistant
Mar 05, 2025We introduce EgoLife, a project to develop an egocentric life assistant that accompanies and enhances personal efficiency through AI-powered wearable glasses. To lay the foundation for this assistant, we conducted a comprehensive data collection study where six participants lived together for one week, continuously recording their daily activities - including discussions, shopping, cooking, socializing, and entertainment - using AI glasses for multimodal egocentric video capture, along with synchronized third-person-view video references. This effort resulted in the EgoLife Dataset, a comprehensive 300-hour egocentric, interpersonal, multiview, and multimodal daily life dataset with intensive annotation. Leveraging this dataset, we introduce EgoLifeQA, a suite of long-context, life-oriented question-answering tasks designed to provide meaningful assistance in daily life by addressing practical questions such as recalling past relevant events, monitoring health habits, and offering personalized recommendations. To address the key technical challenges of (1) developing robust visual-audio models for egocentric data, (2) enabling identity recognition, and (3) facilitating long-context question answering over extensive temporal information, we introduce EgoButler, an integrated system comprising EgoGPT and EgoRAG. EgoGPT is an omni-modal model trained on egocentric datasets, achieving state-of-the-art performance on egocentric video understanding. EgoRAG is a retrieval-based component that supports answering ultra-long-context questions. Our experimental studies verify their working mechanisms and reveal critical factors and bottlenecks, guiding future improvements. By releasing our datasets, models, and benchmarks, we aim to stimulate further research in egocentric AI assistants.
Creating Virtual Environments with 3D Gaussian Splatting: A Comparative Study
Jan 16, 2025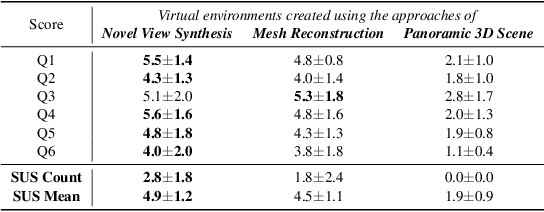

3D Gaussian Splatting (3DGS) has recently emerged as an innovative and efficient 3D representation technique. While its potential for extended reality (XR) applications is frequently highlighted, its practical effectiveness remains underexplored. In this work, we examine three distinct 3DGS-based approaches for virtual environment (VE) creation, leveraging their unique strengths for efficient and visually compelling scene representation. By conducting a comparable study, we evaluate the feasibility of 3DGS in creating immersive VEs, identify its limitations in XR applications, and discuss future research and development opportunities.
Advancing Extended Reality with 3D Gaussian Splatting: Innovations and Prospects
Dec 09, 2024
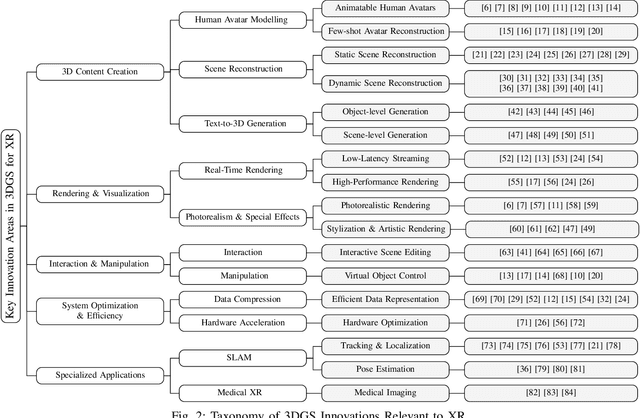
3D Gaussian Splatting (3DGS) has attracted significant attention for its potential to revolutionize 3D representation, rendering, and interaction. Despite the rapid growth of 3DGS research, its direct application to Extended Reality (XR) remains underexplored. Although many studies recognize the potential of 3DGS for XR, few have explicitly focused on or demonstrated its effectiveness within XR environments. In this paper, we aim to synthesize innovations in 3DGS that show specific potential for advancing XR research and development. We conduct a comprehensive review of publicly available 3DGS papers, with a focus on those referencing XR-related concepts. Additionally, we perform an in-depth analysis of innovations explicitly relevant to XR and propose a taxonomy to highlight their significance. Building on these insights, we propose several prospective XR research areas where 3DGS can make promising contributions, yet remain rarely touched. By investigating the intersection of 3DGS and XR, this paper provides a roadmap to push the boundaries of XR using cutting-edge 3DGS techniques.
Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly
Apr 30, 2024



Video anomaly understanding (VAU) aims to automatically comprehend unusual occurrences in videos, thereby enabling various applications such as traffic surveillance and industrial manufacturing. While existing VAU benchmarks primarily concentrate on anomaly detection and localization, our focus is on more practicality, prompting us to raise the following crucial questions: "what anomaly occurred?", "why did it happen?", and "how severe is this abnormal event?". In pursuit of these answers, we present a comprehensive benchmark for Causation Understanding of Video Anomaly (CUVA). Specifically, each instance of the proposed benchmark involves three sets of human annotations to indicate the "what", "why" and "how" of an anomaly, including 1) anomaly type, start and end times, and event descriptions, 2) natural language explanations for the cause of an anomaly, and 3) free text reflecting the effect of the abnormality. In addition, we also introduce MMEval, a novel evaluation metric designed to better align with human preferences for CUVA, facilitating the measurement of existing LLMs in comprehending the underlying cause and corresponding effect of video anomalies. Finally, we propose a novel prompt-based method that can serve as a baseline approach for the challenging CUVA. We conduct extensive experiments to show the superiority of our evaluation metric and the prompt-based approach. Our code and dataset are available at https://github.com/fesvhtr/CUVA.
DocMSU: A Comprehensive Benchmark for Document-level Multimodal Sarcasm Understanding
Dec 26, 2023



Multimodal Sarcasm Understanding (MSU) has a wide range of applications in the news field such as public opinion analysis and forgery detection. However, existing MSU benchmarks and approaches usually focus on sentence-level MSU. In document-level news, sarcasm clues are sparse or small and are often concealed in long text. Moreover, compared to sentence-level comments like tweets, which mainly focus on only a few trends or hot topics (e.g., sports events), content in the news is considerably diverse. Models created for sentence-level MSU may fail to capture sarcasm clues in document-level news. To fill this gap, we present a comprehensive benchmark for Document-level Multimodal Sarcasm Understanding (DocMSU). Our dataset contains 102,588 pieces of news with text-image pairs, covering 9 diverse topics such as health, business, etc. The proposed large-scale and diverse DocMSU significantly facilitates the research of document-level MSU in real-world scenarios. To take on the new challenges posed by DocMSU, we introduce a fine-grained sarcasm comprehension method to properly align the pixel-level image features with word-level textual features in documents. Experiments demonstrate the effectiveness of our method, showing that it can serve as a baseline approach to the challenging DocMSU. Our code and dataset are available at https://github.com/Dulpy/DocMSU.
FunQA: Towards Surprising Video Comprehension
Jun 26, 2023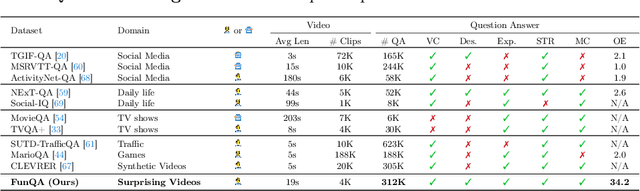
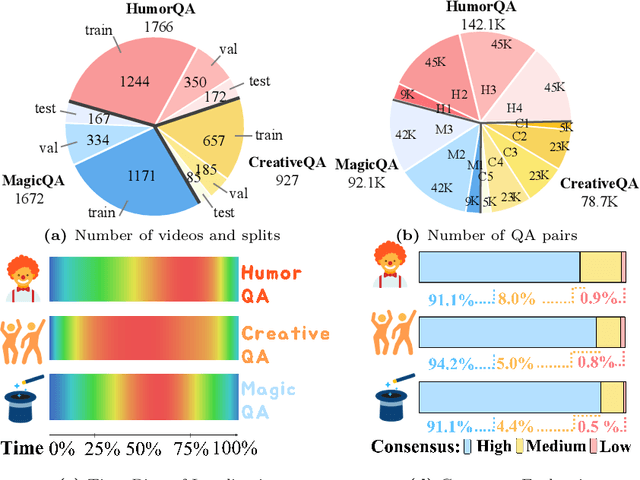

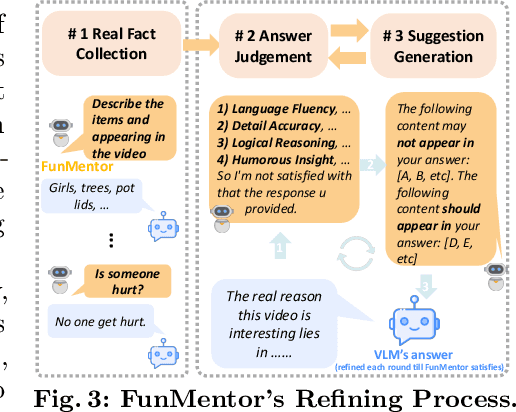
Surprising videos, e.g., funny clips, creative performances, or visual illusions, attract significant attention. Enjoyment of these videos is not simply a response to visual stimuli; rather, it hinges on the human capacity to understand (and appreciate) commonsense violations depicted in these videos. We introduce FunQA, a challenging video question answering (QA) dataset specifically designed to evaluate and enhance the depth of video reasoning based on counter-intuitive and fun videos. Unlike most video QA benchmarks which focus on less surprising contexts, e.g., cooking or instructional videos, FunQA covers three previously unexplored types of surprising videos: 1) HumorQA, 2) CreativeQA, and 3) MagicQA. For each subset, we establish rigorous QA tasks designed to assess the model's capability in counter-intuitive timestamp localization, detailed video description, and reasoning around counter-intuitiveness. We also pose higher-level tasks, such as attributing a fitting and vivid title to the video, and scoring the video creativity. In total, the FunQA benchmark consists of 312K free-text QA pairs derived from 4.3K video clips, spanning a total of 24 video hours. Extensive experiments with existing VideoQA models reveal significant performance gaps for the FunQA videos across spatial-temporal reasoning, visual-centered reasoning, and free-text generation.