 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenRoboCare: A Multimodal Multi-Task Expert Demonstration Dataset for Robot Caregiving
Nov 17, 2025We present OpenRoboCare, a multimodal dataset for robot caregiving, capturing expert occupational therapist demonstrations of Activities of Daily Living (ADLs). Caregiving tasks involve complex physical human-robot interactions, requiring precise perception under occlusions, safe physical contact, and long-horizon planning. While recent advances in robot learning from demonstrations have shown promise, there is a lack of a large-scale, diverse, and expert-driven dataset that captures real-world caregiving routines. To address this gap, we collect data from 21 occupational therapists performing 15 ADL tasks on two manikins. The dataset spans five modalities: RGB-D video, pose tracking, eye-gaze tracking, task and action annotations, and tactile sensing, providing rich multimodal insights into caregiver movement, attention, force application, and task execution strategies. We further analyze expert caregiving principles and strategies, offering insights to improve robot efficiency and task feasibility. Additionally, our evaluations demonstrate that OpenRoboCare presents challenges for state-of-the-art robot perception and human activity recognition methods, both critical for developing safe and adaptive assistive robots, highlighting the value of our contribution. See our website for additional visualizations: https://emprise.cs.cornell.edu/robo-care/.
CART-MPC: Coordinating Assistive Devices for Robot-Assisted Transferring with Multi-Agent Model Predictive Control
Jan 19, 2025



Bed-to-wheelchair transferring is a ubiquitous activity of daily living (ADL), but especially challenging for caregiving robots with limited payloads. We develop a novel algorithm that leverages the presence of other assistive devices: a Hoyer sling and a wheelchair for coarse manipulation of heavy loads, alongside a robot arm for fine-grained manipulation of deformable objects (Hoyer sling straps). We instrument the Hoyer sling and wheelchair with actuators and sensors so that they can become intelligent agents in the algorithm. We then focus on one subtask of the transferring ADL -- tying Hoyer sling straps to the sling bar -- that exemplifies the challenges of transfer: multi-agent planning, deformable object manipulation, and generalization to varying hook shapes, sling materials, and care recipient bodies. To address these challenges, we propose CART-MPC, a novel algorithm based on turn-taking multi-agent model predictive control that uses a learned neural dynamics model for a keypoint-based representation of the deformable Hoyer sling strap, and a novel cost function that leverages linking numbers from knot theory and neural amortization to accelerate inference. We validate it in both RCareWorld simulation and real-world environments. In simulation, CART-MPC successfully generalizes across diverse hook designs, sling materials, and care recipient body shapes. In the real world, we show zero-shot sim-to-real generalization capabilities to tie deformable Hoyer sling straps on a sling bar towards transferring a manikin from a hospital bed to a wheelchair. See our website for supplementary materials: https://emprise.cs.cornell.edu/cart-mpc/.
REPeat: A Real2Sim2Real Approach for Pre-acquisition of Soft Food Items in Robot-assisted Feeding
Oct 13, 2024



The paper presents REPeat, a Real2Sim2Real framework designed to enhance bite acquisition in robot-assisted feeding for soft foods. It uses `pre-acquisition actions' such as pushing, cutting, and flipping to improve the success rate of bite acquisition actions such as skewering, scooping, and twirling. If the data-driven model predicts low success for direct bite acquisition, the system initiates a Real2Sim phase, reconstructing the food's geometry in a simulation. The robot explores various pre-acquisition actions in the simulation, then a Sim2Real step renders a photorealistic image to reassess success rates. If the success improves, the robot applies the action in reality. We evaluate the system on 15 diverse plates with 10 types of food items for a soft food diet, showing improvement in bite acquisition success rates by 27\% on average across all plates. See our project website at https://emprise.cs.cornell.edu/repeat.
MORPHeus: a Multimodal One-armed Robot-assisted Peeling System with Human Users In-the-loop
Apr 09, 2024Meal preparation is an important instrumental activity of daily living~(IADL). While existing research has explored robotic assistance in meal preparation tasks such as cutting and cooking, the crucial task of peeling has received less attention. Robot-assisted peeling, conventionally a bimanual task, is challenging to deploy in the homes of care recipients using two wheelchair-mounted robot arms due to ergonomic and transferring challenges. This paper introduces a robot-assisted peeling system utilizing a single robotic arm and an assistive cutting board, inspired by the way individuals with one functional hand prepare meals. Our system incorporates a multimodal active perception module to determine whether an area on the food is peeled, a human-in-the-loop long-horizon planner to perform task planning while catering to a user's preference for peeling coverage, and a compliant controller to peel the food items. We demonstrate the system on 12 food items representing the extremes of different shapes, sizes, skin thickness, surface textures, skin vs flesh colors, and deformability.
Visual-Tactile Sensing for In-Hand Object Reconstruction
Mar 25, 2023Tactile sensing is one of the modalities humans rely on heavily to perceive the world. Working with vision, this modality refines local geometry structure, measures deformation at the contact area, and indicates the hand-object contact state. With the availability of open-source tactile sensors such as DIGIT, research on visual-tactile learning is becoming more accessible and reproducible. Leveraging this tactile sensor, we propose a novel visual-tactile in-hand object reconstruction framework \textbf{VTacO}, and extend it to \textbf{VTacOH} for hand-object reconstruction. Since our method can support both rigid and deformable object reconstruction, no existing benchmarks are proper for the goal. We propose a simulation environment, VT-Sim, which supports generating hand-object interaction for both rigid and deformable objects. With VT-Sim, we generate a large-scale training dataset and evaluate our method on it. Extensive experiments demonstrate that our proposed method can outperform the previous baseline methods qualitatively and quantitatively. Finally, we directly apply our model trained in simulation to various real-world test cases, which display qualitative results. Codes, models, simulation environment, and datasets are available at \url{https://sites.google.com/view/vtaco/}.
GarmentTracking: Category-Level Garment Pose Tracking
Mar 24, 2023Garments are important to humans. A visual system that can estimate and track the complete garment pose can be useful for many downstream tasks and real-world applications. In this work, we present a complete package to address the category-level garment pose tracking task: (1) A recording system VR-Garment, with which users can manipulate virtual garment models in simulation through a VR interface. (2) A large-scale dataset VR-Folding, with complex garment pose configurations in manipulation like flattening and folding. (3) An end-to-end online tracking framework GarmentTracking, which predicts complete garment pose both in canonical space and task space given a point cloud sequence. Extensive experiments demonstrate that the proposed GarmentTracking achieves great performance even when the garment has large non-rigid deformation. It outperforms the baseline approach on both speed and accuracy. We hope our proposed solution can serve as a platform for future research. Codes and datasets are available in https://garment-tracking.robotflow.ai.
RCareWorld: A Human-centric Simulation World for Caregiving Robots
Oct 19, 2022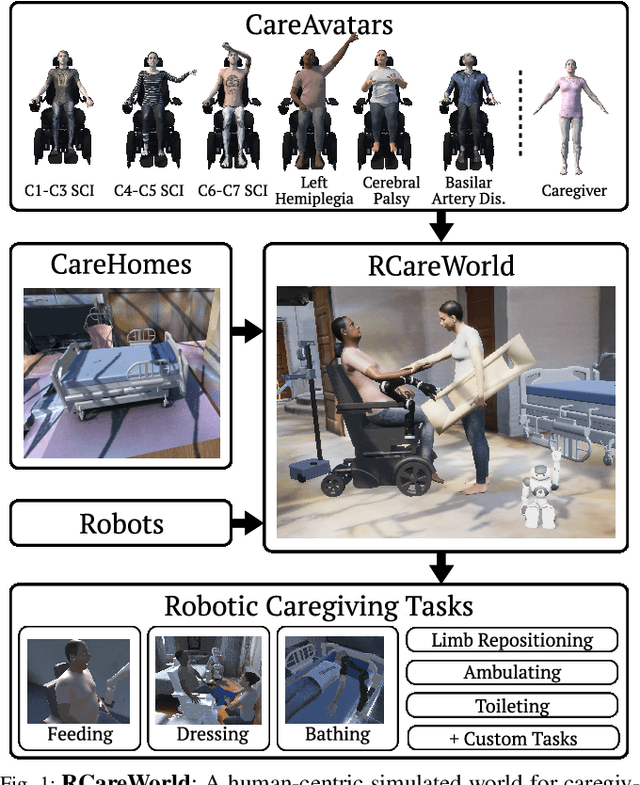
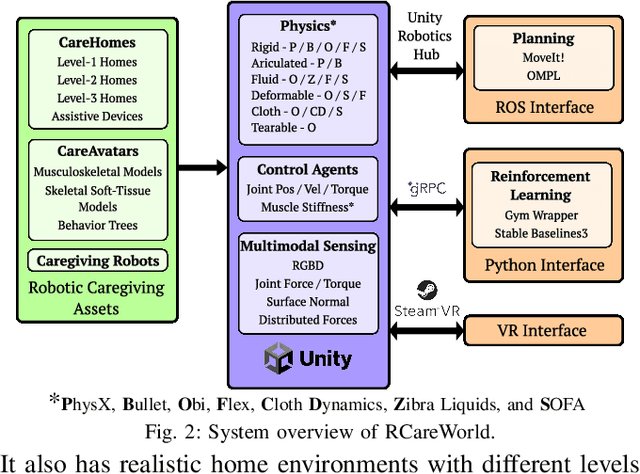
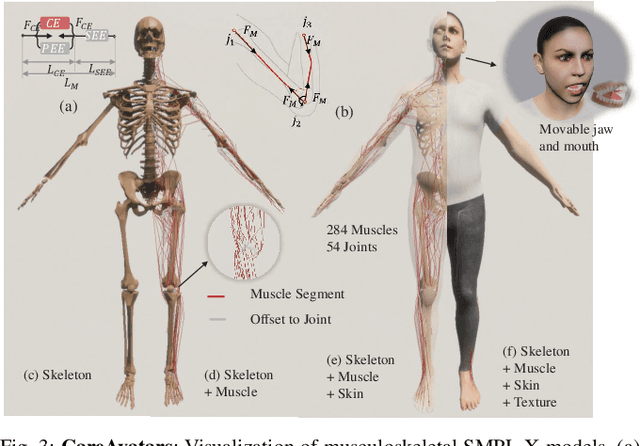
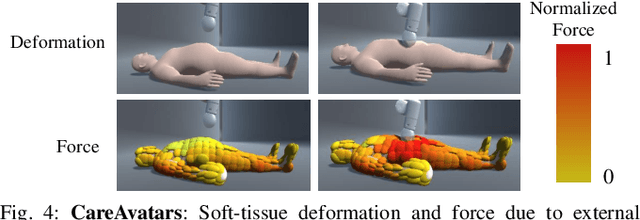
We present RCareWorld, a human-centric simulation world for physical and social robotic caregiving designed with inputs from stakeholders, including care recipients, caregivers, occupational therapists, and roboticists. RCareWorld has realistic human models of care recipients with mobility limitations and caregivers, home environments with multiple levels of accessibility and assistive devices, and robots commonly used for caregiving. It interfaces with various physics engines to model diverse material types necessary for simulating caregiving scenarios, and provides the capability to plan, control, and learn both human and robot control policies by integrating with state-of-the-art external planning and learning libraries, and VR devices. We propose a set of realistic caregiving tasks in RCareWorld as a benchmark for physical robotic caregiving and provide baseline control policies for them. We illustrate the high-fidelity simulation capabilities of RCareWorld by demonstrating the execution of a policy learnt in simulation for one of these tasks on a real-world setup. Additionally, we perform a real-world social robotic caregiving experiment using behaviors modeled in RCareWorld. Robotic caregiving, though potentially impactful towards enhancing the quality of life of care recipients and caregivers, is a field with many barriers to entry due to its interdisciplinary facets. RCareWorld takes the first step towards building a realistic simulation world for robotic caregiving that would enable researchers worldwide to contribute to this impactful field. Demo videos and supplementary materials can be found at: https://emprise.cs.cornell.edu/rcareworld/.
RFUniverse: A Physics-based Action-centric Interactive Environment for Everyday Household Tasks
Feb 01, 2022Household environments are important testbeds for embodied AI research. Many simulation environments have been proposed to develop learning models for solving everyday household tasks. However, though interactions are paid attention to in most environments, the actions operating on the objects are not well supported concerning action types, object types, and interaction physics. To bridge the gap at the action level, we propose a novel physics-based action-centric environment, RFUniverse, for robot learning of everyday household tasks. RFUniverse supports interactions among 87 atomic actions and 8 basic object types in a visually and physically plausible way. To demonstrate the usability of the simulation environment, we perform learning algorithms on various types of tasks, namely fruit-picking, cloth-folding and sponge-wiping for manipulation, stair-chasing for locomotion, room-cleaning for multi-agent collaboration, milk-pouring for task and motion planning, and bimanual-lifting for behavior cloning from VR interface. Client-side Python APIs, learning codes, models, and the database will be released. Demo video for atomic actions can be found in supplementary materials: \url{https://sites.google.com/view/rfuniverse}
ContourRender: Detecting Arbitrary Contour Shape For Instance Segmentation In One Pass
Jun 07, 2021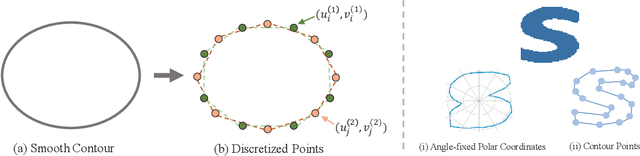
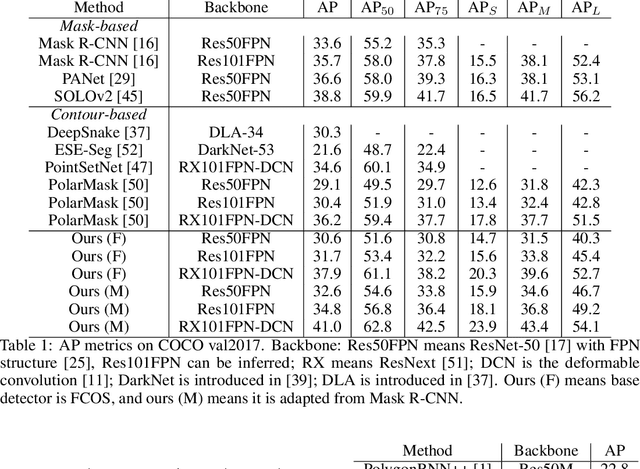
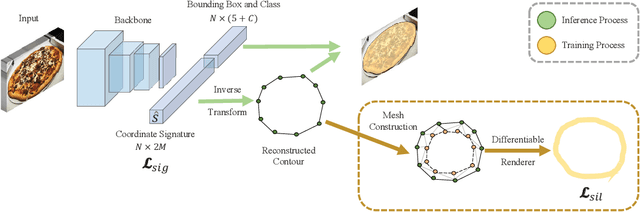
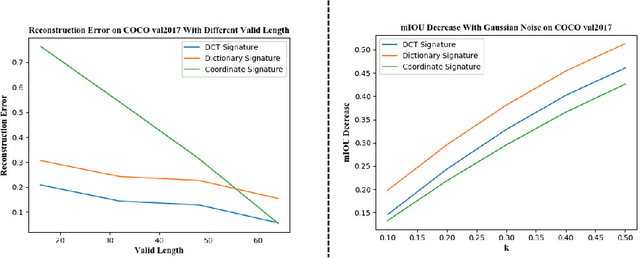
Direct contour regression for instance segmentation is a challenging task. Previous works usually achieve it by learning to progressively refine the contour prediction or adopting a shape representation with limited expressiveness. In this work, we argue that the difficulty in regressing the contour points in one pass is mainly due to the ambiguity when discretizing a smooth contour into a polygon. To address the ambiguity, we propose a novel differentiable rendering-based approach named \textbf{ContourRender}. During training, it first predicts a contour generated by an invertible shape signature, and then optimizes the contour with the more stable silhouette by converting it to a contour mesh and rendering the mesh to a 2D map. This method significantly improves the quality of contour without iterations or cascaded refinements. Moreover, as optimization is not needed during inference, the inference speed will not be influenced. Experiments show the proposed ContourRender outperforms all the contour-based instance segmentation approaches on COCO, while stays competitive with the iteration-based state-of-the-art on Cityscapes. In addition, we specifically select a subset from COCO val2017 named COCO ContourHard-val to further demonstrate the contour quality improvements. Codes, models, and dataset split will be released.
H2O: A Benchmark for Visual Human-human Object Handover Analysis
Apr 23, 2021
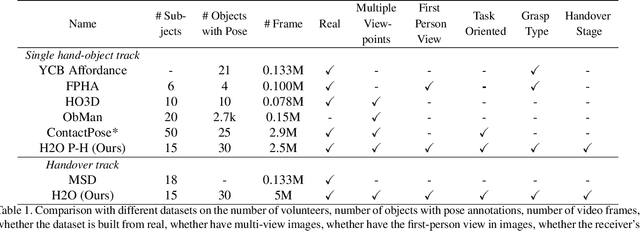

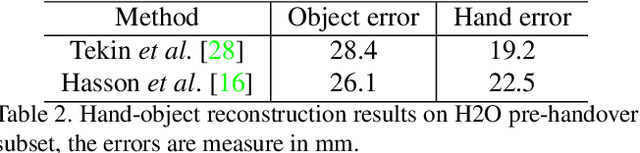
Object handover is a common human collaboration behavior that attracts attention from researchers in Robotics and Cognitive Science. Though visual perception plays an important role in the object handover task, the whole handover process has been specifically explored. In this work, we propose a novel rich-annotated dataset, H2O, for visual analysis of human-human object handovers. The H2O, which contains 18K video clips involving 15 people who hand over 30 objects to each other, is a multi-purpose benchmark. It can support several vision-based tasks, from which, we specifically provide a baseline method, RGPNet, for a less-explored task named Receiver Grasp Prediction. Extensive experiments show that the RGPNet can produce plausible grasps based on the giver's hand-object states in the pre-handover phase. Besides, we also report the hand and object pose errors with existing baselines and show that the dataset can serve as the video demonstrations for robot imitation learning on the handover task. Dataset, model and code will be made public.