 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Diffusion Model Stability for Image Restoration via Gradient Management
Jul 09, 2025

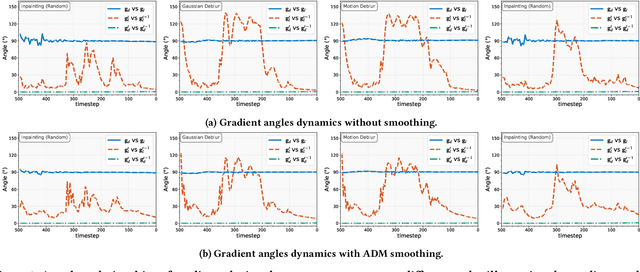

Diffusion models have shown remarkable promise for image restoration by leveraging powerful priors. Prominent methods typically frame the restoration problem within a Bayesian inference framework, which iteratively combines a denoising step with a likelihood guidance step. However, the interactions between these two components in the generation process remain underexplored. In this paper, we analyze the underlying gradient dynamics of these components and identify significant instabilities. Specifically, we demonstrate conflicts between the prior and likelihood gradient directions, alongside temporal fluctuations in the likelihood gradient itself. We show that these instabilities disrupt the generative process and compromise restoration performance. To address these issues, we propose Stabilized Progressive Gradient Diffusion (SPGD), a novel gradient management technique. SPGD integrates two synergistic components: (1) a progressive likelihood warm-up strategy to mitigate gradient conflicts; and (2) adaptive directional momentum (ADM) smoothing to reduce fluctuations in the likelihood gradient. Extensive experiments across diverse restoration tasks demonstrate that SPGD significantly enhances generation stability, leading to state-of-the-art performance in quantitative metrics and visually superior results. Code is available at \href{https://github.com/74587887/SPGD}{here}.
MedSAM-U: Uncertainty-Guided Auto Multi-Prompt Adaptation for Reliable MedSAM
Sep 02, 2024



The Medical Segment Anything Model (MedSAM) has shown remarkable performance in medical image segmentation, drawing significant attention in the field. However, its sensitivity to varying prompt types and locations poses challenges. This paper addresses these challenges by focusing on the development of reliable prompts that enhance MedSAM's accuracy. We introduce MedSAM-U, an uncertainty-guided framework designed to automatically refine multi-prompt inputs for more reliable and precise medical image segmentation. Specifically, we first train a Multi-Prompt Adapter integrated with MedSAM, creating MPA-MedSAM, to adapt to diverse multi-prompt inputs. We then employ uncertainty-guided multi-prompt to effectively estimate the uncertainties associated with the prompts and their initial segmentation results. In particular, a novel uncertainty-guided prompts adaptation technique is then applied automatically to derive reliable prompts and their corresponding segmentation outcomes. We validate MedSAM-U using datasets from multiple modalities to train a universal image segmentation model. Compared to MedSAM, experimental results on five distinct modal datasets demonstrate that the proposed MedSAM-U achieves an average performance improvement of 1.7\% to 20.5\% across uncertainty-guided prompts.
Diffusion Posterior Proximal Sampling for Image Restoration
Feb 25, 2024



Diffusion models have demonstrated remarkable efficacy in generating high-quality samples. Existing diffusion-based image restoration algorithms exploit pre-trained diffusion models to leverage data priors, yet they still preserve elements inherited from the unconditional generation paradigm. These strategies initiate the denoising process with pure white noise and incorporate random noise at each generative step, leading to over-smoothed results. In this paper, we introduce a refined paradigm for diffusion-based image restoration. Specifically, we opt for a sample consistent with the measurement identity at each generative step, exploiting the sampling selection as an avenue for output stability and enhancement. Besides, we start the restoration process with an initialization combined with the measurement signal, providing supplementary information to better align the generative process. Extensive experimental results and analyses validate the effectiveness of our proposed approach across diverse image restoration tasks.
Iterative Reconstruction Based on Latent Diffusion Model for Sparse Data Reconstruction
Jul 22, 2023



Reconstructing Computed tomography (CT) images from sparse measurement is a well-known ill-posed inverse problem. The Iterative Reconstruction (IR) algorithm is a solution to inverse problems. However, recent IR methods require paired data and the approximation of the inverse projection matrix. To address those problems, we present Latent Diffusion Iterative Reconstruction (LDIR), a pioneering zero-shot method that extends IR with a pre-trained Latent Diffusion Model (LDM) as a accurate and efficient data prior. By approximating the prior distribution with an unconditional latent diffusion model, LDIR is the first method to successfully integrate iterative reconstruction and LDM in an unsupervised manner. LDIR makes the reconstruction of high-resolution images more efficient. Moreover, LDIR utilizes the gradient from the data-fidelity term to guide the sampling process of the LDM, therefore, LDIR does not need the approximation of the inverse projection matrix and can solve various CT reconstruction tasks with a single model. Additionally, for enhancing the sample consistency of the reconstruction, we introduce a novel approach that uses historical gradient information to guide the gradient. Our experiments on extremely sparse CT data reconstruction tasks show that LDIR outperforms other state-of-the-art unsupervised and even exceeds supervised methods, establishing it as a leading technique in terms of both quantity and quality. Furthermore, LDIR also achieves competitive performance on nature image tasks. It is worth noting that LDIR also exhibits significantly faster execution times and lower memory consumption compared to methods with similar network settings. Our code will be publicly available.
PointShuffleNet: Learning Non-Euclidean Features with Homotopy Equivalence and Mutual Information
Mar 31, 2021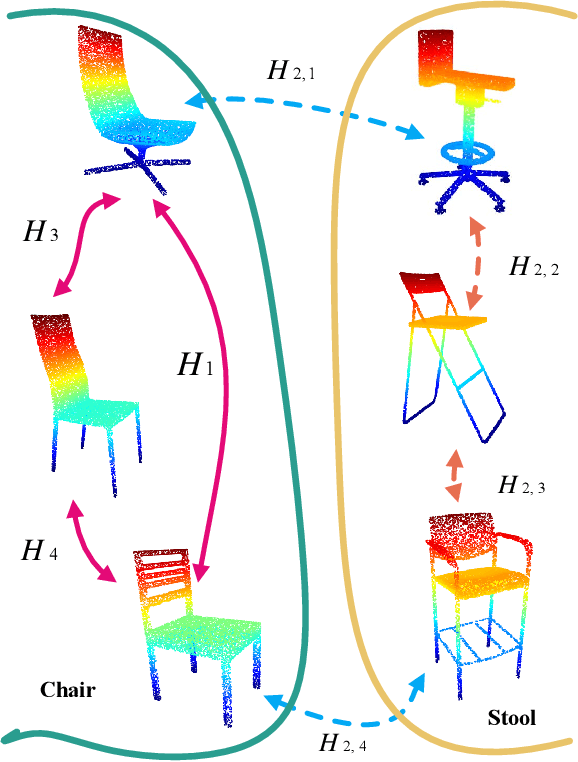
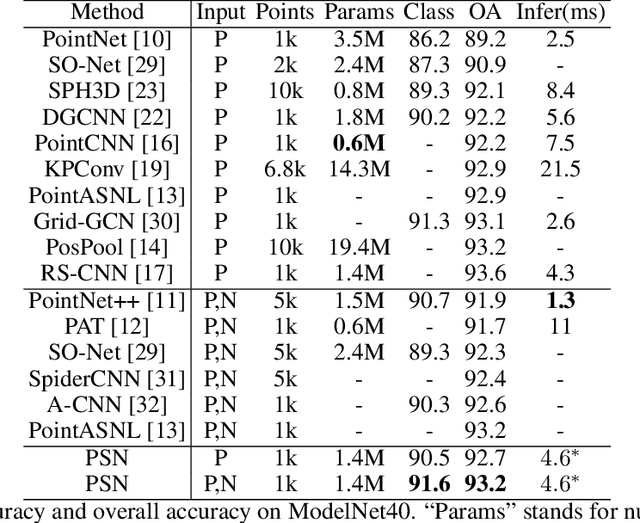
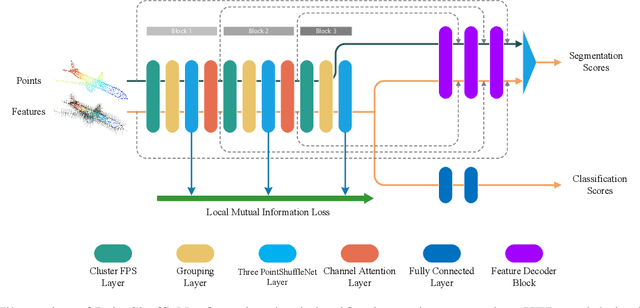
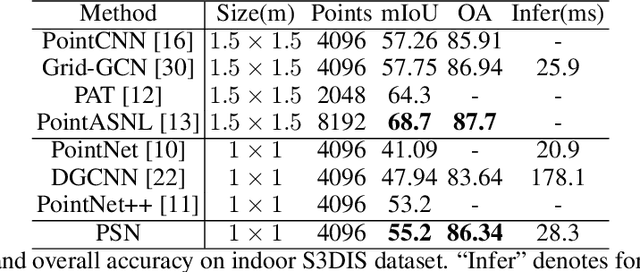
Point cloud analysis is still a challenging task due to the disorder and sparsity of samplings of their geometric structures from 3D sensors. In this paper, we introduce the homotopy equivalence relation (HER) to make the neural networks learn the data distribution from a high-dimension manifold. A shuffle operation is adopted to construct HER for its randomness and zero-parameter. In addition, inspired by prior works, we propose a local mutual information regularizer (LMIR) to cut off the trivial path that leads to a classification error from HER. LMIR utilizes mutual information to measure the distance between the original feature and HER transformed feature and learns common features in a contrastive learning scheme. Thus, we combine HER and LMIR to give our model the ability to learn non-Euclidean features from a high-dimension manifold. This is named the non-Euclidean feature learner. Furthermore, we propose a new heuristics and efficiency point sampling algorithm named ClusterFPS to obtain approximate uniform sampling but at faster speed. ClusterFPS uses a cluster algorithm to divide a point cloud into several clusters and deploy the farthest point sampling algorithm on each cluster in parallel. By combining the above methods, we propose a novel point cloud analysis neural network called PointShuffleNet (PSN), which shows great promise in point cloud classification and segmentation. Extensive experiments show that our PSN achieves state-of-the-art results on ModelNet40, ShapeNet and S3DIS with high efficiency. Theoretically, we provide mathematical analysis toward understanding of what the data distribution HER has developed and why LMIR can drop the trivial path by maximizing mutual information implicitly.