 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese DETR
Mar 31, 2023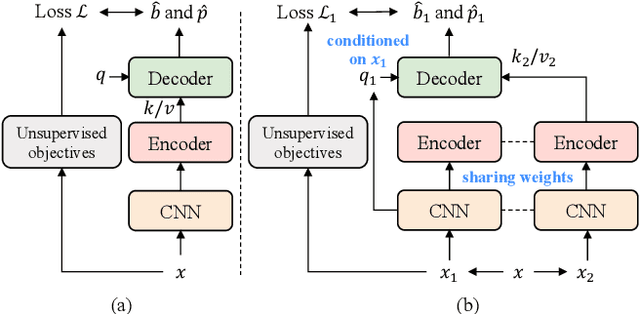
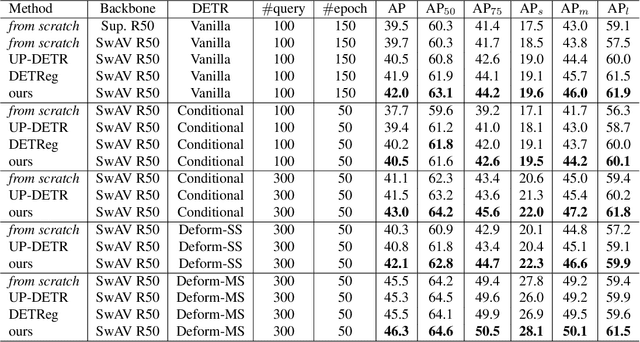
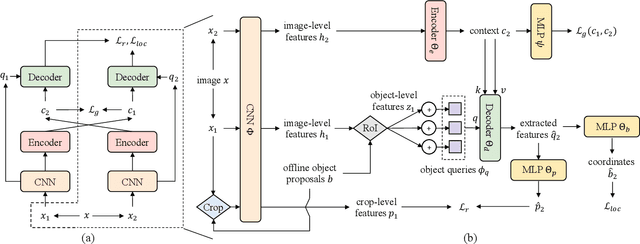
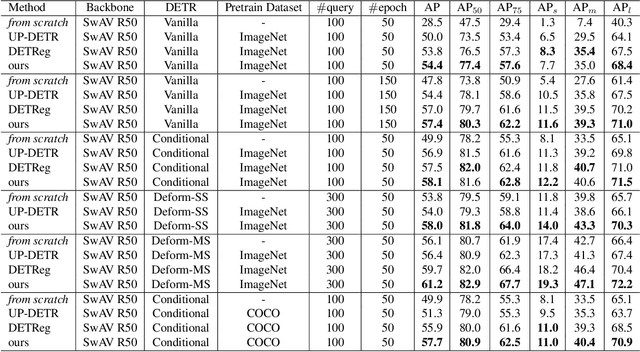
Recent self-supervised methods are mainly designed for representation learning with the base model, e.g., ResNets or ViTs. They cannot be easily transferred to DETR, with task-specific Transformer modules. In this work, we present Siamese DETR, a Siamese self-supervised pretraining approach for the Transformer architecture in DETR. We consider learning view-invariant and detection-oriented representations simultaneously through two complementary tasks, i.e., localization and discrimination, in a novel multi-view learning framework. Two self-supervised pretext tasks are designed: (i) Multi-View Region Detection aims at learning to localize regions-of-interest between augmented views of the input, and (ii) Multi-View Semantic Discrimination attempts to improve object-level discrimination for each region. The proposed Siamese DETR achieves state-of-the-art transfer performance on COCO and PASCAL VOC detection using different DETR variants in all setups. Code is available at https://github.com/Zx55/SiameseDETR.
X-Learner: Learning Cross Sources and Tasks for Universal Visual Representation
Mar 16, 2022
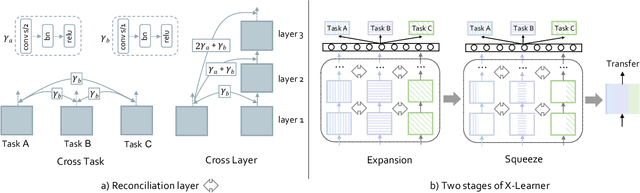
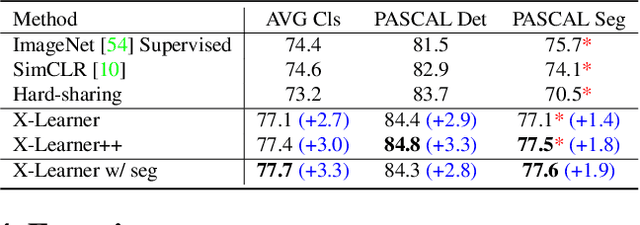
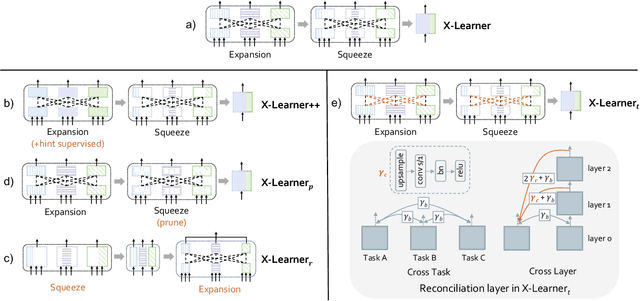
In computer vision, pre-training models based on largescale supervised learning have been proven effective over the past few years. However, existing works mostly focus on learning from individual task with single data source (e.g., ImageNet for classification or COCO for detection). This restricted form limits their generalizability and usability due to the lack of vast semantic information from various tasks and data sources. Here, we demonstrate that jointly learning from heterogeneous tasks and multiple data sources contributes to universal visual representation, leading to better transferring results of various downstream tasks. Thus, learning how to bridge the gaps among different tasks and data sources is the key, but it still remains an open question. In this work, we propose a representation learning framework called X-Learner, which learns the universal feature of multiple vision tasks supervised by various sources, with expansion and squeeze stage: 1) Expansion Stage: X-Learner learns the task-specific feature to alleviate task interference and enrich the representation by reconciliation layer. 2) Squeeze Stage: X-Learner condenses the model to a reasonable size and learns the universal and generalizable representation for various tasks transferring. Extensive experiments demonstrate that X-Learner achieves strong performance on different tasks without extra annotations, modalities and computational costs compared to existing representation learning methods. Notably, a single X-Learner model shows remarkable gains of 3.0%, 3.3% and 1.8% over current pretrained models on 12 downstream datasets for classification, object detection and semantic segmentation.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021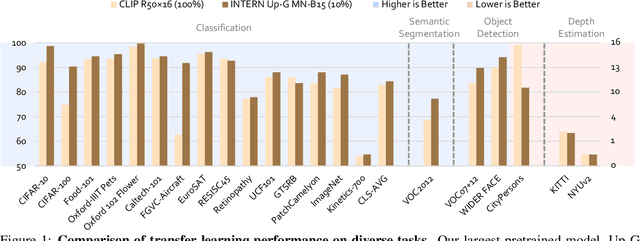
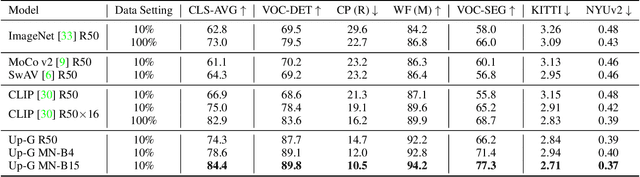
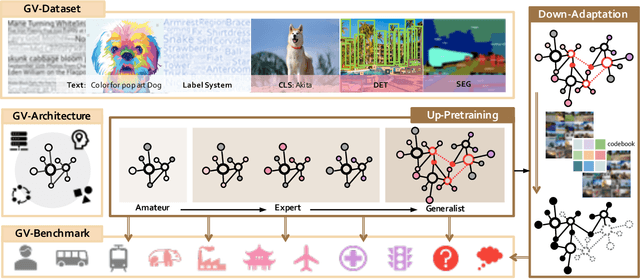
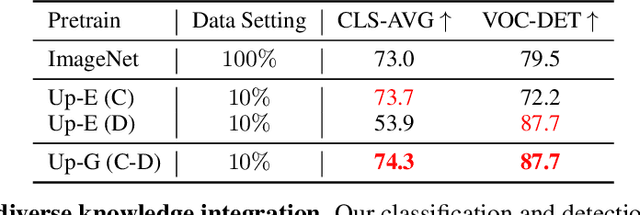
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.