 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring What Why and How: A Multifaceted Benchmark for Causation Understanding of Video Anomaly
Dec 10, 2024



Recent advancements in video anomaly understanding (VAU) have opened the door to groundbreaking applications in various fields, such as traffic monitoring and industrial automation. While the current benchmarks in VAU predominantly emphasize the detection and localization of anomalies. Here, we endeavor to delve deeper into the practical aspects of VAU by addressing the essential questions: "what anomaly occurred?", "why did it happen?", and "how severe is this abnormal event?". In pursuit of these answers, we introduce a comprehensive benchmark for Exploring the Causation of Video Anomalies (ECVA). Our benchmark is meticulously designed, with each video accompanied by detailed human annotations. Specifically, each instance of our ECVA involves three sets of human annotations to indicate "what", "why" and "how" of an anomaly, including 1) anomaly type, start and end times, and event descriptions, 2) natural language explanations for the cause of an anomaly, and 3) free text reflecting the effect of the abnormality. Building upon this foundation, we propose a novel prompt-based methodology that serves as a baseline for tackling the intricate challenges posed by ECVA. We utilize "hard prompt" to guide the model to focus on the critical parts related to video anomaly segments, and "soft prompt" to establish temporal and spatial relationships within these anomaly segments. Furthermore, we propose AnomEval, a specialized evaluation metric crafted to align closely with human judgment criteria for ECVA. This metric leverages the unique features of the ECVA dataset to provide a more comprehensive and reliable assessment of various video large language models. We demonstrate the efficacy of our approach through rigorous experimental analysis and delineate possible avenues for further investigation into the comprehension of video anomaly causation.
Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly
Apr 30, 2024



Video anomaly understanding (VAU) aims to automatically comprehend unusual occurrences in videos, thereby enabling various applications such as traffic surveillance and industrial manufacturing. While existing VAU benchmarks primarily concentrate on anomaly detection and localization, our focus is on more practicality, prompting us to raise the following crucial questions: "what anomaly occurred?", "why did it happen?", and "how severe is this abnormal event?". In pursuit of these answers, we present a comprehensive benchmark for Causation Understanding of Video Anomaly (CUVA). Specifically, each instance of the proposed benchmark involves three sets of human annotations to indicate the "what", "why" and "how" of an anomaly, including 1) anomaly type, start and end times, and event descriptions, 2) natural language explanations for the cause of an anomaly, and 3) free text reflecting the effect of the abnormality. In addition, we also introduce MMEval, a novel evaluation metric designed to better align with human preferences for CUVA, facilitating the measurement of existing LLMs in comprehending the underlying cause and corresponding effect of video anomalies. Finally, we propose a novel prompt-based method that can serve as a baseline approach for the challenging CUVA. We conduct extensive experiments to show the superiority of our evaluation metric and the prompt-based approach. Our code and dataset are available at https://github.com/fesvhtr/CUVA.
1st Place Solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction
Apr 16, 2024



In this report, we present the 1st place solution for ICCV 2023 OmniObject3D Challenge: Sparse-View Reconstruction. The challenge aims to evaluate approaches for novel view synthesis and surface reconstruction using only a few posed images of each object. We utilize Pixel-NeRF as the basic model, and apply depth supervision as well as coarse-to-fine positional encoding. The experiments demonstrate the effectiveness of our approach in improving sparse-view reconstruction quality. We ranked first in the final test with a PSNR of 25.44614.
Arbitrary-Scale Point Cloud Upsampling by Voxel-Based Network with Latent Geometric-Consistent Learning
Mar 08, 2024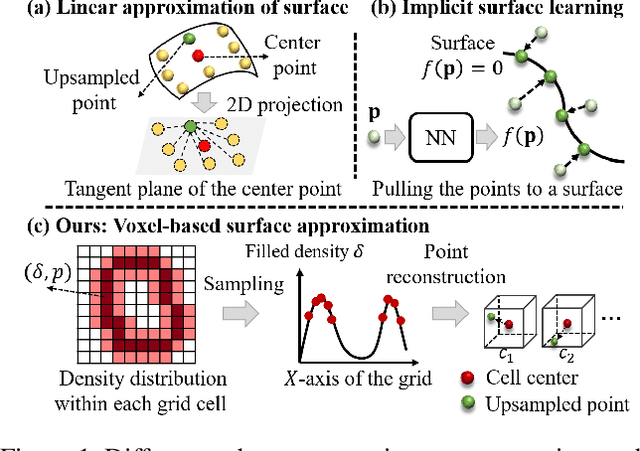
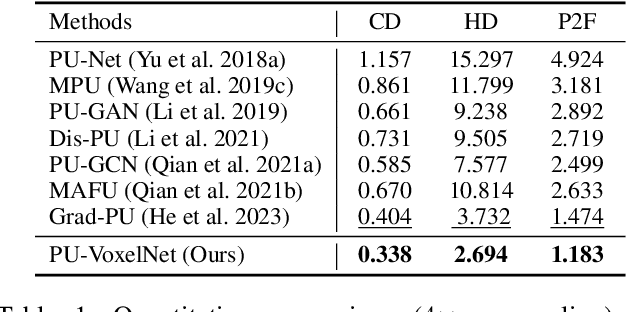
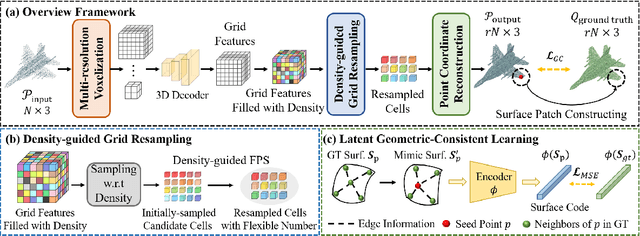
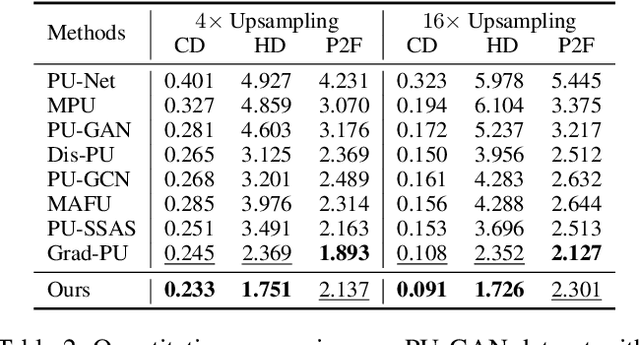
Recently, arbitrary-scale point cloud upsampling mechanism became increasingly popular due to its efficiency and convenience for practical applications. To achieve this, most previous approaches formulate it as a problem of surface approximation and employ point-based networks to learn surface representations. However, learning surfaces from sparse point clouds is more challenging, and thus they often suffer from the low-fidelity geometry approximation. To address it, we propose an arbitrary-scale Point cloud Upsampling framework using Voxel-based Network (\textbf{PU-VoxelNet}). Thanks to the completeness and regularity inherited from the voxel representation, voxel-based networks are capable of providing predefined grid space to approximate 3D surface, and an arbitrary number of points can be reconstructed according to the predicted density distribution within each grid cell. However, we investigate the inaccurate grid sampling caused by imprecise density predictions. To address this issue, a density-guided grid resampling method is developed to generate high-fidelity points while effectively avoiding sampling outliers. Further, to improve the fine-grained details, we present an auxiliary training supervision to enforce the latent geometric consistency among local surface patches. Extensive experiments indicate the proposed approach outperforms the state-of-the-art approaches not only in terms of fixed upsampling rates but also for arbitrary-scale upsampling.
DocMSU: A Comprehensive Benchmark for Document-level Multimodal Sarcasm Understanding
Dec 26, 2023



Multimodal Sarcasm Understanding (MSU) has a wide range of applications in the news field such as public opinion analysis and forgery detection. However, existing MSU benchmarks and approaches usually focus on sentence-level MSU. In document-level news, sarcasm clues are sparse or small and are often concealed in long text. Moreover, compared to sentence-level comments like tweets, which mainly focus on only a few trends or hot topics (e.g., sports events), content in the news is considerably diverse. Models created for sentence-level MSU may fail to capture sarcasm clues in document-level news. To fill this gap, we present a comprehensive benchmark for Document-level Multimodal Sarcasm Understanding (DocMSU). Our dataset contains 102,588 pieces of news with text-image pairs, covering 9 diverse topics such as health, business, etc. The proposed large-scale and diverse DocMSU significantly facilitates the research of document-level MSU in real-world scenarios. To take on the new challenges posed by DocMSU, we introduce a fine-grained sarcasm comprehension method to properly align the pixel-level image features with word-level textual features in documents. Experiments demonstrate the effectiveness of our method, showing that it can serve as a baseline approach to the challenging DocMSU. Our code and dataset are available at https://github.com/Dulpy/DocMSU.
Image2PCI -- A Multitask Learning Framework for Estimating Pavement Condition Indices Directly from Images
Oct 12, 2023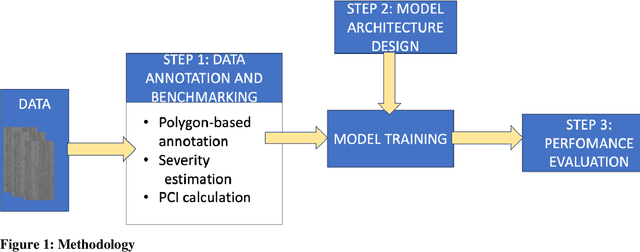
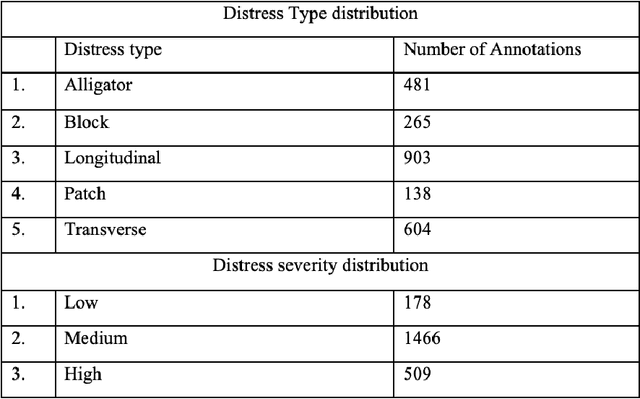

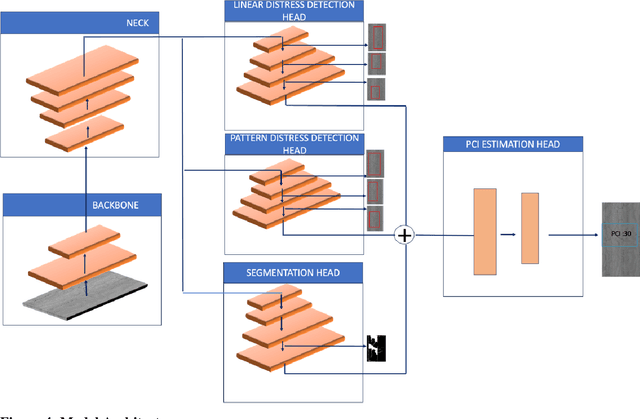
The Pavement Condition Index (PCI) is a widely used metric for evaluating pavement performance based on the type, extent and severity of distresses detected on a pavement surface. In recent times, significant progress has been made in utilizing deep-learning approaches to automate PCI estimation process. However, the current approaches rely on at least two separate models to estimate PCI values -- one model dedicated to determining the type and extent and another for estimating their severity. This approach presents several challenges, including complexities, high computational resource demands, and maintenance burdens that necessitate careful consideration and resolution. To overcome these challenges, the current study develops a unified multi-tasking model that predicts the PCI directly from a top-down pavement image. The proposed architecture is a multi-task model composed of one encoder for feature extraction and four decoders to handle specific tasks: two detection heads, one segmentation head and one PCI estimation head. By multitasking, we are able to extract features from the detection and segmentation heads for automatically estimating the PCI directly from the images. The model performs very well on our benchmarked and open pavement distress dataset that is annotated for multitask learning (the first of its kind). To our best knowledge, this is the first work that can estimate PCI directly from an image at real time speeds while maintaining excellent accuracy on all related tasks for crack detection and segmentation.
Rethinking the Approximation Error in 3D Surface Fitting for Point Cloud Normal Estimation
Mar 30, 2023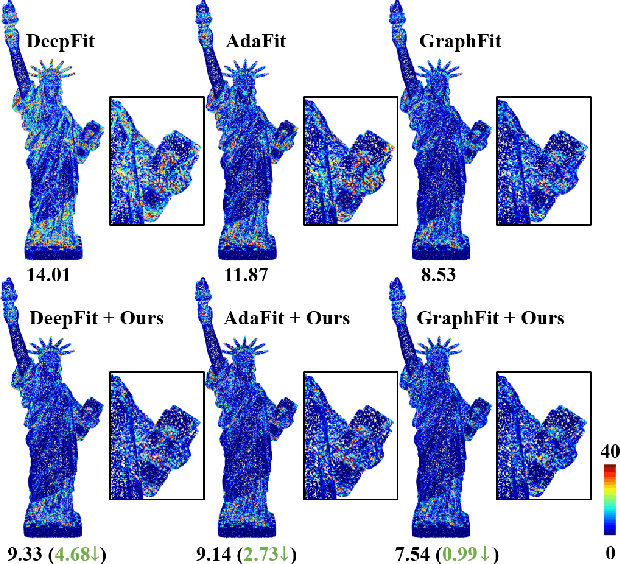
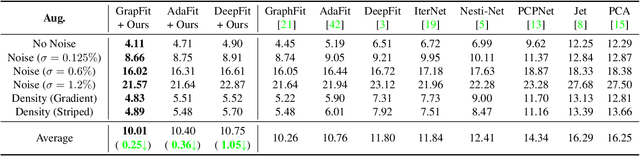
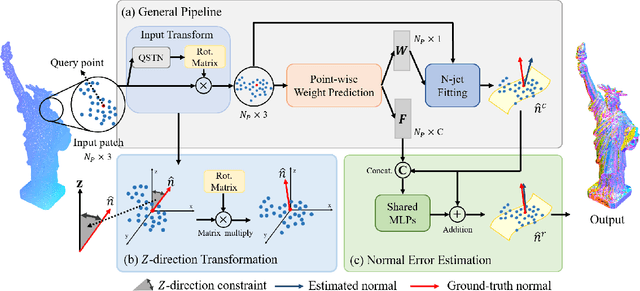
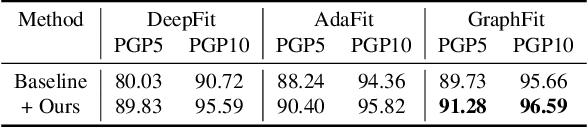
Most existing approaches for point cloud normal estimation aim to locally fit a geometric surface and calculate the normal from the fitted surface. Recently, learning-based methods have adopted a routine of predicting point-wise weights to solve the weighted least-squares surface fitting problem. Despite achieving remarkable progress, these methods overlook the approximation error of the fitting problem, resulting in a less accurate fitted surface. In this paper, we first carry out in-depth analysis of the approximation error in the surface fitting problem. Then, in order to bridge the gap between estimated and precise surface normals, we present two basic design principles: 1) applies the $Z$-direction Transform to rotate local patches for a better surface fitting with a lower approximation error; 2) models the error of the normal estimation as a learnable term. We implement these two principles using deep neural networks, and integrate them with the state-of-the-art (SOTA) normal estimation methods in a plug-and-play manner. Extensive experiments verify our approaches bring benefits to point cloud normal estimation and push the frontier of state-of-the-art performance on both synthetic and real-world datasets.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022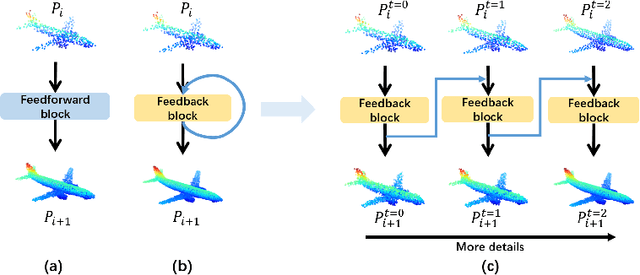
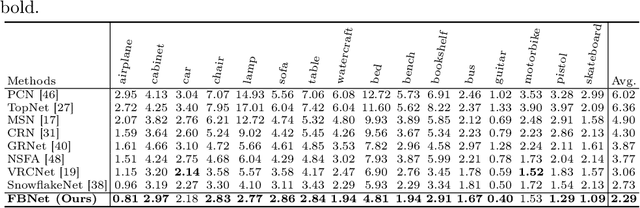
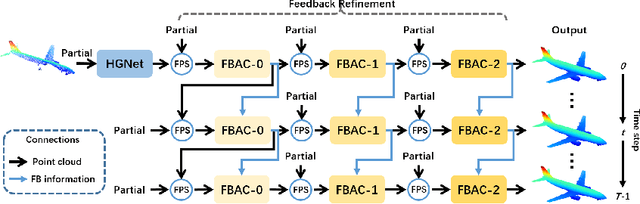
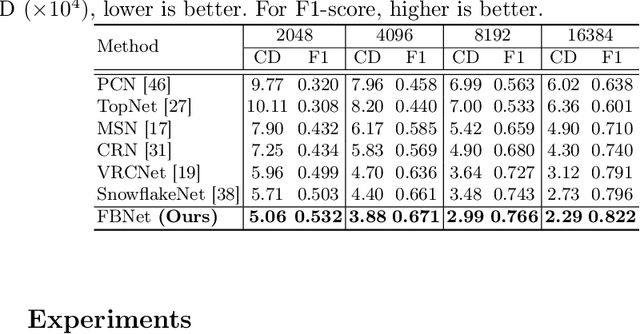
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.
Point Cloud Upsampling via Cascaded Refinement Network
Oct 08, 2022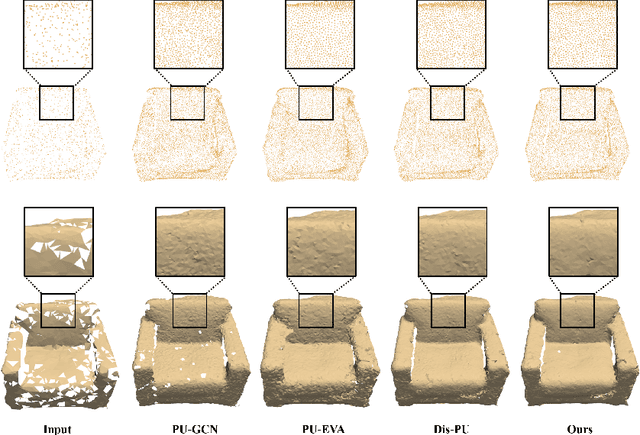
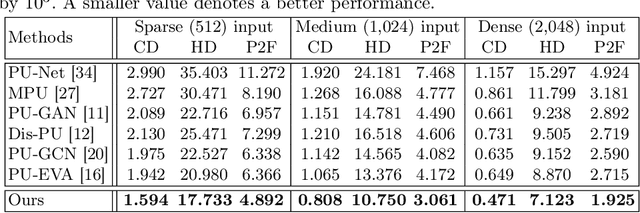
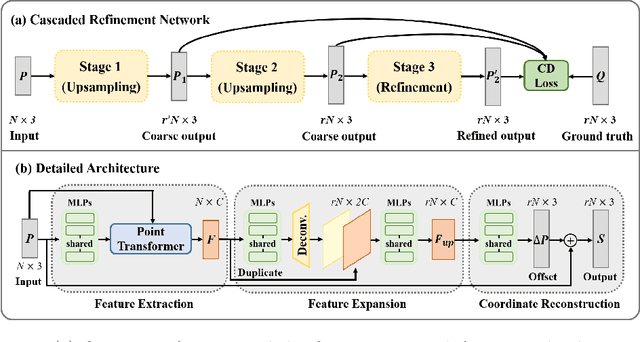
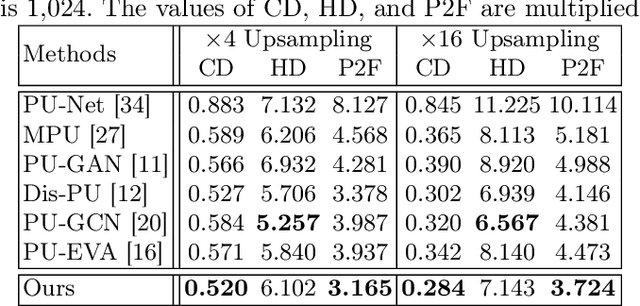
Point cloud upsampling focuses on generating a dense, uniform and proximity-to-surface point set. Most previous approaches accomplish these objectives by carefully designing a single-stage network, which makes it still challenging to generate a high-fidelity point distribution. Instead, upsampling point cloud in a coarse-to-fine manner is a decent solution. However, existing coarse-to-fine upsampling methods require extra training strategies, which are complicated and time-consuming during the training. In this paper, we propose a simple yet effective cascaded refinement network, consisting of three generation stages that have the same network architecture but achieve different objectives. Specifically, the first two upsampling stages generate the dense but coarse points progressively, while the last refinement stage further adjust the coarse points to a better position. To mitigate the learning conflicts between multiple stages and decrease the difficulty of regressing new points, we encourage each stage to predict the point offsets with respect to the input shape. In this manner, the proposed cascaded refinement network can be easily optimized without extra learning strategies. Moreover, we design a transformer-based feature extraction module to learn the informative global and local shape context. In inference phase, we can dynamically adjust the model efficiency and effectiveness, depending on the available computational resources. Extensive experiments on both synthetic and real-scanned datasets demonstrate that the proposed approach outperforms the existing state-of-the-art methods.
Scale Attention for Learning Deep Face Representation: A Study Against Visual Scale Variation
Sep 19, 2022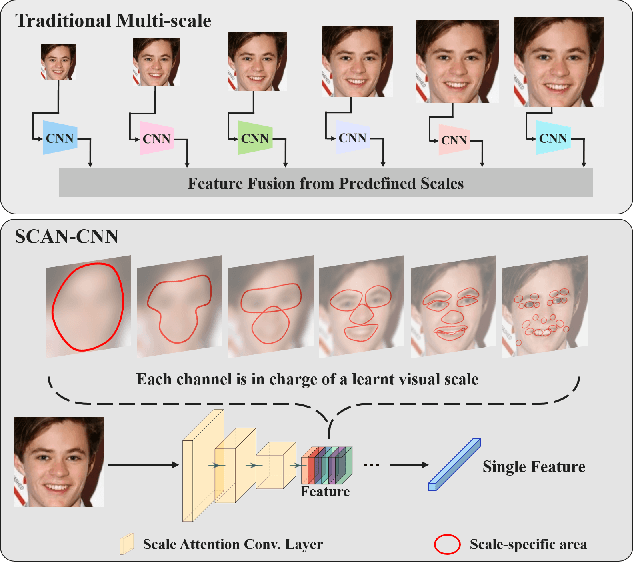
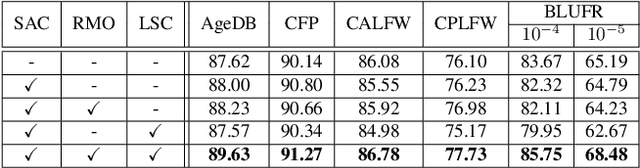
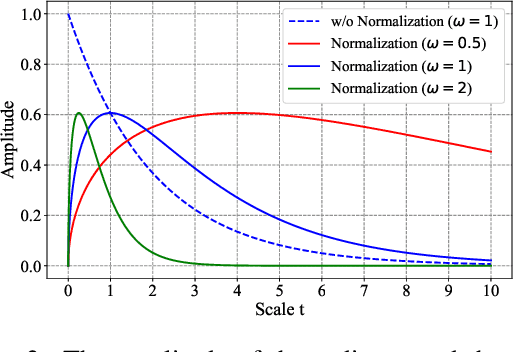
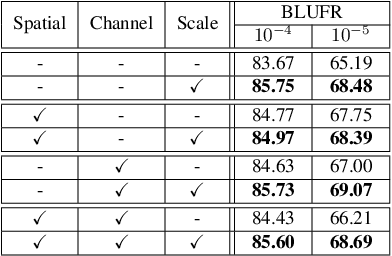
Human face images usually appear with wide range of visual scales. The existing face representations pursue the bandwidth of handling scale variation via multi-scale scheme that assembles a finite series of predefined scales. Such multi-shot scheme brings inference burden, and the predefined scales inevitably have gap from real data. Instead, learning scale parameters from data, and using them for one-shot feature inference, is a decent solution. To this end, we reform the conv layer by resorting to the scale-space theory, and achieve two-fold facilities: 1) the conv layer learns a set of scales from real data distribution, each of which is fulfilled by a conv kernel; 2) the layer automatically highlights the feature at the proper channel and location corresponding to the input pattern scale and its presence. Then, we accomplish the hierarchical scale attention by stacking the reformed layers, building a novel style named SCale AttentioN Conv Neural Network (\textbf{SCAN-CNN}). We apply SCAN-CNN to the face recognition task and push the frontier of SOTA performance. The accuracy gain is more evident when the face images are blurry. Meanwhile, as a single-shot scheme, the inference is more efficient than multi-shot fusion. A set of tools are made to ensure the fast training of SCAN-CNN and zero increase of inference cost compared with the plain CNN.