 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINTERN: A New Learning Paradigm Towards General Vision
Paper and Code
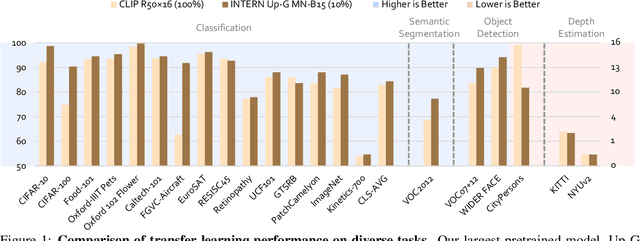
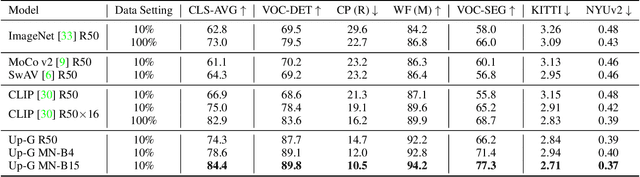
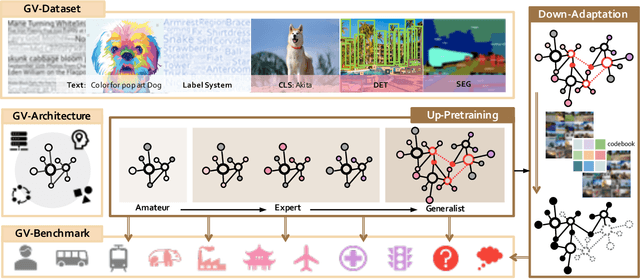
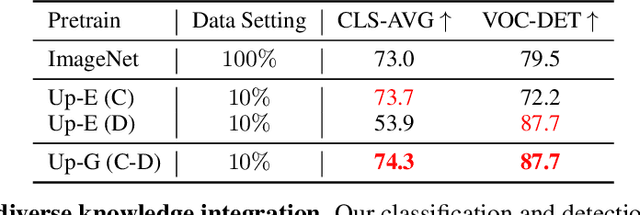
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.