 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniG3D: A Unified 3D Object Generation Dataset
Jun 19, 2023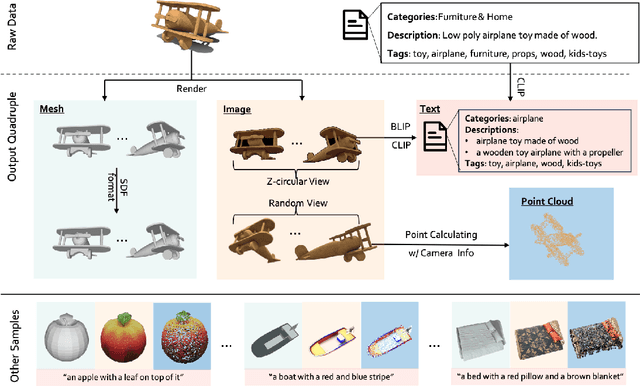
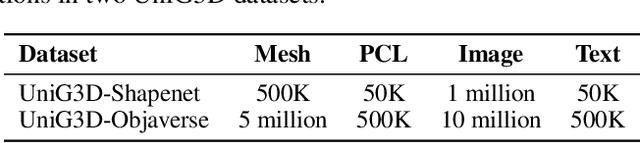
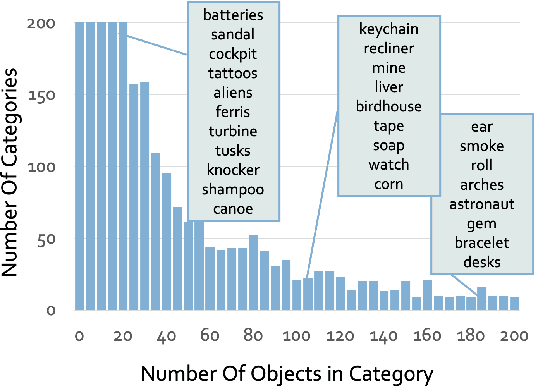
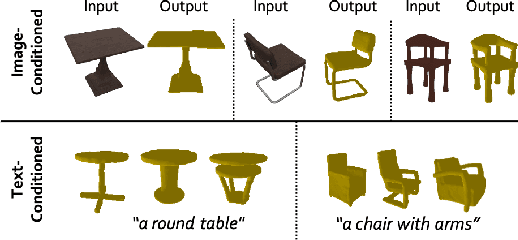
The field of generative AI has a transformative impact on various areas, including virtual reality, autonomous driving, the metaverse, gaming, and robotics. Among these applications, 3D object generation techniques are of utmost importance. This technique has unlocked fresh avenues in the realm of creating, customizing, and exploring 3D objects. However, the quality and diversity of existing 3D object generation methods are constrained by the inadequacies of existing 3D object datasets, including issues related to text quality, the incompleteness of multi-modal data representation encompassing 2D rendered images and 3D assets, as well as the size of the dataset. In order to resolve these issues, we present UniG3D, a unified 3D object generation dataset constructed by employing a universal data transformation pipeline on Objaverse and ShapeNet datasets. This pipeline converts each raw 3D model into comprehensive multi-modal data representation <text, image, point cloud, mesh> by employing rendering engines and multi-modal models. These modules ensure the richness of textual information and the comprehensiveness of data representation. Remarkably, the universality of our pipeline refers to its ability to be applied to any 3D dataset, as it only requires raw 3D data. The selection of data sources for our dataset is based on their scale and quality. Subsequently, we assess the effectiveness of our dataset by employing Point-E and SDFusion, two widely recognized methods for object generation, tailored to the prevalent 3D representations of point clouds and signed distance functions. Our dataset is available at: https://unig3d.github.io.
Mask Hierarchical Features For Self-Supervised Learning
Apr 01, 2023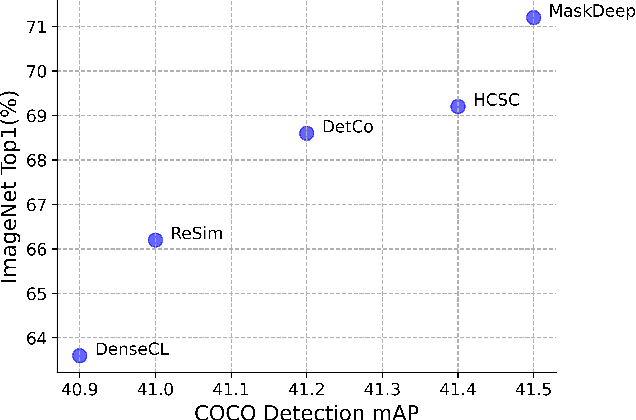
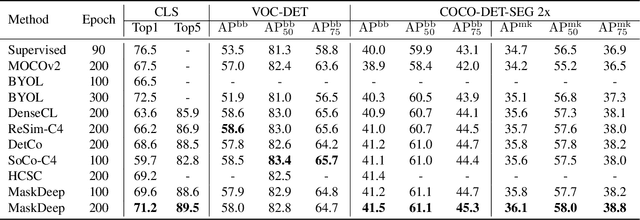
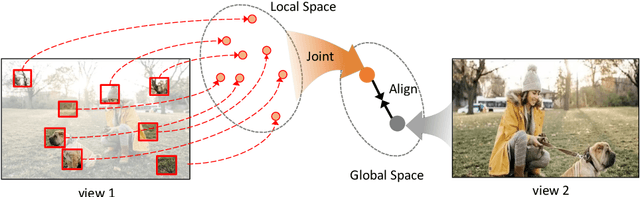
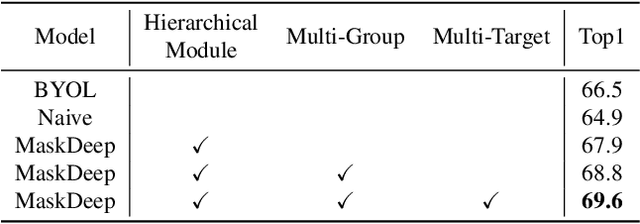
This paper shows that Masking the Deep hierarchical features is an efficient self-supervised method, denoted as MaskDeep. MaskDeep treats each patch in the representation space as an independent instance. We mask part of patches in the representation space and then utilize sparse visible patches to reconstruct high semantic image representation. The intuition of MaskDeep lies in the fact that models can reason from sparse visible patches semantic to the global semantic of the image. We further propose three designs in our framework: 1) a Hierarchical Deep-Masking module to concern the hierarchical property of patch representations, 2) a multi-group strategy to improve the efficiency without any extra computing consumption of the encoder and 3) a multi-target strategy to provide more description of the global semantic. Our MaskDeep brings decent improvements. Trained on ResNet50 with 200 epochs, MaskDeep achieves state-of-the-art results of 71.2% Top1 accuracy linear classification on ImageNet. On COCO object detection tasks, MaskDeep outperforms the self-supervised method SoCo, which specifically designed for object detection. When trained with 100 epochs, MaskDeep achieves 69.6% Top1 accuracy, which surpasses current methods trained with 200 epochs, such as HCSC, by 0.4% .
Fast-BEV: A Fast and Strong Bird's-Eye View Perception Baseline
Jan 29, 2023
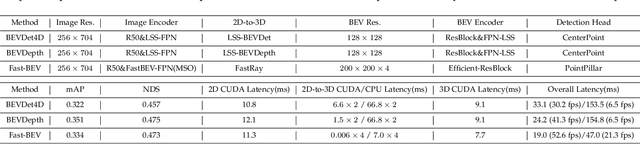
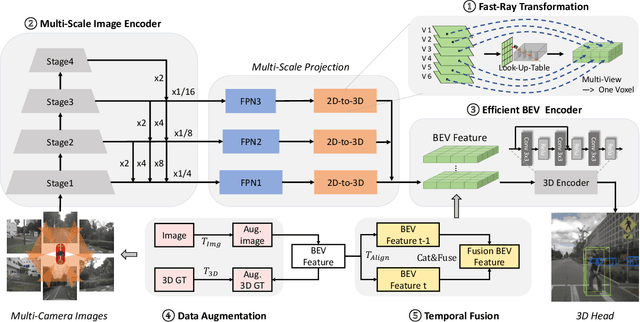
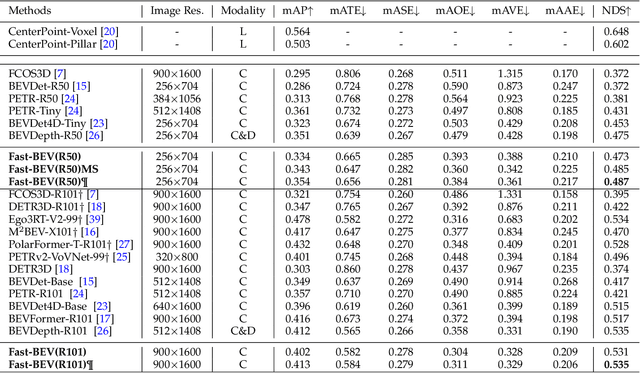
Recently, perception task based on Bird's-Eye View (BEV) representation has drawn more and more attention, and BEV representation is promising as the foundation for next-generation Autonomous Vehicle (AV) perception. However, most existing BEV solutions either require considerable resources to execute on-vehicle inference or suffer from modest performance. This paper proposes a simple yet effective framework, termed Fast-BEV , which is capable of performing faster BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive transformer based transformation nor depth representation. Our Fast-BEV consists of five parts, We novelly propose (1) a lightweight deployment-friendly view transformation which fast transfers 2D image feature to 3D voxel space, (2) an multi-scale image encoder which leverages multi-scale information for better performance, (3) an efficient BEV encoder which is particularly designed to speed up on-vehicle inference. We further introduce (4) a strong data augmentation strategy for both image and BEV space to avoid over-fitting, (5) a multi-frame feature fusion mechanism to leverage the temporal information. Through experiments, on 2080Ti platform, our R50 model can run 52.6 FPS with 47.3% NDS on the nuScenes validation set, exceeding the 41.3 FPS and 47.5% NDS of the BEVDepth-R50 model and 30.2 FPS and 45.7% NDS of the BEVDet4D-R50 model. Our largest model (R101@900x1600) establishes a competitive 53.5% NDS on the nuScenes validation set. We further develop a benchmark with considerable accuracy and efficiency on current popular on-vehicle chips. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
Fast-BEV: Towards Real-time On-vehicle Bird's-Eye View Perception
Jan 19, 2023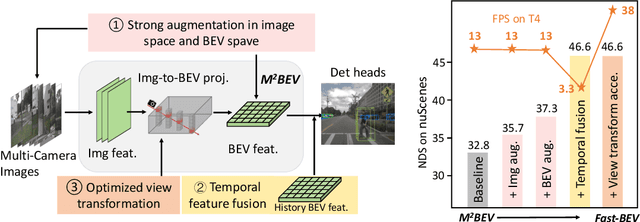
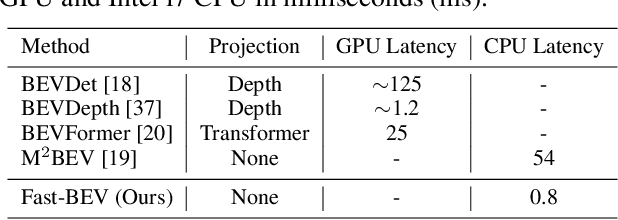
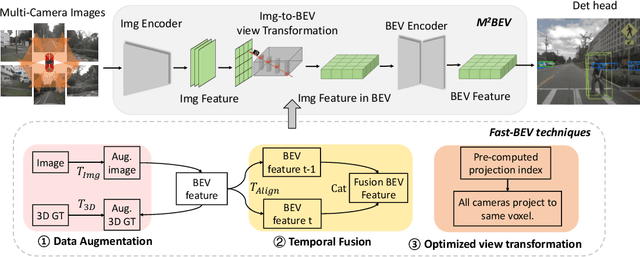
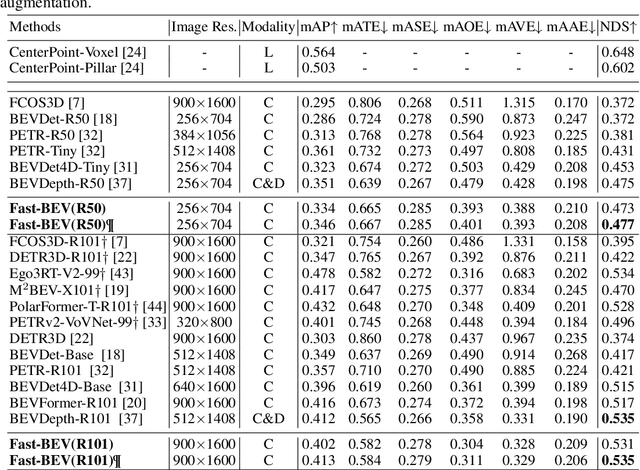
Recently, the pure camera-based Bird's-Eye-View (BEV) perception removes expensive Lidar sensors, making it a feasible solution for economical autonomous driving. However, most existing BEV solutions either suffer from modest performance or require considerable resources to execute on-vehicle inference. This paper proposes a simple yet effective framework, termed Fast-BEV, which is capable of performing real-time BEV perception on the on-vehicle chips. Towards this goal, we first empirically find that the BEV representation can be sufficiently powerful without expensive view transformation or depth representation. Starting from M2BEV baseline, we further introduce (1) a strong data augmentation strategy for both image and BEV space to avoid over-fitting (2) a multi-frame feature fusion mechanism to leverage the temporal information (3) an optimized deployment-friendly view transformation to speed up the inference. Through experiments, we show Fast-BEV model family achieves considerable accuracy and efficiency on edge. In particular, our M1 model (R18@256x704) can run over 50FPS on the Tesla T4 platform, with 47.0% NDS on the nuScenes validation set. Our largest model (R101@900x1600) establishes a new state-of-the-art 53.5% NDS on the nuScenes validation set. The code is released at: https://github.com/Sense-GVT/Fast-BEV.
* Accepted by NeurIPS2022_ML4AD on October 22, 2022
Parallel Reasoning Network for Human-Object Interaction Detection
Jan 09, 2023



Human-Object Interaction (HOI) detection aims to learn how human interacts with surrounding objects. Previous HOI detection frameworks simultaneously detect human, objects and their corresponding interactions by using a predictor. Using only one shared predictor cannot differentiate the attentive field of instance-level prediction and relation-level prediction. To solve this problem, we propose a new transformer-based method named Parallel Reasoning Network(PR-Net), which constructs two independent predictors for instance-level localization and relation-level understanding. The former predictor concentrates on instance-level localization by perceiving instances' extremity regions. The latter broadens the scope of relation region to reach a better relation-level semantic understanding. Extensive experiments and analysis on HICO-DET benchmark exhibit that our PR-Net effectively alleviated this problem. Our PR-Net has achieved competitive results on HICO-DET and V-COCO benchmarks.
Neighbor Regularized Bayesian Optimization for Hyperparameter Optimization
Oct 07, 2022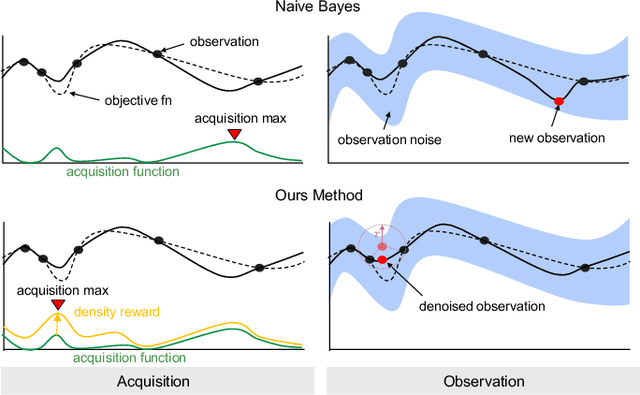



Bayesian Optimization (BO) is a common solution to search optimal hyperparameters based on sample observations of a machine learning model. Existing BO algorithms could converge slowly even collapse when the potential observation noise misdirects the optimization. In this paper, we propose a novel BO algorithm called Neighbor Regularized Bayesian Optimization (NRBO) to solve the problem. We first propose a neighbor-based regularization to smooth each sample observation, which could reduce the observation noise efficiently without any extra training cost. Since the neighbor regularization highly depends on the sample density of a neighbor area, we further design a density-based acquisition function to adjust the acquisition reward and obtain more stable statistics. In addition, we design a adjustment mechanism to ensure the framework maintains a reasonable regularization strength and density reward conditioned on remaining computation resources. We conduct experiments on the bayesmark benchmark and important computer vision benchmarks such as ImageNet and COCO. Extensive experiments demonstrate the effectiveness of NRBO and it consistently outperforms other state-of-the-art methods.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021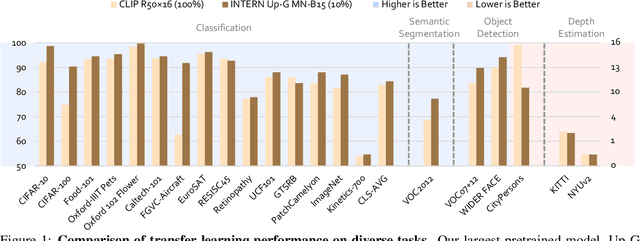
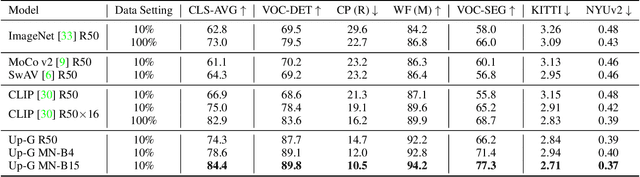
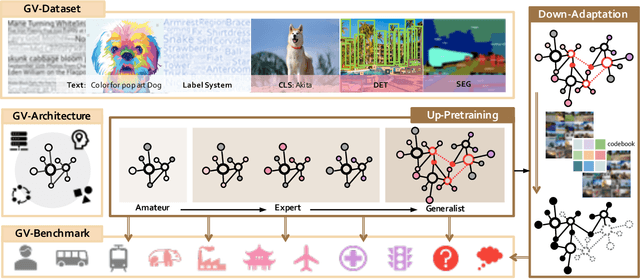
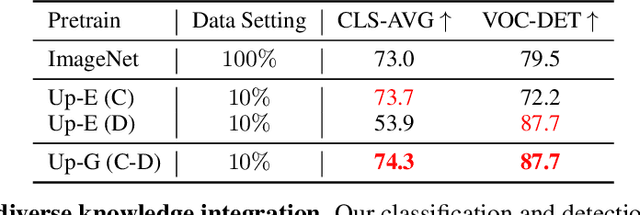
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.
ModuleNet: Knowledge-inherited Neural Architecture Search
Apr 14, 2020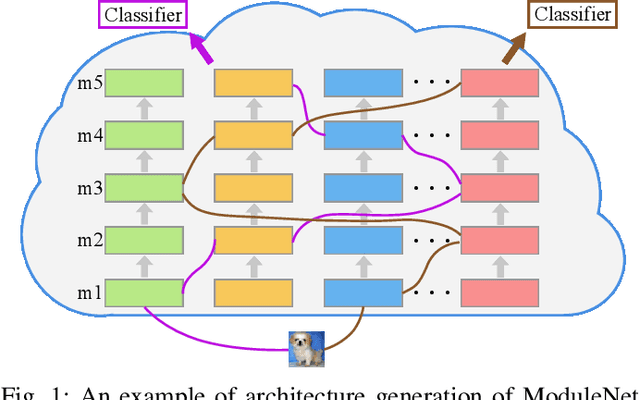
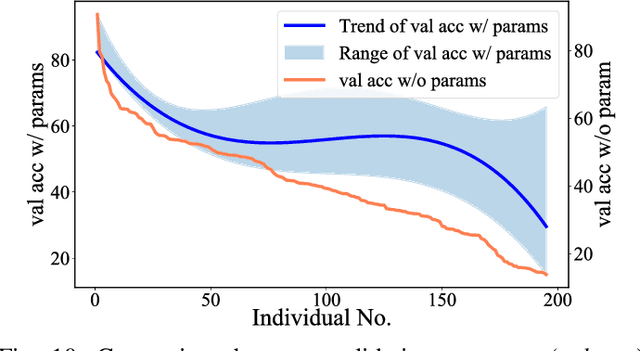

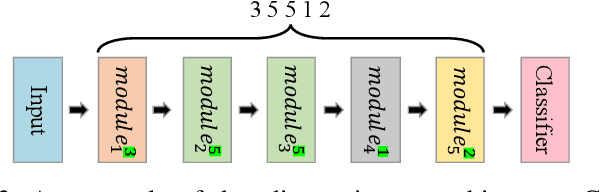
Although Neural Architecture Search (NAS) can bring improvement to deep models, they always neglect precious knowledge of existing models. The computation and time costing property in NAS also means that we should not start from scratch to search, but make every attempt to reuse the existing knowledge. In this paper, we discuss what kind of knowledge in a model can and should be used for new architecture design. Then, we propose a new NAS algorithm, namely ModuleNet, which can fully inherit knowledge from existing convolutional neural networks. To make full use of existing models, we decompose existing models into different \textit{module}s which also keep their weights, consisting of a knowledge base. Then we sample and search for new architecture according to the knowledge base. Unlike previous search algorithms, and benefiting from inherited knowledge, our method is able to directly search for architectures in the macro space by NSGA-II algorithm without tuning parameters in these \textit{module}s. Experiments show that our strategy can efficiently evaluate the performance of new architecture even without tuning weights in convolutional layers. With the help of knowledge we inherited, our search results can always achieve better performance on various datasets (CIFAR10, CIFAR100) over original architectures.