 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRH20T-P: A Primitive-Level Robotic Dataset Towards Composable Generalization Agents
Mar 28, 2024



The ultimate goals of robotic learning is to acquire a comprehensive and generalizable robotic system capable of performing both seen skills within the training distribution and unseen skills in novel environments. Recent progress in utilizing language models as high-level planners has demonstrated that the complexity of tasks can be reduced through decomposing them into primitive-level plans, making it possible to generalize on novel robotic tasks in a composable manner. Despite the promising future, the community is not yet adequately prepared for composable generalization agents, particularly due to the lack of primitive-level real-world robotic datasets. In this paper, we propose a primitive-level robotic dataset, namely RH20T-P, which contains about 33000 video clips covering 44 diverse and complicated robotic tasks. Each clip is manually annotated according to a set of meticulously designed primitive skills, facilitating the future development of composable generalization agents. To validate the effectiveness of RH20T-P, we also construct a potential and scalable agent based on RH20T-P, called RA-P. Equipped with two planners specialized in task decomposition and motion planning, RA-P can adapt to novel physical skills through composable generalization. Our website and videos can be found at https://sites.google.com/view/rh20t-primitive/main. Dataset and code will be made available soon.
AKB-48: A Real-World Articulated Object Knowledge Base
Feb 17, 2022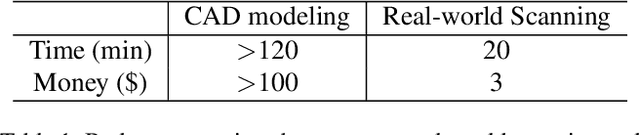
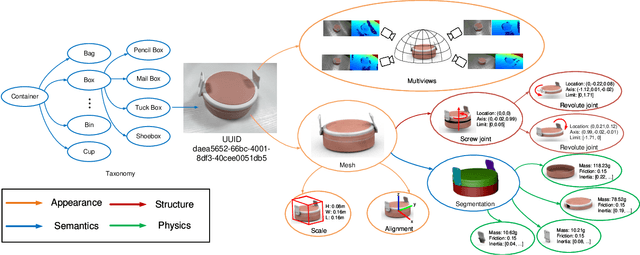
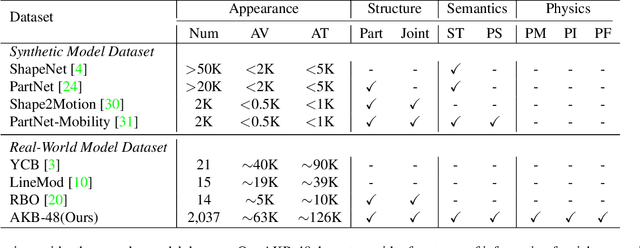

Human life is populated with articulated objects. A comprehensive understanding of articulated objects, namely appearance, structure, physics property, and semantics, will benefit many research communities. As current articulated object understanding solutions are usually based on synthetic object dataset with CAD models without physics properties, which prevent satisfied generalization from simulation to real-world applications in visual and robotics tasks. To bridge the gap, we present AKB-48: a large-scale Articulated object Knowledge Base which consists of 2,037 real-world 3D articulated object models of 48 categories. Each object is described by a knowledge graph ArtiKG. To build the AKB-48, we present a fast articulation knowledge modeling (FArM) pipeline, which can fulfill the ArtiKG for an articulated object within 10-15 minutes, and largely reduce the cost for object modeling in the real world. Using our dataset, we propose AKBNet, a novel integral pipeline for Category-level Visual Articulation Manipulation (C-VAM) task, in which we benchmark three sub-tasks, namely pose estimation, object reconstruction and manipulation. Dataset, codes, and models will be publicly available at https://liuliu66.github.io/articulationobjects/.
iSeg3D: An Interactive 3D Shape Segmentation Tool
Dec 24, 2021
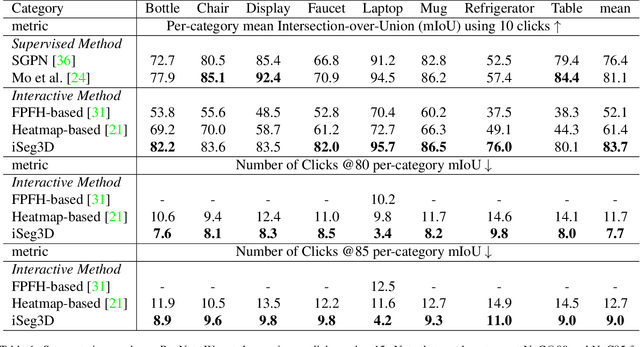
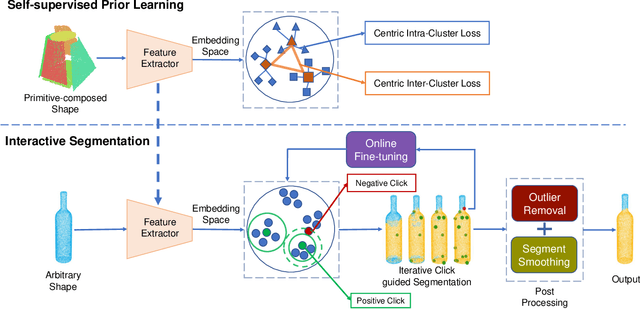
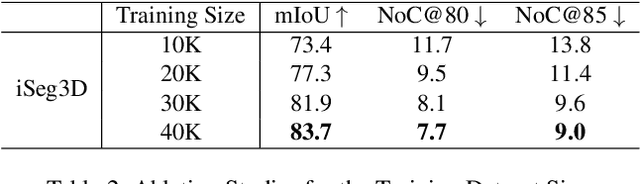
A large-scale dataset is essential for learning good features in 3D shape understanding, but there are only a few datasets that can satisfy deep learning training. One of the major reasons is that current tools for annotating per-point semantic labels using polygons or scribbles are tedious and inefficient. To facilitate segmentation annotations in 3D shapes, we propose an effective annotation tool, named iSeg for 3D shape. It can obtain a satisfied segmentation result with minimal human clicks (< 10). Under our observation, most objects can be considered as the composition of finite primitive shapes, and we train iSeg3D model on our built primitive-composed shape data to learn the geometric prior knowledge in a self-supervised manner. Given human interactions, the learned knowledge can be used to segment parts on arbitrary shapes, in which positive clicks help associate the primitives into the semantic parts and negative clicks can avoid over-segmentation. Besides, We also provide an online human-in-loop fine-tuning module that enables the model perform better segmentation with less clicks. Experiments demonstrate the effectiveness of iSeg3D on PartNet shape segmentation. Data and codes will be made publicly available.
HandTailor: Towards High-Precision Monocular 3D Hand Recovery
Feb 18, 2021
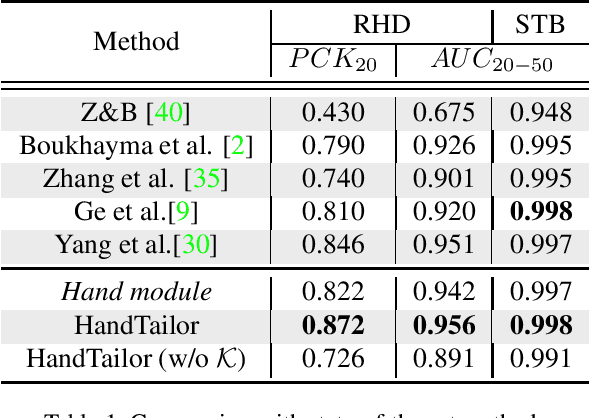
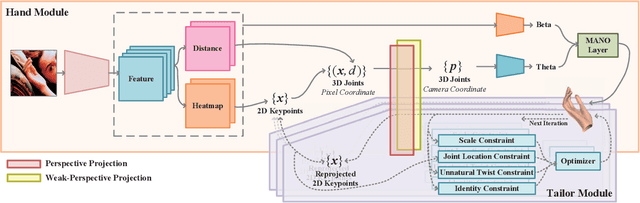
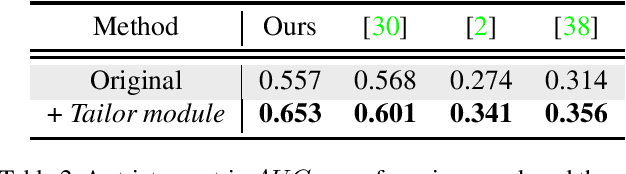
3D hand pose estimation and shape recovery are challenging tasks in computer vision. We introduce a novel framework HandTailor, which combines a learning-based hand module and an optimization-based tailor module to achieve high-precision hand mesh recovery from a monocular RGB image. The proposed hand module unifies perspective projection and weak perspective projection in a single network towards accuracy-oriented and in-the-wild scenarios. The proposed tailor module then utilizes the coarsely reconstructed mesh model provided by the hand module as initialization, and iteratively optimizes an energy function to obtain better results. The tailor module is time-efficient, costs only 8ms per frame on a modern CPU. We demonstrate that HandTailor can get state-of-the-art performance on several public benchmarks, with impressive qualitative results on in-the-wild experiments.