 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollision-Free Humanoid Traversal in Cluttered Indoor Scenes
Jan 23, 2026We study the problem of collision-free humanoid traversal in cluttered indoor scenes, such as hurdling over objects scattered on the floor, crouching under low-hanging obstacles, or squeezing through narrow passages. To achieve this goal, the humanoid needs to map its perception of surrounding obstacles with diverse spatial layouts and geometries to the corresponding traversal skills. However, the lack of an effective representation that captures humanoid-obstacle relationships during collision avoidance makes directly learning such mappings difficult. We therefore propose Humanoid Potential Field (HumanoidPF), which encodes these relationships as collision-free motion directions, significantly facilitating RL-based traversal skill learning. We also find that HumanoidPF exhibits a surprisingly negligible sim-to-real gap as a perceptual representation. To further enable generalizable traversal skills through diverse and challenging cluttered indoor scenes, we further propose a hybrid scene generation method, incorporating crops of realistic 3D indoor scenes and procedurally synthesized obstacles. We successfully transfer our policy to the real world and develop a teleoperation system where users could command the humanoid to traverse in cluttered indoor scenes with just a single click. Extensive experiments are conducted in both simulation and the real world to validate the effectiveness of our method. Demos and code can be found in our website: https://axian12138.github.io/CAT/.
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025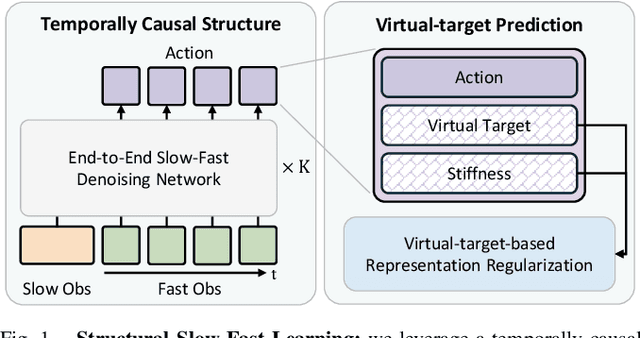
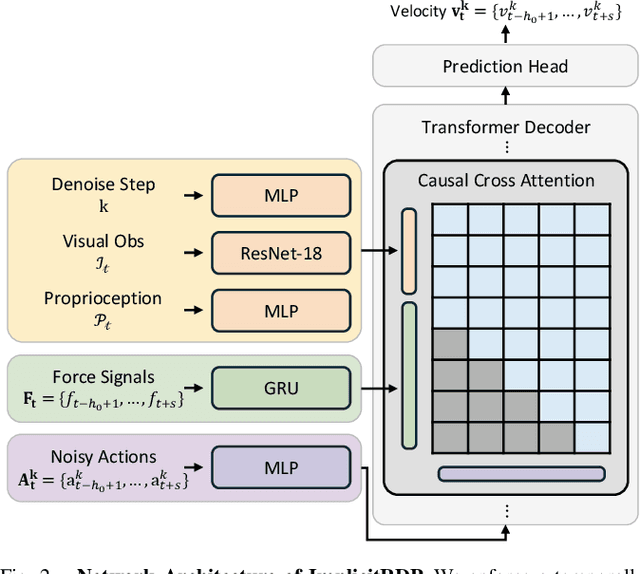


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.
Right-Side-Out: Learning Zero-Shot Sim-to-Real Garment Reversal
Sep 19, 2025Turning garments right-side out is a challenging manipulation task: it is highly dynamic, entails rapid contact changes, and is subject to severe visual occlusion. We introduce Right-Side-Out, a zero-shot sim-to-real framework that effectively solves this challenge by exploiting task structures. We decompose the task into Drag/Fling to create and stabilize an access opening, followed by Insert&Pull to invert the garment. Each step uses a depth-inferred, keypoint-parameterized bimanual primitive that sharply reduces the action space while preserving robustness. Efficient data generation is enabled by our custom-built, high-fidelity, GPU-parallel Material Point Method (MPM) simulator that models thin-shell deformation and provides robust and efficient contact handling for batched rollouts. Built on the simulator, our fully automated pipeline scales data generation by randomizing garment geometry, material parameters, and viewpoints, producing depth, masks, and per-primitive keypoint labels without any human annotations. With a single depth camera, policies trained entirely in simulation deploy zero-shot on real hardware, achieving up to 81.3% success rate. By employing task decomposition and high fidelity simulation, our framework enables tackling highly dynamic, severely occluded tasks without laborious human demonstrations.
Track Any Motions under Any Disturbances
Sep 17, 2025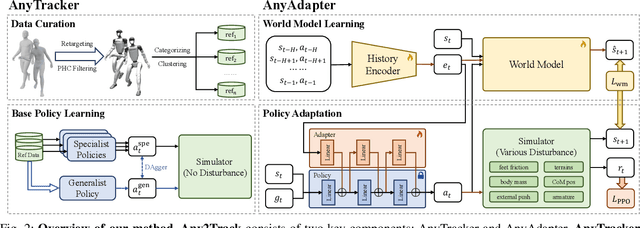

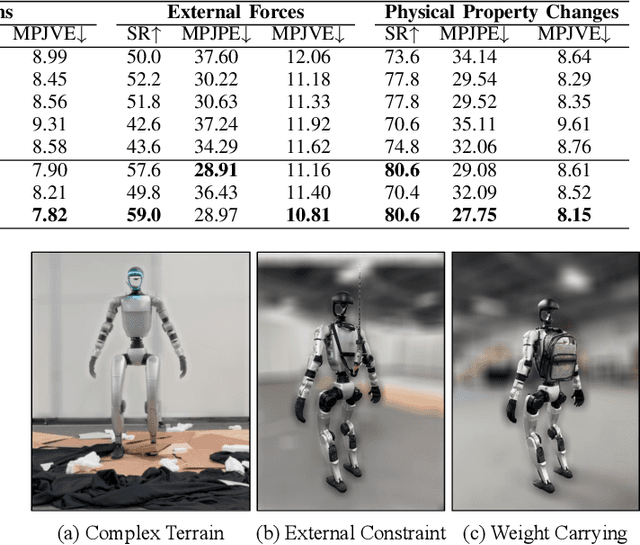

A foundational humanoid motion tracker is expected to be able to track diverse, highly dynamic, and contact-rich motions. More importantly, it needs to operate stably in real-world scenarios against various dynamics disturbances, including terrains, external forces, and physical property changes for general practical use. To achieve this goal, we propose Any2Track (Track Any motions under Any disturbances), a two-stage RL framework to track various motions under multiple disturbances in the real world. Any2Track reformulates dynamics adaptability as an additional capability on top of basic action execution and consists of two key components: AnyTracker and AnyAdapter. AnyTracker is a general motion tracker with a series of careful designs to track various motions within a single policy. AnyAdapter is a history-informed adaptation module that endows the tracker with online dynamics adaptability to overcome the sim2real gap and multiple real-world disturbances. We deploy Any2Track on Unitree G1 hardware and achieve a successful sim2real transfer in a zero-shot manner. Any2Track performs exceptionally well in tracking various motions under multiple real-world disturbances.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
May 16, 2025Humans possess a large reachable space in the 3D world, enabling interaction with objects at varying heights and distances. However, realizing such large-space reaching on humanoids is a complex whole-body control problem and requires the robot to master diverse skills simultaneously-including base positioning and reorientation, height and body posture adjustments, and end-effector pose control. Learning from scratch often leads to optimization difficulty and poor sim2real transferability. To address this challenge, we propose Real-world-Ready Skill Space (R2S2). Our approach begins with a carefully designed skill library consisting of real-world-ready primitive skills. We ensure optimal performance and robust sim2real transfer through individual skill tuning and sim2real evaluation. These skills are then ensembled into a unified latent space, serving as a structured prior that helps task execution in an efficient and sim2real transferable manner. A high-level planner, trained to sample skills from this space, enables the robot to accomplish real-world goal-reaching tasks. We demonstrate zero-shot sim2real transfer and validate R2S2 in multiple challenging goal-reaching scenarios.
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.
Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation
Mar 04, 2025Humans can accomplish complex contact-rich tasks using vision and touch, with highly reactive capabilities such as quick adjustments to environmental changes and adaptive control of contact forces; however, this remains challenging for robots. Existing visual imitation learning (IL) approaches rely on action chunking to model complex behaviors, which lacks the ability to respond instantly to real-time tactile feedback during the chunk execution. Furthermore, most teleoperation systems struggle to provide fine-grained tactile / force feedback, which limits the range of tasks that can be performed. To address these challenges, we introduce TactAR, a low-cost teleoperation system that provides real-time tactile feedback through Augmented Reality (AR), along with Reactive Diffusion Policy (RDP), a novel slow-fast visual-tactile imitation learning algorithm for learning contact-rich manipulation skills. RDP employs a two-level hierarchy: (1) a slow latent diffusion policy for predicting high-level action chunks in latent space at low frequency, (2) a fast asymmetric tokenizer for closed-loop tactile feedback control at high frequency. This design enables both complex trajectory modeling and quick reactive behavior within a unified framework. Through extensive evaluation across three challenging contact-rich tasks, RDP significantly improves performance compared to state-of-the-art visual IL baselines through rapid response to tactile / force feedback. Furthermore, experiments show that RDP is applicable across different tactile / force sensors. Code and videos are available on https://reactive-diffusion-policy.github.io/.
DeformPAM: Data-Efficient Learning for Long-horizon Deformable Object Manipulation via Preference-based Action Alignment
Oct 15, 2024In recent years, imitation learning has made progress in the field of robotic manipulation. However, it still faces challenges when dealing with complex long-horizon deformable object tasks, such as high-dimensional state spaces, complex dynamics, and multimodal action distributions. Traditional imitation learning methods often require a large amount of data and encounter distributional shifts and accumulative errors in these tasks. To address these issues, we propose a data-efficient general learning framework (DeformPAM) based on preference learning and reward-guided action selection. DeformPAM decomposes long-horizon tasks into multiple action primitives, utilizes 3D point cloud inputs and diffusion models to model action distributions, and trains an implicit reward model using human preference data. During the inference phase, the reward model scores multiple candidate actions, selecting the optimal action for execution, thereby reducing the occurrence of anomalous actions and improving task completion quality. Experiments conducted on three challenging real-world long-horizon deformable object manipulation tasks demonstrate the effectiveness of this method. Results show that DeformPAM improves both task completion quality and efficiency compared to baseline methods even with limited data. Code and data will be available at https://deform-pam.robotflow.ai.
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Sep 04, 2024
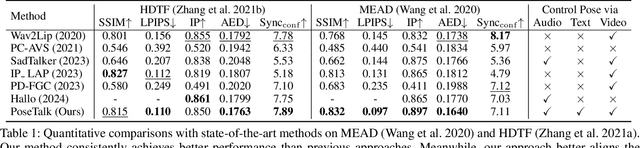
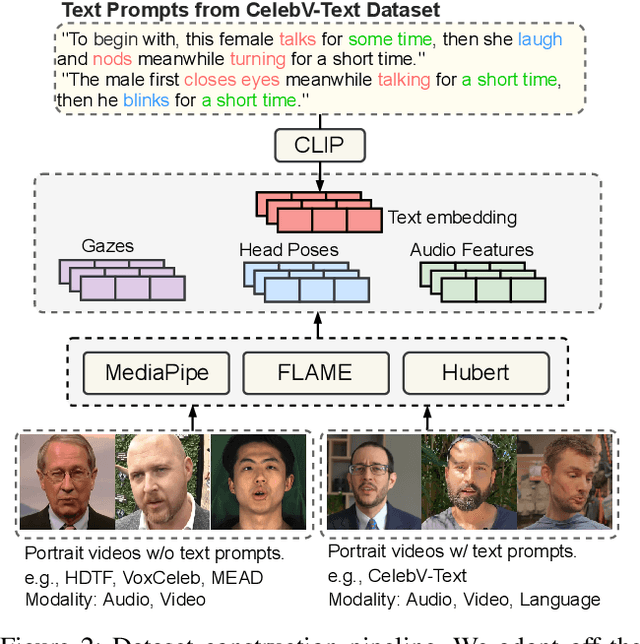
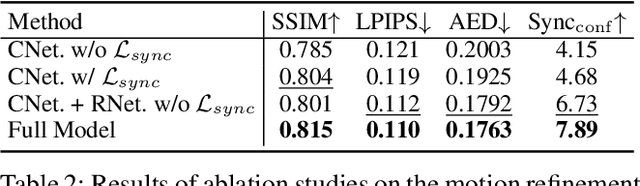
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose \textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4\% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.
In-Context Translation: Towards Unifying Image Recognition, Processing, and Generation
Apr 15, 2024



We propose In-Context Translation (ICT), a general learning framework to unify visual recognition (e.g., semantic segmentation), low-level image processing (e.g., denoising), and conditional image generation (e.g., edge-to-image synthesis). Thanks to unification, ICT significantly reduces the inherent inductive bias that comes with designing models for specific tasks, and it maximizes mutual enhancement across similar tasks. However, the unification across a large number of tasks is non-trivial due to various data formats and training pipelines. To this end, ICT introduces two designs. Firstly, it standardizes input-output data of different tasks into RGB image pairs, e.g., semantic segmentation data pairs an RGB image with its segmentation mask in the same RGB format. This turns different tasks into a general translation task between two RGB images. Secondly, it standardizes the training of different tasks into a general in-context learning, where "in-context" means the input comprises an example input-output pair of the target task and a query image. The learning objective is to generate the "missing" data paired with the query. The implicit translation process is thus between the query and the generated image. In experiments, ICT unifies ten vision tasks and showcases impressive performance on their respective benchmarks. Notably, compared to its competitors, e.g., Painter and PromptDiffusion, ICT trained on only 4 RTX 3090 GPUs is shown to be more efficient and less costly in training.