 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressVLA: Progress-Guided Diffusion Policy for Vision-Language Robotic Manipulation
Mar 29, 2026Most existing vision-language-action (VLA) models for robotic manipulation lack progress awareness, typically relying on hand-crafted heuristics for task termination. This limitation is particularly severe in long-horizon tasks involving cascaded sub-goals. In this work, we investigate the estimation and integration of task progress, proposing a novel model named {\textbf \vla}. Our technical contributions are twofold: (1) \emph{robust progress estimation}: We pre-train a progress estimator on large-scale, unsupervised video-text robotic datasets. This estimator achieves a low prediction residual (0.07 on a scale of $[0, 1]$) in simulation and demonstrates zero-shot generalization to unseen real-world samples, and (2) \emph{differentiable progress guidance}: We introduce an inverse dynamics world model that maps predicted action tokens into future latent visual states. These latents are then processed by the progress estimator; by applying a maximal progress regularization, we establish a differentiable pipeline that provides progress-piloted guidance to refine action tokens. Extensive experiments on the CALVIN and LIBERO benchmarks, alongside real-world robot deployment, consistently demonstrate substantial improvements in success rates and generalization over strong baselines.
ArtLLM: Generating Articulated Assets via 3D LLM
Mar 01, 2026Creating interactive digital environments for gaming, robotics, and simulation relies on articulated 3D objects whose functionality emerges from their part geometry and kinematic structure. However, existing approaches remain fundamentally limited: optimization-based reconstruction methods require slow, per-object joint fitting and typically handle only simple, single-joint objects, while retrieval-based methods assemble parts from a fixed library, leading to repetitive geometry and poor generalization. To address these challenges, we introduce ArtLLM, a novel framework for generating high-quality articulated assets directly from complete 3D meshes. At its core is a 3D multimodal large language model trained on a large-scale articulation dataset curated from both existing articulation datasets and procedurally generated objects. Unlike prior work, ArtLLM autoregressively predicts a variable number of parts and joints, inferring their kinematic structure in a unified manner from the object's point cloud. This articulation-aware layout then conditions a 3D generative model to synthesize high-fidelity part geometries. Experiments on the PartNet-Mobility dataset show that ArtLLM significantly outperforms state-of-the-art methods in both part layout accuracy and joint prediction, while generalizing robustly to real-world objects. Finally, we demonstrate its utility in constructing digital twins, highlighting its potential for scalable robot learning.
HY3D-Bench: Generation of 3D Assets
Feb 03, 2026While recent advances in neural representations and generative models have revolutionized 3D content creation, the field remains constrained by significant data processing bottlenecks. To address this, we introduce HY3D-Bench, an open-source ecosystem designed to establish a unified, high-quality foundation for 3D generation. Our contributions are threefold: (1) We curate a library of 250k high-fidelity 3D objects distilled from large-scale repositories, employing a rigorous pipeline to deliver training-ready artifacts, including watertight meshes and multi-view renderings; (2) We introduce structured part-level decomposition, providing the granularity essential for fine-grained perception and controllable editing; and (3) We bridge real-world distribution gaps via a scalable AIGC synthesis pipeline, contributing 125k synthetic assets to enhance diversity in long-tail categories. Validated empirically through the training of Hunyuan3D-2.1-Small, HY3D-Bench democratizes access to robust data resources, aiming to catalyze innovation across 3D perception, robotics, and digital content creation.
FlowSSC: Universal Generative Monocular Semantic Scene Completion via One-Step Latent Diffusion
Jan 21, 2026Semantic Scene Completion (SSC) from monocular RGB images is a fundamental yet challenging task due to the inherent ambiguity of inferring occluded 3D geometry from a single view. While feed-forward methods have made progress, they often struggle to generate plausible details in occluded regions and preserve the fundamental spatial relationships of objects. Such accurate generative reasoning capability for the entire 3D space is critical in real-world applications. In this paper, we present FlowSSC, the first generative framework applied directly to monocular semantic scene completion. FlowSSC treats the SSC task as a conditional generation problem and can seamlessly integrate with existing feed-forward SSC methods to significantly boost their performance. To achieve real-time inference without compromising quality, we introduce Shortcut Flow-matching that operates in a compact triplane latent space. Unlike standard diffusion models that require hundreds of steps, our method utilizes a shortcut mechanism to achieve high-fidelity generation in a single step, enabling practical deployment in autonomous systems. Extensive experiments on SemanticKITTI demonstrate that FlowSSC achieves state-of-the-art performance, significantly outperforming existing baselines.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
UniTEX: Universal High Fidelity Generative Texturing for 3D Shapes
May 29, 2025We present UniTEX, a novel two-stage 3D texture generation framework to create high-quality, consistent textures for 3D assets. Existing approaches predominantly rely on UV-based inpainting to refine textures after reprojecting the generated multi-view images onto the 3D shapes, which introduces challenges related to topological ambiguity. To address this, we propose to bypass the limitations of UV mapping by operating directly in a unified 3D functional space. Specifically, we first propose that lifts texture generation into 3D space via Texture Functions (TFs)--a continuous, volumetric representation that maps any 3D point to a texture value based solely on surface proximity, independent of mesh topology. Then, we propose to predict these TFs directly from images and geometry inputs using a transformer-based Large Texturing Model (LTM). To further enhance texture quality and leverage powerful 2D priors, we develop an advanced LoRA-based strategy for efficiently adapting large-scale Diffusion Transformers (DiTs) for high-quality multi-view texture synthesis as our first stage. Extensive experiments demonstrate that UniTEX achieves superior visual quality and texture integrity compared to existing approaches, offering a generalizable and scalable solution for automated 3D texture generation. Code will available in: https://github.com/YixunLiang/UniTEX.
MapEval: Towards Unified, Robust and Efficient SLAM Map Evaluation Framework
Nov 26, 2024



Evaluating massive-scale point cloud maps in Simultaneous Localization and Mapping (SLAM) remains challenging, primarily due to the absence of unified, robust and efficient evaluation frameworks. We present MapEval, an open-source framework for comprehensive quality assessment of point cloud maps, specifically addressing SLAM scenarios where ground truth map is inherently sparse compared to the mapped environment. Through systematic analysis of existing evaluation metrics in SLAM applications, we identify their fundamental limitations and establish clear guidelines for consistent map quality assessment. Building upon these insights, we propose a novel Gaussian-approximated Wasserstein distance in voxelized space, enabling two complementary metrics under the same error standard: Voxelized Average Wasserstein Distance (AWD) for global geometric accuracy and Spatial Consistency Score (SCS) for local consistency evaluation. This theoretical foundation leads to significant improvements in both robustness against noise and computational efficiency compared to conventional metrics. Extensive experiments on both simulated and real-world datasets demonstrate that MapEval achieves at least \SI{100}{}-\SI{500}{} times faster while maintaining evaluation integrity. The MapEval library\footnote{\texttt{https://github.com/JokerJohn/Cloud\_Map\_Evaluation}} will be publicly available to promote standardized map evaluation practices in the robotics community.
Neural Assembler: Learning to Generate Fine-Grained Robotic Assembly Instructions from Multi-View Images
Apr 25, 2024



Image-guided object assembly represents a burgeoning research topic in computer vision. This paper introduces a novel task: translating multi-view images of a structural 3D model (for example, one constructed with building blocks drawn from a 3D-object library) into a detailed sequence of assembly instructions executable by a robotic arm. Fed with multi-view images of the target 3D model for replication, the model designed for this task must address several sub-tasks, including recognizing individual components used in constructing the 3D model, estimating the geometric pose of each component, and deducing a feasible assembly order adhering to physical rules. Establishing accurate 2D-3D correspondence between multi-view images and 3D objects is technically challenging. To tackle this, we propose an end-to-end model known as the Neural Assembler. This model learns an object graph where each vertex represents recognized components from the images, and the edges specify the topology of the 3D model, enabling the derivation of an assembly plan. We establish benchmarks for this task and conduct comprehensive empirical evaluations of Neural Assembler and alternative solutions. Our experiments clearly demonstrate the superiority of Neural Assembler.
Iterative Reconstruction Based on Latent Diffusion Model for Sparse Data Reconstruction
Jul 22, 2023



Reconstructing Computed tomography (CT) images from sparse measurement is a well-known ill-posed inverse problem. The Iterative Reconstruction (IR) algorithm is a solution to inverse problems. However, recent IR methods require paired data and the approximation of the inverse projection matrix. To address those problems, we present Latent Diffusion Iterative Reconstruction (LDIR), a pioneering zero-shot method that extends IR with a pre-trained Latent Diffusion Model (LDM) as a accurate and efficient data prior. By approximating the prior distribution with an unconditional latent diffusion model, LDIR is the first method to successfully integrate iterative reconstruction and LDM in an unsupervised manner. LDIR makes the reconstruction of high-resolution images more efficient. Moreover, LDIR utilizes the gradient from the data-fidelity term to guide the sampling process of the LDM, therefore, LDIR does not need the approximation of the inverse projection matrix and can solve various CT reconstruction tasks with a single model. Additionally, for enhancing the sample consistency of the reconstruction, we introduce a novel approach that uses historical gradient information to guide the gradient. Our experiments on extremely sparse CT data reconstruction tasks show that LDIR outperforms other state-of-the-art unsupervised and even exceeds supervised methods, establishing it as a leading technique in terms of both quantity and quality. Furthermore, LDIR also achieves competitive performance on nature image tasks. It is worth noting that LDIR also exhibits significantly faster execution times and lower memory consumption compared to methods with similar network settings. Our code will be publicly available.
FBNet: Feedback Network for Point Cloud Completion
Oct 08, 2022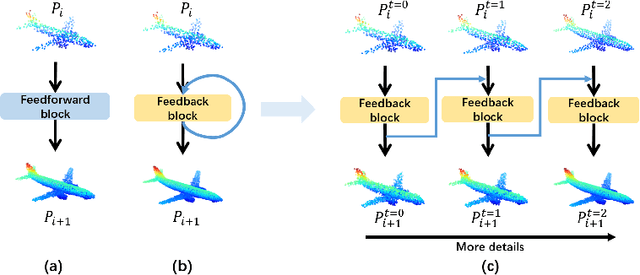
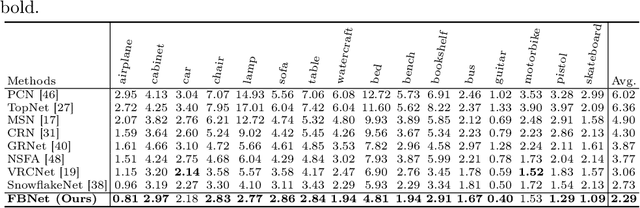
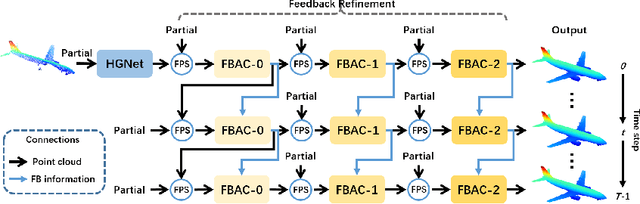
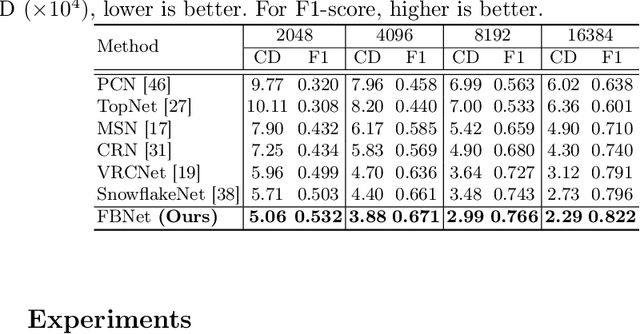
The rapid development of point cloud learning has driven point cloud completion into a new era. However, the information flows of most existing completion methods are solely feedforward, and high-level information is rarely reused to improve low-level feature learning. To this end, we propose a novel Feedback Network (FBNet) for point cloud completion, in which present features are efficiently refined by rerouting subsequent fine-grained ones. Firstly, partial inputs are fed to a Hierarchical Graph-based Network (HGNet) to generate coarse shapes. Then, we cascade several Feedback-Aware Completion (FBAC) Blocks and unfold them across time recurrently. Feedback connections between two adjacent time steps exploit fine-grained features to improve present shape generations. The main challenge of building feedback connections is the dimension mismatching between present and subsequent features. To address this, the elaborately designed point Cross Transformer exploits efficient information from feedback features via cross attention strategy and then refines present features with the enhanced feedback features. Quantitative and qualitative experiments on several datasets demonstrate the superiority of proposed FBNet compared to state-of-the-art methods on point completion task.