 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-Next: Lexicalizing Modalities as Discrete Tokens
Mar 29, 2026The prevailing Next-Token Prediction (NTP) paradigm has driven the success of large language models through discrete autoregressive modeling. However, contemporary multimodal systems remain language-centric, often treating non-linguistic modalities as external attachments, leading to fragmented architectures and suboptimal integration. To transcend this limitation, we introduce Discrete Native Autoregressive (DiNA), a unified framework that represents multimodal information within a shared discrete space, enabling a consistent and principled autoregressive modeling across modalities. A key innovation is the Discrete Native Any-resolution Visual Transformer (dNaViT), which performs tokenization and de-tokenization at arbitrary resolutions, transforming continuous visual signals into hierarchical discrete tokens. Building on this foundation, we develop LongCat-Next, a native multimodal model that processes text, vision, and audio under a single autoregressive objective with minimal modality-specific design. As an industrial-strength foundation model, it excels at seeing, painting, and talking within a single framework, achieving strong performance across a wide range of multimodal benchmarks. In particular, LongCat-Next addresses the long-standing performance ceiling of discrete vision modeling on understanding tasks and provides a unified approach to effectively reconcile the conflict between understanding and generation. As an attempt toward native multimodality, we open-source the LongCat-Next and its tokenizers, hoping to foster further research and development in the community. GitHub: https://github.com/meituan-longcat/LongCat-Next
AutoWeather4D: Autonomous Driving Video Weather Conversion via G-Buffer Dual-Pass Editing
Mar 27, 2026Generative video models have significantly advanced the photorealistic synthesis of adverse weather for autonomous driving; however, they consistently demand massive datasets to learn rare weather scenarios. While 3D-aware editing methods alleviate these data constraints by augmenting existing video footage, they are fundamentally bottlenecked by costly per-scene optimization and suffer from inherent geometric and illumination entanglement. In this work, we introduce AutoWeather4D, a feed-forward 3D-aware weather editing framework designed to explicitly decouple geometry and illumination. At the core of our approach is a G-buffer Dual-pass Editing mechanism. The Geometry Pass leverages explicit structural foundations to enable surface-anchored physical interactions, while the Light Pass analytically resolves light transport, accumulating the contributions of local illuminants into the global illumination to enable dynamic 3D local relighting. Extensive experiments demonstrate that AutoWeather4D achieves comparable photorealism and structural consistency to generative baselines while enabling fine-grained parametric physical control, serving as a practical data engine for autonomous driving.
UniTEX: Universal High Fidelity Generative Texturing for 3D Shapes
May 29, 2025We present UniTEX, a novel two-stage 3D texture generation framework to create high-quality, consistent textures for 3D assets. Existing approaches predominantly rely on UV-based inpainting to refine textures after reprojecting the generated multi-view images onto the 3D shapes, which introduces challenges related to topological ambiguity. To address this, we propose to bypass the limitations of UV mapping by operating directly in a unified 3D functional space. Specifically, we first propose that lifts texture generation into 3D space via Texture Functions (TFs)--a continuous, volumetric representation that maps any 3D point to a texture value based solely on surface proximity, independent of mesh topology. Then, we propose to predict these TFs directly from images and geometry inputs using a transformer-based Large Texturing Model (LTM). To further enhance texture quality and leverage powerful 2D priors, we develop an advanced LoRA-based strategy for efficiently adapting large-scale Diffusion Transformers (DiTs) for high-quality multi-view texture synthesis as our first stage. Extensive experiments demonstrate that UniTEX achieves superior visual quality and texture integrity compared to existing approaches, offering a generalizable and scalable solution for automated 3D texture generation. Code will available in: https://github.com/YixunLiang/UniTEX.
GaussianAvatar-Editor: Photorealistic Animatable Gaussian Head Avatar Editor
Jan 17, 2025We introduce GaussianAvatar-Editor, an innovative framework for text-driven editing of animatable Gaussian head avatars that can be fully controlled in expression, pose, and viewpoint. Unlike static 3D Gaussian editing, editing animatable 4D Gaussian avatars presents challenges related to motion occlusion and spatial-temporal inconsistency. To address these issues, we propose the Weighted Alpha Blending Equation (WABE). This function enhances the blending weight of visible Gaussians while suppressing the influence on non-visible Gaussians, effectively handling motion occlusion during editing. Furthermore, to improve editing quality and ensure 4D consistency, we incorporate conditional adversarial learning into the editing process. This strategy helps to refine the edited results and maintain consistency throughout the animation. By integrating these methods, our GaussianAvatar-Editor achieves photorealistic and consistent results in animatable 4D Gaussian editing. We conduct comprehensive experiments across various subjects to validate the effectiveness of our proposed techniques, which demonstrates the superiority of our approach over existing methods. More results and code are available at: [Project Link](https://xiangyueliu.github.io/GaussianAvatar-Editor/).
PointRegGPT: Boosting 3D Point Cloud Registration using Generative Point-Cloud Pairs for Training
Jul 19, 2024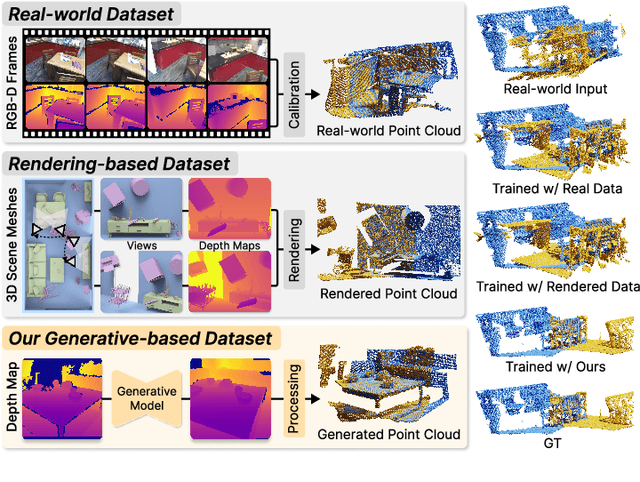
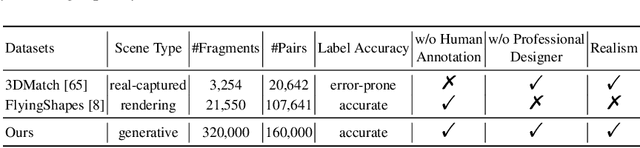


Data plays a crucial role in training learning-based methods for 3D point cloud registration. However, the real-world dataset is expensive to build, while rendering-based synthetic data suffers from domain gaps. In this work, we present PointRegGPT, boosting 3D point cloud registration using generative point-cloud pairs for training. Given a single depth map, we first apply a random camera motion to re-project it into a target depth map. Converting them to point clouds gives a training pair. To enhance the data realism, we formulate a generative model as a depth inpainting diffusion to process the target depth map with the re-projected source depth map as the condition. Also, we design a depth correction module to alleviate artifacts caused by point penetration during the re-projection. To our knowledge, this is the first generative approach that explores realistic data generation for indoor point cloud registration. When equipped with our approach, several recent algorithms can improve their performance significantly and achieve SOTA consistently on two common benchmarks. The code and dataset will be released on https://github.com/Chen-Suyi/PointRegGPT.
GenN2N: Generative NeRF2NeRF Translation
Apr 03, 2024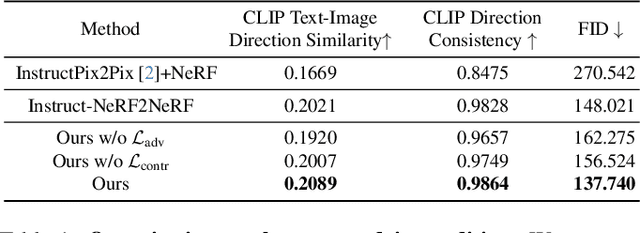
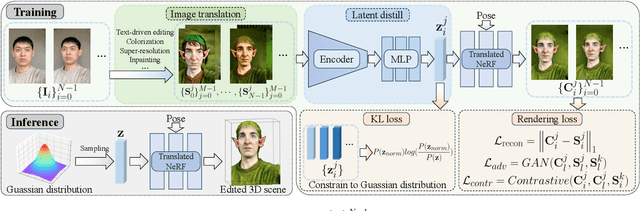
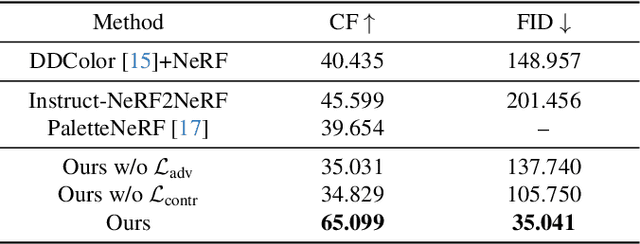

We present GenN2N, a unified NeRF-to-NeRF translation framework for various NeRF translation tasks such as text-driven NeRF editing, colorization, super-resolution, inpainting, etc. Unlike previous methods designed for individual translation tasks with task-specific schemes, GenN2N achieves all these NeRF editing tasks by employing a plug-and-play image-to-image translator to perform editing in the 2D domain and lifting 2D edits into the 3D NeRF space. Since the 3D consistency of 2D edits may not be assured, we propose to model the distribution of the underlying 3D edits through a generative model that can cover all possible edited NeRFs. To model the distribution of 3D edited NeRFs from 2D edited images, we carefully design a VAE-GAN that encodes images while decoding NeRFs. The latent space is trained to align with a Gaussian distribution and the NeRFs are supervised through an adversarial loss on its renderings. To ensure the latent code does not depend on 2D viewpoints but truly reflects the 3D edits, we also regularize the latent code through a contrastive learning scheme. Extensive experiments on various editing tasks show GenN2N, as a universal framework, performs as well or better than task-specific specialists while possessing flexible generative power. More results on our project page: https://xiangyueliu.github.io/GenN2N/
Diffusion Posterior Proximal Sampling for Image Restoration
Feb 25, 2024



Diffusion models have demonstrated remarkable efficacy in generating high-quality samples. Existing diffusion-based image restoration algorithms exploit pre-trained diffusion models to leverage data priors, yet they still preserve elements inherited from the unconditional generation paradigm. These strategies initiate the denoising process with pure white noise and incorporate random noise at each generative step, leading to over-smoothed results. In this paper, we introduce a refined paradigm for diffusion-based image restoration. Specifically, we opt for a sample consistent with the measurement identity at each generative step, exploiting the sampling selection as an avenue for output stability and enhancement. Besides, we start the restoration process with an initialization combined with the measurement signal, providing supplementary information to better align the generative process. Extensive experimental results and analyses validate the effectiveness of our proposed approach across diverse image restoration tasks.
Ctrl-Room: Controllable Text-to-3D Room Meshes Generation with Layout Constraints
Oct 09, 2023



Text-driven 3D indoor scene generation could be useful for gaming, film industry, and AR/VR applications. However, existing methods cannot faithfully capture the room layout, nor do they allow flexible editing of individual objects in the room. To address these problems, we present Ctrl-Room, which is able to generate convincing 3D rooms with designer-style layouts and high-fidelity textures from just a text prompt. Moreover, Ctrl-Room enables versatile interactive editing operations such as resizing or moving individual furniture items. Our key insight is to separate the modeling of layouts and appearance. %how to model the room that takes into account both scene texture and geometry at the same time. To this end, Our proposed method consists of two stages, a `Layout Generation Stage' and an `Appearance Generation Stage'. The `Layout Generation Stage' trains a text-conditional diffusion model to learn the layout distribution with our holistic scene code parameterization. Next, the `Appearance Generation Stage' employs a fine-tuned ControlNet to produce a vivid panoramic image of the room guided by the 3D scene layout and text prompt. In this way, we achieve a high-quality 3D room with convincing layouts and lively textures. Benefiting from the scene code parameterization, we can easily edit the generated room model through our mask-guided editing module, without expensive editing-specific training. Extensive experiments on the Structured3D dataset demonstrate that our method outperforms existing methods in producing more reasonable, view-consistent, and editable 3D rooms from natural language prompts.
AccFlow: Backward Accumulation for Long-Range Optical Flow
Aug 25, 2023
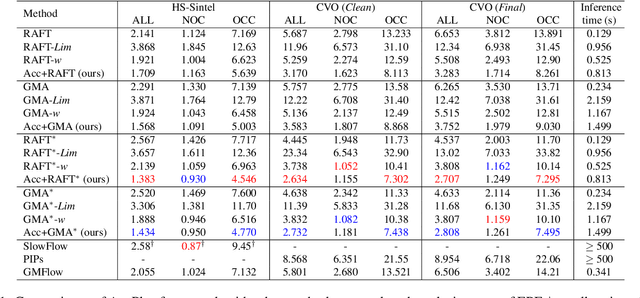
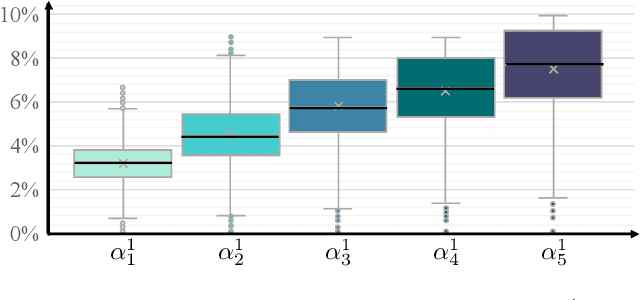
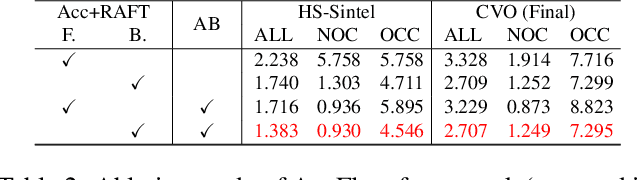
Recent deep learning-based optical flow estimators have exhibited impressive performance in generating local flows between consecutive frames. However, the estimation of long-range flows between distant frames, particularly under complex object deformation and large motion occlusion, remains a challenging task. One promising solution is to accumulate local flows explicitly or implicitly to obtain the desired long-range flow. Nevertheless, the accumulation errors and flow misalignment can hinder the effectiveness of this approach. This paper proposes a novel recurrent framework called AccFlow, which recursively backward accumulates local flows using a deformable module called as AccPlus. In addition, an adaptive blending module is designed along with AccPlus to alleviate the occlusion effect by backward accumulation and rectify the accumulation error. Notably, we demonstrate the superiority of backward accumulation over conventional forward accumulation, which to the best of our knowledge has not been explicitly established before. To train and evaluate the proposed AccFlow, we have constructed a large-scale high-quality dataset named CVO, which provides ground-truth optical flow labels between adjacent and distant frames. Extensive experiments validate the effectiveness of AccFlow in handling long-range optical flow estimation. Codes are available at https://github.com/mulns/AccFlow .
Iterative Reconstruction Based on Latent Diffusion Model for Sparse Data Reconstruction
Jul 22, 2023



Reconstructing Computed tomography (CT) images from sparse measurement is a well-known ill-posed inverse problem. The Iterative Reconstruction (IR) algorithm is a solution to inverse problems. However, recent IR methods require paired data and the approximation of the inverse projection matrix. To address those problems, we present Latent Diffusion Iterative Reconstruction (LDIR), a pioneering zero-shot method that extends IR with a pre-trained Latent Diffusion Model (LDM) as a accurate and efficient data prior. By approximating the prior distribution with an unconditional latent diffusion model, LDIR is the first method to successfully integrate iterative reconstruction and LDM in an unsupervised manner. LDIR makes the reconstruction of high-resolution images more efficient. Moreover, LDIR utilizes the gradient from the data-fidelity term to guide the sampling process of the LDM, therefore, LDIR does not need the approximation of the inverse projection matrix and can solve various CT reconstruction tasks with a single model. Additionally, for enhancing the sample consistency of the reconstruction, we introduce a novel approach that uses historical gradient information to guide the gradient. Our experiments on extremely sparse CT data reconstruction tasks show that LDIR outperforms other state-of-the-art unsupervised and even exceeds supervised methods, establishing it as a leading technique in terms of both quantity and quality. Furthermore, LDIR also achieves competitive performance on nature image tasks. It is worth noting that LDIR also exhibits significantly faster execution times and lower memory consumption compared to methods with similar network settings. Our code will be publicly available.