 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFTrans: Leveraging Refractive Flow of Transparent Objects for Surface Normal Estimation and Manipulation
Nov 21, 2023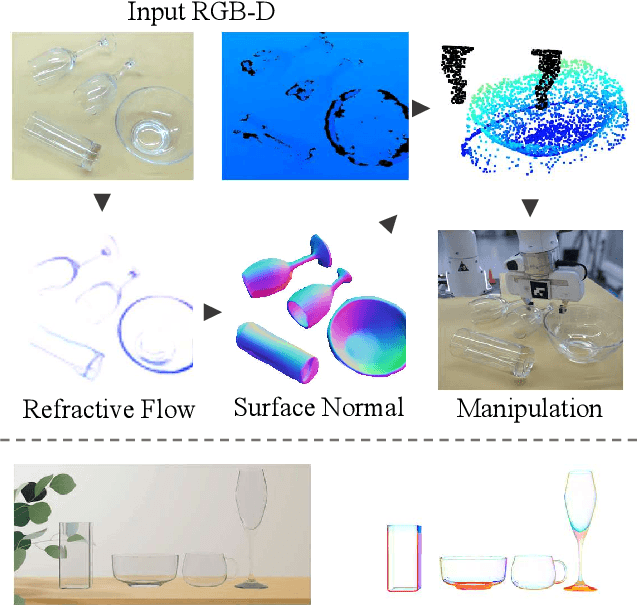
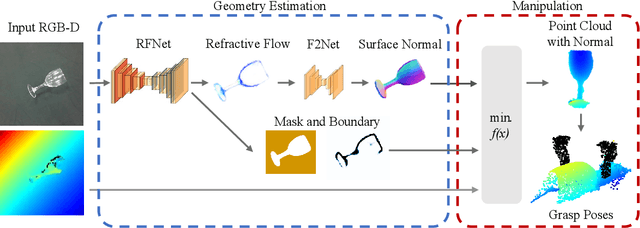
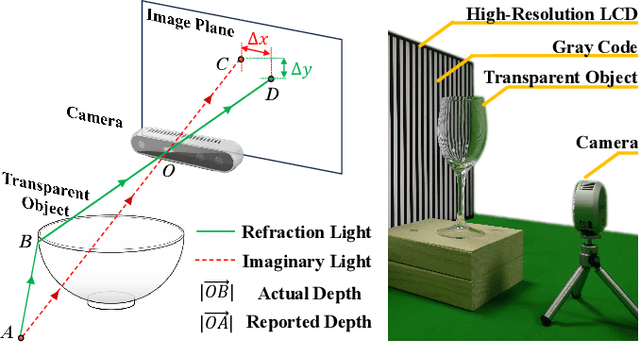

Transparent objects are widely used in our daily lives, making it important to teach robots to interact with them. However, it's not easy because the reflective and refractive effects can make RGB-D cameras fail to give accurate geometry measurements. To solve this problem, this paper introduces RFTrans, an RGB-D-based method for surface normal estimation and manipulation of transparent objects. By leveraging refractive flow as an intermediate representation, RFTrans circumvents the drawbacks of directly predicting the geometry (e.g. surface normal) from RGB images and helps bridge the sim-to-real gap. RFTrans integrates the RFNet, which predicts refractive flow, object mask, and boundaries, followed by the F2Net, which estimates surface normal from the refractive flow. To make manipulation possible, a global optimization module will take in the predictions, refine the raw depth, and construct the point cloud with normal. An analytical grasp planning algorithm, ISF, is followed to generate the grasp poses. We build a synthetic dataset with physically plausible ray-tracing rendering techniques to train the networks. Results show that the RFTrans trained on the synthetic dataset can consistently outperform the baseline ClearGrasp in both synthetic and real-world benchmarks by a large margin. Finally, a real-world robot grasping task witnesses an 83% success rate, proving that refractive flow can help enable direct sim-to-real transfer. The code, data, and supplementary materials are available at https://rftrans.robotflow.ai.
RCareWorld: A Human-centric Simulation World for Caregiving Robots
Oct 19, 2022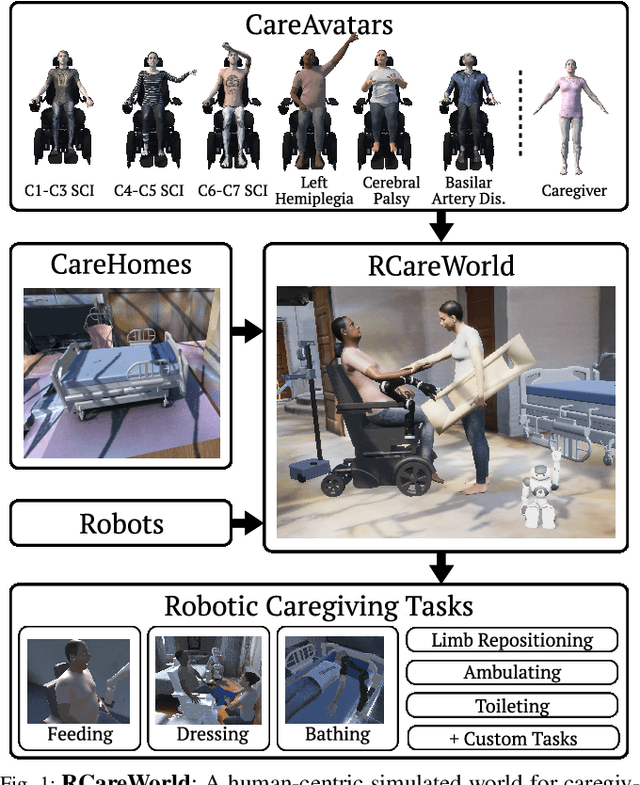
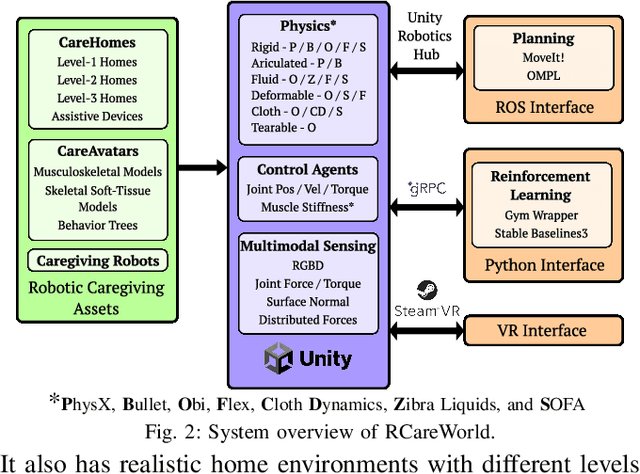
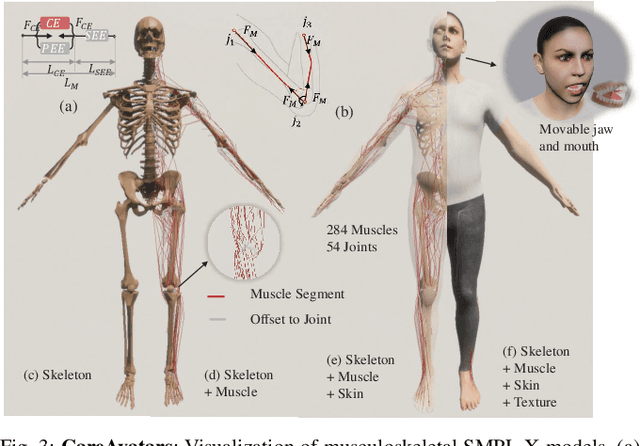
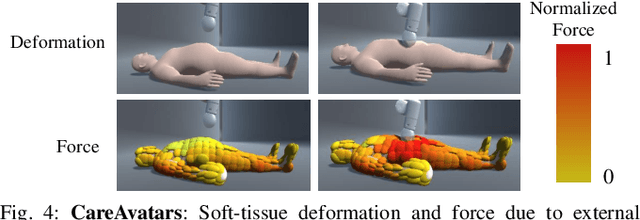
We present RCareWorld, a human-centric simulation world for physical and social robotic caregiving designed with inputs from stakeholders, including care recipients, caregivers, occupational therapists, and roboticists. RCareWorld has realistic human models of care recipients with mobility limitations and caregivers, home environments with multiple levels of accessibility and assistive devices, and robots commonly used for caregiving. It interfaces with various physics engines to model diverse material types necessary for simulating caregiving scenarios, and provides the capability to plan, control, and learn both human and robot control policies by integrating with state-of-the-art external planning and learning libraries, and VR devices. We propose a set of realistic caregiving tasks in RCareWorld as a benchmark for physical robotic caregiving and provide baseline control policies for them. We illustrate the high-fidelity simulation capabilities of RCareWorld by demonstrating the execution of a policy learnt in simulation for one of these tasks on a real-world setup. Additionally, we perform a real-world social robotic caregiving experiment using behaviors modeled in RCareWorld. Robotic caregiving, though potentially impactful towards enhancing the quality of life of care recipients and caregivers, is a field with many barriers to entry due to its interdisciplinary facets. RCareWorld takes the first step towards building a realistic simulation world for robotic caregiving that would enable researchers worldwide to contribute to this impactful field. Demo videos and supplementary materials can be found at: https://emprise.cs.cornell.edu/rcareworld/.
AKB-48: A Real-World Articulated Object Knowledge Base
Feb 17, 2022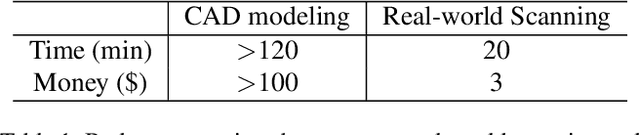
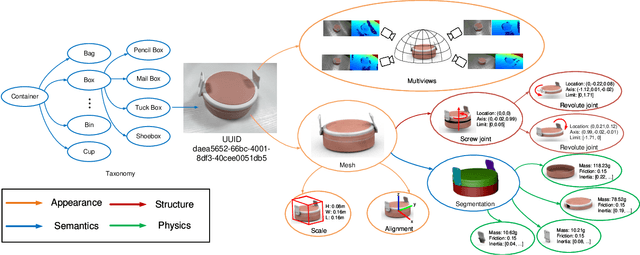
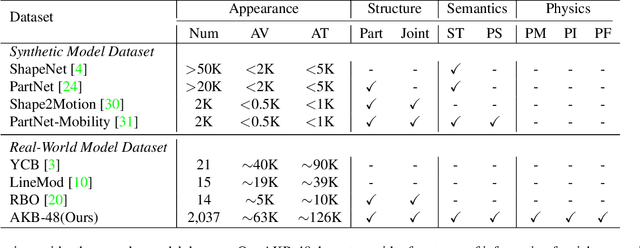

Human life is populated with articulated objects. A comprehensive understanding of articulated objects, namely appearance, structure, physics property, and semantics, will benefit many research communities. As current articulated object understanding solutions are usually based on synthetic object dataset with CAD models without physics properties, which prevent satisfied generalization from simulation to real-world applications in visual and robotics tasks. To bridge the gap, we present AKB-48: a large-scale Articulated object Knowledge Base which consists of 2,037 real-world 3D articulated object models of 48 categories. Each object is described by a knowledge graph ArtiKG. To build the AKB-48, we present a fast articulation knowledge modeling (FArM) pipeline, which can fulfill the ArtiKG for an articulated object within 10-15 minutes, and largely reduce the cost for object modeling in the real world. Using our dataset, we propose AKBNet, a novel integral pipeline for Category-level Visual Articulation Manipulation (C-VAM) task, in which we benchmark three sub-tasks, namely pose estimation, object reconstruction and manipulation. Dataset, codes, and models will be publicly available at https://liuliu66.github.io/articulationobjects/.
RFUniverse: A Physics-based Action-centric Interactive Environment for Everyday Household Tasks
Feb 01, 2022Household environments are important testbeds for embodied AI research. Many simulation environments have been proposed to develop learning models for solving everyday household tasks. However, though interactions are paid attention to in most environments, the actions operating on the objects are not well supported concerning action types, object types, and interaction physics. To bridge the gap at the action level, we propose a novel physics-based action-centric environment, RFUniverse, for robot learning of everyday household tasks. RFUniverse supports interactions among 87 atomic actions and 8 basic object types in a visually and physically plausible way. To demonstrate the usability of the simulation environment, we perform learning algorithms on various types of tasks, namely fruit-picking, cloth-folding and sponge-wiping for manipulation, stair-chasing for locomotion, room-cleaning for multi-agent collaboration, milk-pouring for task and motion planning, and bimanual-lifting for behavior cloning from VR interface. Client-side Python APIs, learning codes, models, and the database will be released. Demo video for atomic actions can be found in supplementary materials: \url{https://sites.google.com/view/rfuniverse}
OMAD: Object Model with Articulated Deformations for Pose Estimation and Retrieval
Dec 14, 2021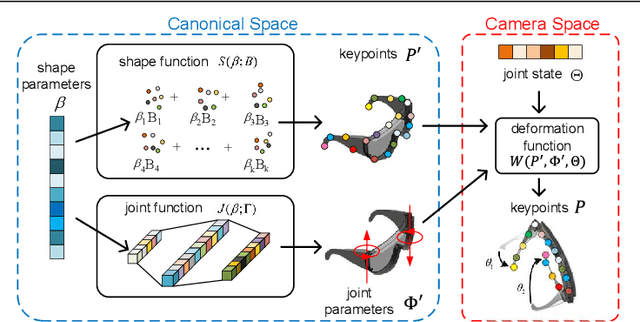
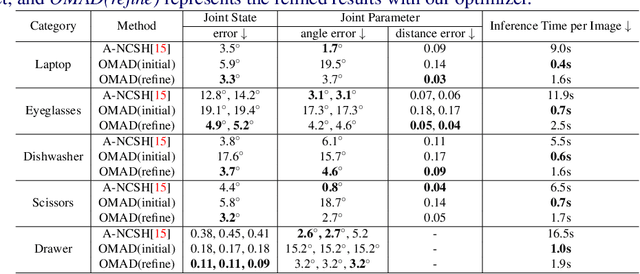

Articulated objects are pervasive in daily life. However, due to the intrinsic high-DoF structure, the joint states of the articulated objects are hard to be estimated. To model articulated objects, two kinds of shape deformations namely the geometric and the pose deformation should be considered. In this work, we present a novel category-specific parametric representation called Object Model with Articulated Deformations (OMAD) to explicitly model the articulated objects. In OMAD, a category is associated with a linear shape function with shared shape basis and a non-linear joint function. Both functions can be learned from a large-scale object model dataset and fixed as category-specific priors. Then we propose an OMADNet to predict the shape parameters and the joint states from an object's single observation. With the full representation of the object shape and joint states, we can address several tasks including category-level object pose estimation and the articulated object retrieval. To evaluate these tasks, we create a synthetic dataset based on PartNet-Mobility. Extensive experiments show that our simple OMADNet can serve as a strong baseline for both tasks.
Towards Real-World Category-level Articulation Pose Estimation
May 07, 2021
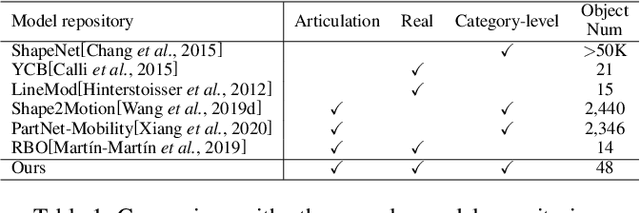
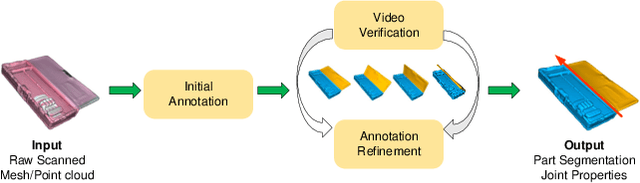

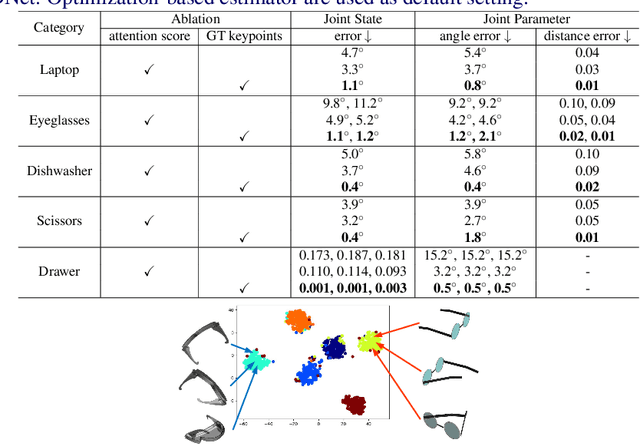
Human life is populated with articulated objects. Current Category-level Articulation Pose Estimation (CAPE) methods are studied under the single-instance setting with a fixed kinematic structure for each category. Considering these limitations, we reform this problem setting for real-world environments and suggest a CAPE-Real (CAPER) task setting. This setting allows varied kinematic structures within a semantic category, and multiple instances to co-exist in an observation of real world. To support this task, we build an articulated model repository ReArt-48 and present an efficient dataset generation pipeline, which contains Fast Articulated Object Modeling (FAOM) and Semi-Authentic MixEd Reality Technique (SAMERT). Accompanying the pipeline, we build a large-scale mixed reality dataset ReArtMix and a real world dataset ReArtVal. We also propose an effective framework ReArtNOCS that exploits RGB-D input to estimate part-level pose for multiple instances in a single forward pass. Extensive experiments demonstrate that the proposed ReArtNOCS can achieve good performance on both CAPER and CAPE settings. We believe it could serve as a strong baseline for future research on the CAPER task.