 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHijacking Large Audio-Language Models via Context-Agnostic and Imperceptible Auditory Prompt Injection
Apr 16, 2026Modern Large audio-language models (LALMs) power intelligent voice interactions by tightly integrating audio and text. This integration, however, expands the attack surface beyond text and introduces vulnerabilities in the continuous, high-dimensional audio channel. While prior work studied audio jailbreaks, the security risks of malicious audio injection and downstream behavior manipulation remain underexamined. In this work, we reveal a previously overlooked threat, auditory prompt injection, under realistic constraints of audio data-only access and strong perceptual stealth. To systematically analyze this threat, we propose \textit{AudioHijack}, a general framework that generates context-agnostic and imperceptible adversarial audio to hijack LALMs. \textit{AudioHijack} employs sampling-based gradient estimation for end-to-end optimization across diverse models, bypassing non-differentiable audio tokenization. Through attention supervision and multi-context training, it steers model attention toward adversarial audio and generalizes to unseen user contexts. We also design a convolutional blending method that modulates perturbations into natural reverberation, making them highly imperceptible to users. Extensive experiments on 13 state-of-the-art LALMs show consistent hijacking across 6 misbehavior categories, achieving average success rates of 79\%-96\% on unseen user contexts with high acoustic fidelity. Real-world studies demonstrate that commercial voice agents from Mistral AI and Microsoft Azure can be induced to execute unauthorized actions on behalf of users. These findings expose critical vulnerabilities in LALMs and highlight the urgent need for dedicated defense.
STEP: Detecting Audio Backdoor Attacks via Stability-based Trigger Exposure Profiling
Mar 18, 2026With the widespread deployment of deep-learning-based speech models in security-critical applications, backdoor attacks have emerged as a serious threat: an adversary who poisons a small fraction of training data can implant a hidden trigger that controls the model's output while preserving normal behavior on clean inputs. Existing inference-time defenses are not well suited to the audio domain, as they either rely on trigger over-robustness assumptions that fail on transformation-based and semantic triggers, or depend on properties specific to image or text modalities. In this paper, we propose STEP (Stability-based Trigger Exposure Profiling), a black-box, retraining-free backdoor detector that operates under hard-label-only access. Its core idea is to exploit a characteristic dual anomaly of backdoor triggers: anomalous label stability under semantic-breaking perturbations, and anomalous label fragility under semantic-preserving perturbations. STEP profiles each test sample with two complementary perturbation branches that target these two properties respectively, scores the resulting stability features with one-class anomaly detectors trained on benign references, and fuses the two scores via unsupervised weighting. Extensive experiments across seven backdoor attacks show that STEP achieves an average AUROC of 97.92% and EER of 4.54%, substantially outperforming state-of-the-art baselines, and generalizes across model architectures, speech tasks, an open-set verification scenario, and over-the-air physical-world settings.
EcoGym: Evaluating LLMs for Long-Horizon Plan-and-Execute in Interactive Economies
Feb 11, 2026Long-horizon planning is widely recognized as a core capability of autonomous LLM-based agents; however, current evaluation frameworks suffer from being largely episodic, domain-specific, or insufficiently grounded in persistent economic dynamics. We introduce EcoGym, a generalizable benchmark for continuous plan-and-execute decision making in interactive economies. EcoGym comprises three diverse environments: Vending, Freelance, and Operation, implemented in a unified decision-making process with standardized interfaces, and budgeted actions over an effectively unbounded horizon (1000+ steps if 365 day-loops for evaluation). The evaluation of EcoGym is based on business-relevant outcomes (e.g., net worth, income, and DAU), targeting long-term strategic coherence and robustness under partial observability and stochasticity. Experiments across eleven leading LLMs expose a systematic tension: no single model dominates across all three scenarios. Critically, we find that models exhibit significant suboptimality in either high-level strategies or efficient actions executions. EcoGym is released as an open, extensible testbed for transparent long-horizon agent evaluation and for studying controllability-utility trade-offs in realistic economic settings.
HyperPotter: Spell the Charm of High-Order Interactions in Audio Deepfake Detection
Feb 05, 2026Advances in AIGC technologies have enabled the synthesis of highly realistic audio deepfakes capable of deceiving human auditory perception. Although numerous audio deepfake detection (ADD) methods have been developed, most rely on local temporal/spectral features or pairwise relations, overlooking high-order interactions (HOIs). HOIs capture discriminative patterns that emerge from multiple feature components beyond their individual contributions. We propose HyperPotter, a hypergraph-based framework that explicitly models these synergistic HOIs through clustering-based hyperedges with class-aware prototype initialization. Extensive experiments demonstrate that HyperPotter surpasses its baseline by an average relative gain of 22.15% across 11 datasets and outperforms state-of-the-art methods by 13.96% on 4 challenging cross-domain datasets, demonstrating superior generalization to diverse attacks and speakers.
Neural Collapse in Test-Time Adaptation
Dec 11, 2025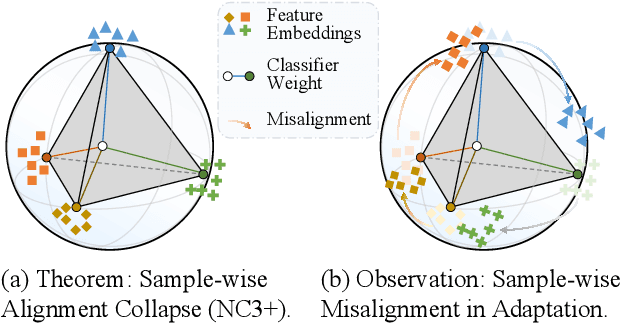
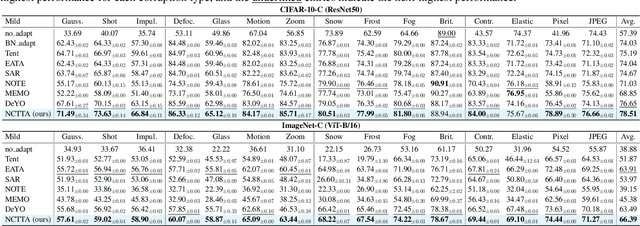
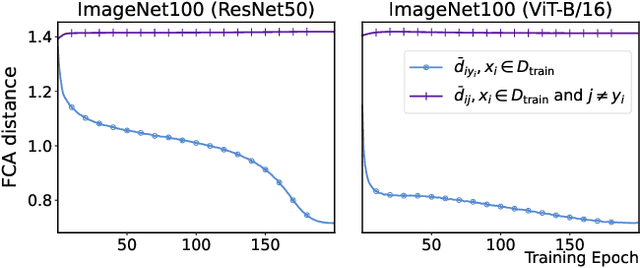
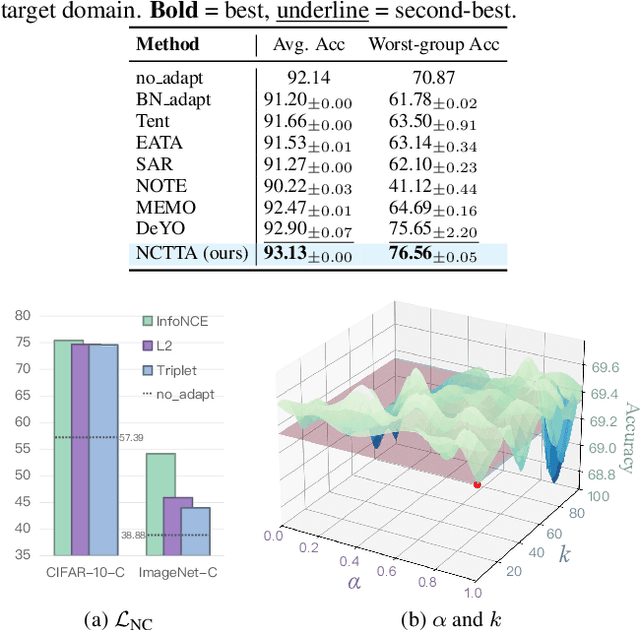
Test-Time Adaptation (TTA) enhances model robustness to out-of-distribution (OOD) data by updating the model online during inference, yet existing methods lack theoretical insights into the fundamental causes of performance degradation under domain shifts. Recently, Neural Collapse (NC) has been proposed as an emergent geometric property of deep neural networks (DNNs), providing valuable insights for TTA. In this work, we extend NC to the sample-wise level and discover a novel phenomenon termed Sample-wise Alignment Collapse (NC3+), demonstrating that a sample's feature embedding, obtained by a trained model, aligns closely with the corresponding classifier weight. Building on NC3+, we identify that the performance degradation stems from sample-wise misalignment in adaptation which exacerbates under larger distribution shifts. This indicates the necessity of realigning the feature embeddings with their corresponding classifier weights. However, the misalignment makes pseudo-labels unreliable under domain shifts. To address this challenge, we propose NCTTA, a novel feature-classifier alignment method with hybrid targets to mitigate the impact of unreliable pseudo-labels, which blends geometric proximity with predictive confidence. Extensive experiments demonstrate the effectiveness of NCTTA in enhancing robustness to domain shifts. For example, NCTTA outperforms Tent by 14.52% on ImageNet-C.
REACT-LLM: A Benchmark for Evaluating LLM Integration with Causal Features in Clinical Prognostic Tasks
Nov 13, 2025Large Language Models (LLMs) and causal learning each hold strong potential for clinical decision making (CDM). However, their synergy remains poorly understood, largely due to the lack of systematic benchmarks evaluating their integration in clinical risk prediction. In real-world healthcare, identifying features with causal influence on outcomes is crucial for actionable and trustworthy predictions. While recent work highlights LLMs' emerging causal reasoning abilities, there lacks comprehensive benchmarks to assess their causal learning and performance informed by causal features in clinical risk prediction. To address this, we introduce REACT-LLM, a benchmark designed to evaluate whether combining LLMs with causal features can enhance clinical prognostic performance and potentially outperform traditional machine learning (ML) methods. Unlike existing LLM-clinical benchmarks that often focus on a limited set of outcomes, REACT-LLM evaluates 7 clinical outcomes across 2 real-world datasets, comparing 15 prominent LLMs, 6 traditional ML models, and 3 causal discovery (CD) algorithms. Our findings indicate that while LLMs perform reasonably in clinical prognostics, they have not yet outperformed traditional ML models. Integrating causal features derived from CD algorithms into LLMs offers limited performance gains, primarily due to the strict assumptions of many CD methods, which are often violated in complex clinical data. While the direct integration yields limited improvement, our benchmark reveals a more promising synergy.
Imagine with the Teacher: Complete Shape in a Multi-View Distillation Way
Jan 31, 2025



Point cloud completion aims to recover the completed 3D shape of an object from its partial observation caused by occlusion, sensor's limitation, noise, etc. When some key semantic information is lost in the incomplete point cloud, the neural network needs to infer the missing part based on the input information. Intuitively we would apply an autoencoder architecture to solve this kind of problem, which take the incomplete point cloud as input and is supervised by the ground truth. This process that develops model's imagination from incomplete shape to complete shape is done automatically in the latent space. But the knowledge for mapping from incomplete to complete still remains dark and could be further explored. Motivated by the knowledge distillation's teacher-student learning strategy, we design a knowledge transfer way for completing 3d shape. In this work, we propose a novel View Distillation Point Completion Network (VD-PCN), which solve the completion problem by a multi-view distillation way. The design methodology fully leverages the orderliness of 2d pixels, flexibleness of 2d processing and powerfulness of 2d network. Extensive evaluations on PCN, ShapeNet55/34, and MVP datasets confirm the effectiveness of our design and knowledge transfer strategy, both quantitatively and qualitatively. Committed to facilitate ongoing research, we will make our code publicly available.
Towards Lightweight and Stable Zero-shot TTS with Self-distilled Representation Disentanglement
Jan 15, 2025Zero-shot Text-To-Speech (TTS) synthesis shows great promise for personalized voice customization through voice cloning. However, current methods for achieving zero-shot TTS heavily rely on large model scales and extensive training datasets to ensure satisfactory performance and generalizability across various speakers. This raises concerns regarding both deployment costs and data security. In this paper, we present a lightweight and stable zero-shot TTS system. We introduce a novel TTS architecture designed to effectively model linguistic content and various speaker attributes from source speech and prompt speech, respectively. Furthermore, we present a two-stage self-distillation framework that constructs parallel data pairs for effectively disentangling linguistic content and speakers from the perspective of training data. Extensive experiments show that our system exhibits excellent performance and superior stability on the zero-shot TTS tasks. Moreover, it shows markedly superior computational efficiency, with RTFs of 0.13 and 0.012 on the CPU and GPU, respectively.
ALIF: Low-Cost Adversarial Audio Attacks on Black-Box Speech Platforms using Linguistic Features
Aug 03, 2024Extensive research has revealed that adversarial examples (AE) pose a significant threat to voice-controllable smart devices. Recent studies have proposed black-box adversarial attacks that require only the final transcription from an automatic speech recognition (ASR) system. However, these attacks typically involve many queries to the ASR, resulting in substantial costs. Moreover, AE-based adversarial audio samples are susceptible to ASR updates. In this paper, we identify the root cause of these limitations, namely the inability to construct AE attack samples directly around the decision boundary of deep learning (DL) models. Building on this observation, we propose ALIF, the first black-box adversarial linguistic feature-based attack pipeline. We leverage the reciprocal process of text-to-speech (TTS) and ASR models to generate perturbations in the linguistic embedding space where the decision boundary resides. Based on the ALIF pipeline, we present the ALIF-OTL and ALIF-OTA schemes for launching attacks in both the digital domain and the physical playback environment on four commercial ASRs and voice assistants. Extensive evaluations demonstrate that ALIF-OTL and -OTA significantly improve query efficiency by 97.7% and 73.3%, respectively, while achieving competitive performance compared to existing methods. Notably, ALIF-OTL can generate an attack sample with only one query. Furthermore, our test-of-time experiment validates the robustness of our approach against ASR updates.
Exposing the Deception: Uncovering More Forgery Clues for Deepfake Detection
Mar 04, 2024



Deepfake technology has given rise to a spectrum of novel and compelling applications. Unfortunately, the widespread proliferation of high-fidelity fake videos has led to pervasive confusion and deception, shattering our faith that seeing is believing. One aspect that has been overlooked so far is that current deepfake detection approaches may easily fall into the trap of overfitting, focusing only on forgery clues within one or a few local regions. Moreover, existing works heavily rely on neural networks to extract forgery features, lacking theoretical constraints guaranteeing that sufficient forgery clues are extracted and superfluous features are eliminated. These deficiencies culminate in unsatisfactory accuracy and limited generalizability in real-life scenarios. In this paper, we try to tackle these challenges through three designs: (1) We present a novel framework to capture broader forgery clues by extracting multiple non-overlapping local representations and fusing them into a global semantic-rich feature. (2) Based on the information bottleneck theory, we derive Local Information Loss to guarantee the orthogonality of local representations while preserving comprehensive task-relevant information. (3) Further, to fuse the local representations and remove task-irrelevant information, we arrive at a Global Information Loss through the theoretical analysis of mutual information. Empirically, our method achieves state-of-the-art performance on five benchmark datasets.Our code is available at \url{https://github.com/QingyuLiu/Exposing-the-Deception}, hoping to inspire researchers.