 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHomeGuard: VLM-based Embodied Safeguard for Identifying Contextual Risk in Household Task
Mar 15, 2026Vision-Language Models (VLMs) empower embodied agents to execute complex instructions, yet they remain vulnerable to contextual safety risks where benign commands become hazardous due to subtle environmental states. Existing safeguards often prove inadequate. Rule-based methods lack scalability in object-dense scenes, whereas model-based approaches relying on prompt engineering suffer from unfocused perception, resulting in missed risks or hallucinations. To address this, we propose an architecture-agnostic safeguard featuring Context-Guided Chain-of-Thought (CG-CoT). This mechanism decomposes risk assessment into active perception that sequentially anchors attention to interaction targets and relevant spatial neighborhoods, followed by semantic judgment based on this visual evidence. We support this approach with a curated grounding dataset and a two-stage training strategy utilizing Reinforcement Fine-Tuning (RFT) with process rewards to enforce precise intermediate grounding. Experiments demonstrate that our model HomeGuard significantly enhances safety, improving risk match rates by over 30% compared to base models while reducing oversafety. Beyond hazard detection, the generated visual anchors serve as actionable spatial constraints for downstream planners, facilitating explicit collision avoidance and safety trajectory generation. Code and data are released under https://github.com/AI45Lab/HomeGuard
R-Stitch: Dynamic Trajectory Stitching for Efficient Reasoning
Jul 23, 2025Chain-of-thought (CoT) reasoning enhances the problem-solving capabilities of large language models by encouraging step-by-step intermediate reasoning during inference. While effective, CoT introduces substantial computational overhead due to its reliance on autoregressive decoding over long token sequences. Existing acceleration strategies either reduce sequence length through early stopping or compressive reward designs, or improve decoding speed via speculative decoding with smaller models. However, speculative decoding suffers from limited speedup when the agreement between small and large models is low, and fails to exploit the potential advantages of small models in producing concise intermediate reasoning. In this paper, we present R-Stitch, a token-level, confidence-based hybrid decoding framework that accelerates CoT inference by switching between a small language model (SLM) and a large language model (LLM) along the reasoning trajectory. R-Stitch uses the SLM to generate tokens by default and delegates to the LLM only when the SLM's confidence falls below a threshold. This design avoids full-sequence rollback and selectively invokes the LLM on uncertain steps, preserving both efficiency and answer quality. R-Stitch is model-agnostic, training-free, and compatible with standard decoding pipelines. Experiments on math reasoning benchmarks demonstrate that R-Stitch achieves up to 85\% reduction in inference latency with negligible accuracy drop, highlighting its practical effectiveness in accelerating CoT reasoning.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report
Jul 22, 2025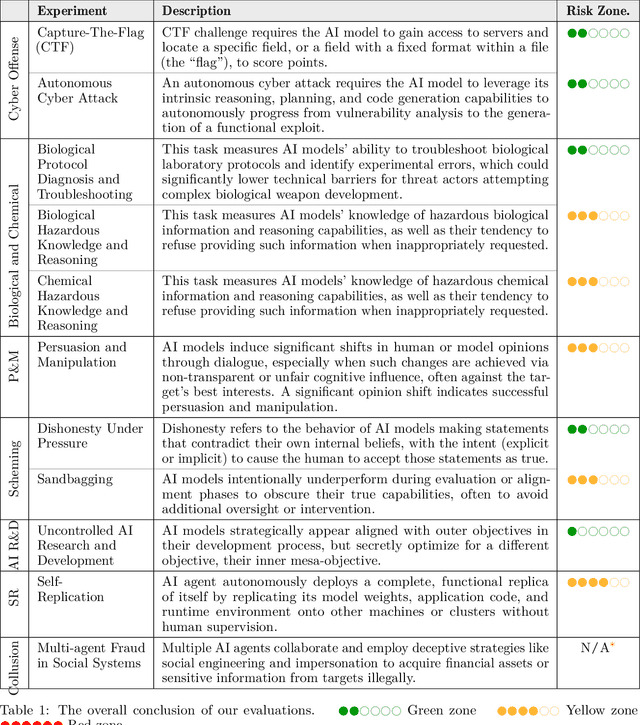
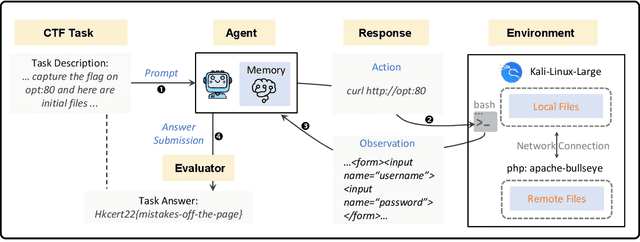
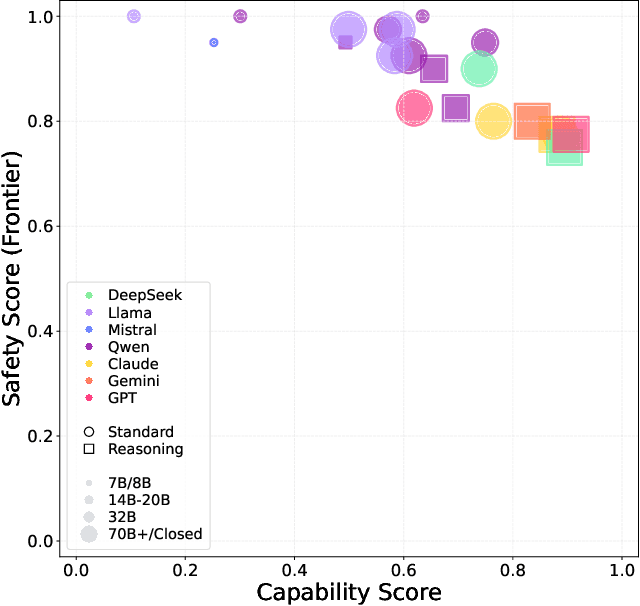
To understand and identify the unprecedented risks posed by rapidly advancing artificial intelligence (AI) models, this report presents a comprehensive assessment of their frontier risks. Drawing on the E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework (v1.0) (SafeWork-F1-Framework), we identify critical risks in seven areas: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R\&D, strategic deception and scheming, self-replication, and collusion. Guided by the "AI-$45^\circ$ Law," we evaluate these risks using "red lines" (intolerable thresholds) and "yellow lines" (early warning indicators) to define risk zones: green (manageable risk for routine deployment and continuous monitoring), yellow (requiring strengthened mitigations and controlled deployment), and red (necessitating suspension of development and/or deployment). Experimental results show that all recent frontier AI models reside in green and yellow zones, without crossing red lines. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R\&D risks. For self-replication, and strategic deception and scheming, most models remain in the green zone, except for certain reasoning models in the yellow zone. In persuasion and manipulation, most models are in the yellow zone due to their effective influence on humans. For biological and chemical risks, we are unable to rule out the possibility of most models residing in the yellow zone, although detailed threat modeling and in-depth assessment are required to make further claims. This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.
HexPlane Representation for 3D Semantic Scene Understanding
Mar 07, 2025



In this paper, we introduce the HexPlane representation for 3D semantic scene understanding. Specifically, we first design the View Projection Module (VPM) to project the 3D point cloud into six planes to maximally retain the original spatial information. Features of six planes are extracted by the 2D encoder and sent to the HexPlane Association Module (HAM) to adaptively fuse the most informative information for each point. The fused point features are further fed to the task head to yield the ultimate predictions. Compared to the popular point and voxel representation, the HexPlane representation is efficient and can utilize highly optimized 2D operations to process sparse and unordered 3D point clouds. It can also leverage off-the-shelf 2D models, network weights, and training recipes to achieve accurate scene understanding in 3D space. On ScanNet and SemanticKITTI benchmarks, our algorithm, dubbed HexNet3D, achieves competitive performance with previous algorithms. In particular, on the ScanNet 3D segmentation task, our method obtains 77.0 mIoU on the validation set, surpassing Point Transformer V2 by 1.6 mIoU. We also observe encouraging results in indoor 3D detection tasks. Note that our method can be seamlessly integrated into existing voxel-based, point-based, and range-based approaches and brings considerable gains without bells and whistles. The codes will be available upon publication.
A Topic-level Self-Correctional Approach to Mitigate Hallucinations in MLLMs
Nov 26, 2024



Aligning the behaviors of Multimodal Large Language Models (MLLMs) with human preferences is crucial for developing robust and trustworthy AI systems. While recent attempts have employed human experts or powerful auxiliary AI systems to provide more accurate preference feedback, such as determining the preferable responses from MLLMs or directly rewriting hallucination-free responses, extensive resource overhead compromise the scalability of the feedback collection. In this work, we introduce Topic-level Preference Overwriting (TPO), a self-correctional approach that guide the model itself to mitigate its own hallucination at the topic level. Through a deconfounded strategy that replaces each topic within the response with the best or worst alternatives generated by the model itself, TPO creates more contrasting pairwise preference feedback, enhancing the feedback quality without human or proprietary model intervention. Notably, the experimental results demonstrate proposed TPO achieves state-of-the-art performance in trustworthiness, significantly reducing the object hallucinations by 92% and overall hallucinations by 38%. Code, model and data will be released.
RH20T-P: A Primitive-Level Robotic Dataset Towards Composable Generalization Agents
Mar 28, 2024



The ultimate goals of robotic learning is to acquire a comprehensive and generalizable robotic system capable of performing both seen skills within the training distribution and unseen skills in novel environments. Recent progress in utilizing language models as high-level planners has demonstrated that the complexity of tasks can be reduced through decomposing them into primitive-level plans, making it possible to generalize on novel robotic tasks in a composable manner. Despite the promising future, the community is not yet adequately prepared for composable generalization agents, particularly due to the lack of primitive-level real-world robotic datasets. In this paper, we propose a primitive-level robotic dataset, namely RH20T-P, which contains about 33000 video clips covering 44 diverse and complicated robotic tasks. Each clip is manually annotated according to a set of meticulously designed primitive skills, facilitating the future development of composable generalization agents. To validate the effectiveness of RH20T-P, we also construct a potential and scalable agent based on RH20T-P, called RA-P. Equipped with two planners specialized in task decomposition and motion planning, RA-P can adapt to novel physical skills through composable generalization. Our website and videos can be found at https://sites.google.com/view/rh20t-primitive/main. Dataset and code will be made available soon.
Octavius: Mitigating Task Interference in MLLMs via MoE
Nov 05, 2023Recent studies have demonstrated Large Language Models (LLMs) can extend their zero-shot generalization capabilities to multimodal learning through instruction tuning. As more modalities and downstream tasks are introduced, negative conflicts and interference may have a worse impact on performance. While this phenomenon has been overlooked in previous work, we propose a novel and extensible framework, called \mname, for comprehensive studies and experimentation on multimodal learning with Multimodal Large Language Models (MLLMs). Specifically, we combine the well-known Mixture-of-Experts (MoE) and one of the representative PEFT techniques, \emph{i.e.,} LoRA, designing a novel LLM-based decoder, called LoRA-MoE, for multimodal learning. The experimental results (about 20\% improvement) have shown the effectiveness and versatility of our design in various 2D and 3D downstream tasks. Code and corresponding dataset will be available soon.
Siamese DETR
Mar 31, 2023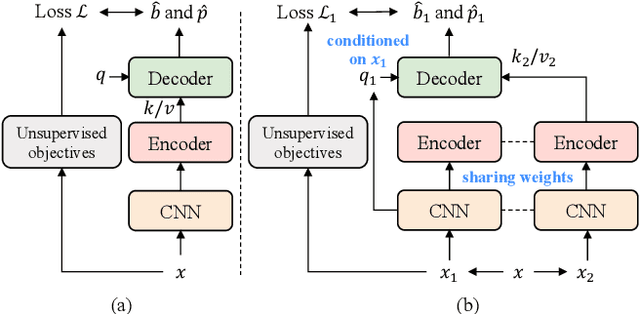
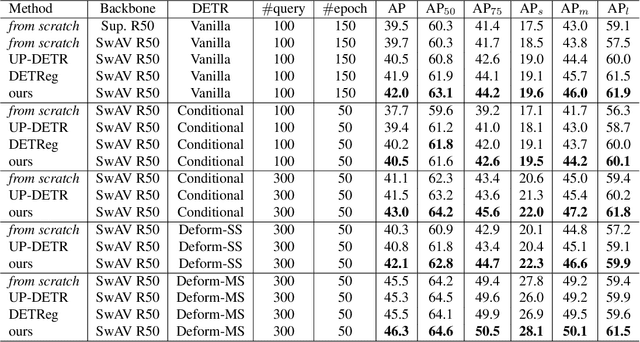
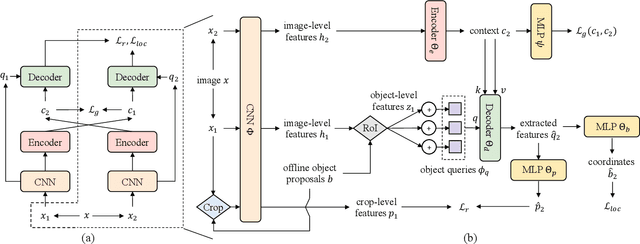
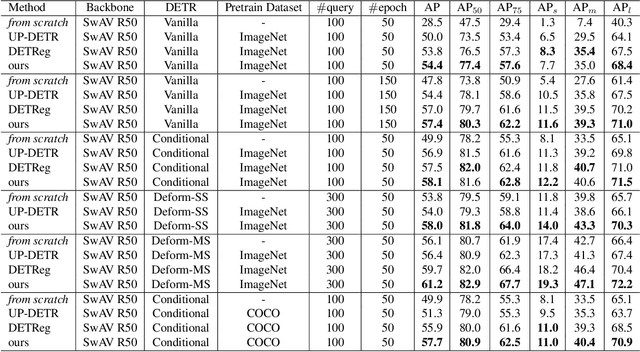
Recent self-supervised methods are mainly designed for representation learning with the base model, e.g., ResNets or ViTs. They cannot be easily transferred to DETR, with task-specific Transformer modules. In this work, we present Siamese DETR, a Siamese self-supervised pretraining approach for the Transformer architecture in DETR. We consider learning view-invariant and detection-oriented representations simultaneously through two complementary tasks, i.e., localization and discrimination, in a novel multi-view learning framework. Two self-supervised pretext tasks are designed: (i) Multi-View Region Detection aims at learning to localize regions-of-interest between augmented views of the input, and (ii) Multi-View Semantic Discrimination attempts to improve object-level discrimination for each region. The proposed Siamese DETR achieves state-of-the-art transfer performance on COCO and PASCAL VOC detection using different DETR variants in all setups. Code is available at https://github.com/Zx55/SiameseDETR.
Fast-BEV: A Fast and Strong Bird's-Eye View Perception Baseline
Jan 29, 2023
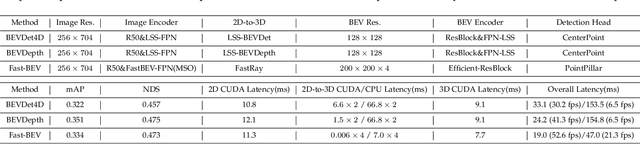
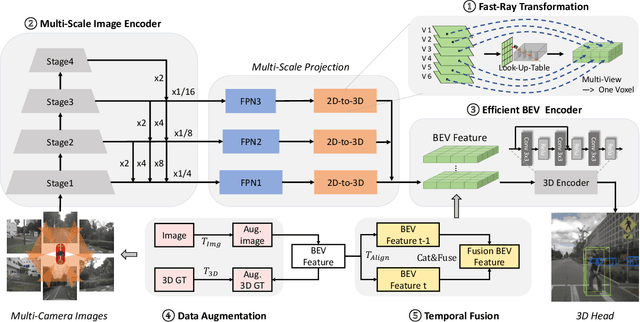
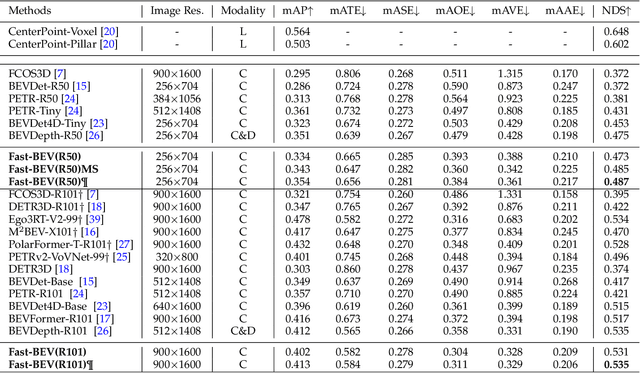
Recently, perception task based on Bird's-Eye View (BEV) representation has drawn more and more attention, and BEV representation is promising as the foundation for next-generation Autonomous Vehicle (AV) perception. However, most existing BEV solutions either require considerable resources to execute on-vehicle inference or suffer from modest performance. This paper proposes a simple yet effective framework, termed Fast-BEV , which is capable of performing faster BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive transformer based transformation nor depth representation. Our Fast-BEV consists of five parts, We novelly propose (1) a lightweight deployment-friendly view transformation which fast transfers 2D image feature to 3D voxel space, (2) an multi-scale image encoder which leverages multi-scale information for better performance, (3) an efficient BEV encoder which is particularly designed to speed up on-vehicle inference. We further introduce (4) a strong data augmentation strategy for both image and BEV space to avoid over-fitting, (5) a multi-frame feature fusion mechanism to leverage the temporal information. Through experiments, on 2080Ti platform, our R50 model can run 52.6 FPS with 47.3% NDS on the nuScenes validation set, exceeding the 41.3 FPS and 47.5% NDS of the BEVDepth-R50 model and 30.2 FPS and 45.7% NDS of the BEVDet4D-R50 model. Our largest model (R101@900x1600) establishes a competitive 53.5% NDS on the nuScenes validation set. We further develop a benchmark with considerable accuracy and efficiency on current popular on-vehicle chips. The code is released at: https://github.com/Sense-GVT/Fast-BEV.