 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProUIE: A Macro-to-Micro Progressive Learning Method for LLM-based Universal Information Extraction
Apr 12, 2026LLM-based universal information extraction (UIE) methods often rely on additional information beyond the original training data, which increases training complexity yet often yields limited gains. To address this, we propose ProUIE, a Macro-to-Micro progressive learning approach that improves UIE without introducing any external information. ProUIE consists of three stages: (i) macro-level Complete Modeling (CM), which learns NER, RE, and EE along their intrinsic difficulty order on the full training data to build a unified extraction foundation, (ii) meso-level Streamlined Alignment (SA), which operates on sampled data with simplified target formats, streamlining and regularizing structured outputs to make them more concise and controllable, and (iii) micro-level Deep Exploration (DE), which applies GRPO with stepwise fine-grained rewards (SFR) over structural units to guide exploration and improve performance. Experiments on 36 public datasets show that ProUIE consistently improves unified extraction, outperforming strong instruction-tuned baselines on average for NER and RE while using a smaller backbone, and it further demonstrates clear gains in large-scale production-oriented information extraction.
TempoFit: Plug-and-Play Layer-Wise Temporal KV Memory for Long-Horizon Vision-Language-Action Manipulation
Mar 08, 2026Pretrained Vision-Language-Action (VLA) policies have achieved strong single-step manipulation, but their inference remains largely memoryless, which is brittle in non-Markovian long-horizon settings with occlusion, state aliasing, and subtle post-action changes. Prior approaches inject history either by stacking frames, which scales visual tokens and latency while adding near-duplicate pixels, or by learning additional temporal interfaces that require (re-)training and may break the original single-frame inference graph. We present TempoFit, a training-free temporal retrofit that upgrades frozen VLAs through state-level memory. Our key insight is that prefix attention K/V already form a model-native, content-addressable runtime state; reusing them across timesteps introduces history without new tokens or trainable modules. TempoFit stores layer-wise FIFO prefix K/V at selected intermediate layers, performs parameter-free K-to-K retrieval with Frame-Gap Temporal Bias (FGTB), a fixed recency bias inspired by positional biases in NLP, to keep decisions present-dominant, and injects the retrieved context via pre-attention residual loading with norm-preserving rescaling to avoid distribution shift under frozen weights. On LIBERO-LONG, TempoFit improves strong pretrained backbones by up to +4.0% average success rate while maintaining near-real-time latency, and it transfers consistently to CALVIN and real-robot long-horizon tasks.
Force-Aware Residual DAgger via Trajectory Editing for Precision Insertion with Impedance Control
Mar 04, 2026Imitation learning (IL) has shown strong potential for contact-rich precision insertion tasks. However, its practical deployment is often hindered by covariate shift and the need for continuous expert monitoring to recover from failures during execution. In this paper, we propose Trajectory Editing Residual Dataset Aggregation (TER-DAgger), a scalable and force-aware human-in-the-loop imitation learning framework that mitigates covariate shift by learning residual policies through optimization-based trajectory editing. This approach smoothly fuses policy rollouts with human corrective trajectories, providing consistent and stable supervision. Second, we introduce a force-aware failure anticipation mechanism that triggers human intervention only when discrepancies arise between predicted and measured end-effector forces, significantly reducing the requirement for continuous expert monitoring. Third, all learned policies are executed within a Cartesian impedance control framework, ensuring compliant and safe behavior during contact-rich interactions. Extensive experiments in both simulation and real-world precision insertion tasks show that TER-DAgger improves the average success rate by over 37\% compared to behavior cloning, human-guided correction, retraining, and fine-tuning baselines, demonstrating its effectiveness in mitigating covariate shift and enabling scalable deployment in contact-rich manipulation.
Robotic Sim-to-Real Transfer for Long-Horizon Pick-and-Place Tasks in the Robotic Sim2Real Competition
Mar 14, 2025This paper presents a fully autonomous robotic system that performs sim-to-real transfer in complex long-horizon tasks involving navigation, recognition, grasping, and stacking in an environment with multiple obstacles. The key feature of the system is the ability to overcome typical sensing and actuation discrepancies during sim-to-real transfer and to achieve consistent performance without any algorithmic modifications. To accomplish this, a lightweight noise-resistant visual perception system and a nonlinearity-robust servo system are adopted. We conduct a series of tests in both simulated and real-world environments. The visual perception system achieves the speed of 11 ms per frame due to its lightweight nature, and the servo system achieves sub-centimeter accuracy with the proposed controller. Both exhibit high consistency during sim-to-real transfer. Benefiting from these, our robotic system took first place in the mineral searching task of the Robotic Sim2Real Challenge hosted at ICRA 2024.
Sample-efficient Unsupervised Policy Cloning from Ensemble Self-supervised Labeled Videos
Dec 14, 2024



Current advanced policy learning methodologies have demonstrated the ability to develop expert-level strategies when provided enough information. However, their requirements, including task-specific rewards, expert-labeled trajectories, and huge environmental interactions, can be expensive or even unavailable in many scenarios. In contrast, humans can efficiently acquire skills within a few trials and errors by imitating easily accessible internet video, in the absence of any other supervision. In this paper, we try to let machines replicate this efficient watching-and-learning process through Unsupervised Policy from Ensemble Self-supervised labeled Videos (UPESV), a novel framework to efficiently learn policies from videos without any other expert supervision. UPESV trains a video labeling model to infer the expert actions in expert videos, through several organically combined self-supervised tasks. Each task performs its own duties, and they together enable the model to make full use of both expert videos and reward-free interactions for advanced dynamics understanding and robust prediction. Simultaneously, UPESV clones a policy from the labeled expert videos, in turn collecting environmental interactions for self-supervised tasks. After a sample-efficient and unsupervised (i.e., reward-free) training process, an advanced video-imitated policy is obtained. Extensive experiments in sixteen challenging procedurally-generated environments demonstrate that the proposed UPESV achieves state-of-the-art few-shot policy learning (outperforming five current advanced baselines on 12/16 tasks) without exposure to any other supervision except videos. Detailed analysis is also provided, verifying the necessity of each self-supervised task employed in UPESV.
GAPartManip: A Large-scale Part-centric Dataset for Material-Agnostic Articulated Object Manipulation
Nov 27, 2024Effectively manipulating articulated objects in household scenarios is a crucial step toward achieving general embodied artificial intelligence. Mainstream research in 3D vision has primarily focused on manipulation through depth perception and pose detection. However, in real-world environments, these methods often face challenges due to imperfect depth perception, such as with transparent lids and reflective handles. Moreover, they generally lack the diversity in part-based interactions required for flexible and adaptable manipulation. To address these challenges, we introduced a large-scale part-centric dataset for articulated object manipulation that features both photo-realistic material randomizations and detailed annotations of part-oriented, scene-level actionable interaction poses. We evaluated the effectiveness of our dataset by integrating it with several state-of-the-art methods for depth estimation and interaction pose prediction. Additionally, we proposed a novel modular framework that delivers superior and robust performance for generalizable articulated object manipulation. Our extensive experiments demonstrate that our dataset significantly improves the performance of depth perception and actionable interaction pose prediction in both simulation and real-world scenarios.
PlanAgent: A Multi-modal Large Language Agent for Closed-loop Vehicle Motion Planning
Jun 04, 2024



Vehicle motion planning is an essential component of autonomous driving technology. Current rule-based vehicle motion planning methods perform satisfactorily in common scenarios but struggle to generalize to long-tailed situations. Meanwhile, learning-based methods have yet to achieve superior performance over rule-based approaches in large-scale closed-loop scenarios. To address these issues, we propose PlanAgent, the first mid-to-mid planning system based on a Multi-modal Large Language Model (MLLM). MLLM is used as a cognitive agent to introduce human-like knowledge, interpretability, and common-sense reasoning into the closed-loop planning. Specifically, PlanAgent leverages the power of MLLM through three core modules. First, an Environment Transformation module constructs a Bird's Eye View (BEV) map and a lane-graph-based textual description from the environment as inputs. Second, a Reasoning Engine module introduces a hierarchical chain-of-thought from scene understanding to lateral and longitudinal motion instructions, culminating in planner code generation. Last, a Reflection module is integrated to simulate and evaluate the generated planner for reducing MLLM's uncertainty. PlanAgent is endowed with the common-sense reasoning and generalization capability of MLLM, which empowers it to effectively tackle both common and complex long-tailed scenarios. Our proposed PlanAgent is evaluated on the large-scale and challenging nuPlan benchmarks. A comprehensive set of experiments convincingly demonstrates that PlanAgent outperforms the existing state-of-the-art in the closed-loop motion planning task. Codes will be soon released.
Learning Future Representation with Synthetic Observations for Sample-efficient Reinforcement Learning
May 20, 2024
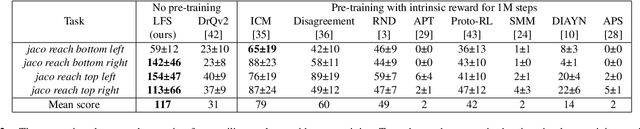

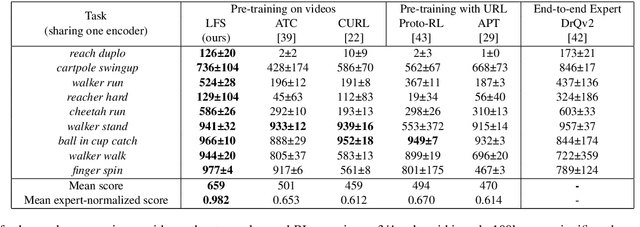
In visual Reinforcement Learning (RL), upstream representation learning largely determines the effect of downstream policy learning. Employing auxiliary tasks allows the agent to enhance visual representation in a targeted manner, thereby improving the sample efficiency and performance of downstream RL. Prior advanced auxiliary tasks all focus on how to extract as much information as possible from limited experience (including observations, actions, and rewards) through their different auxiliary objectives, whereas in this article, we first start from another perspective: auxiliary training data. We try to improve auxiliary representation learning for RL by enriching auxiliary training data, proposing \textbf{L}earning \textbf{F}uture representation with \textbf{S}ynthetic observations \textbf{(LFS)}, a novel self-supervised RL approach. Specifically, we propose a training-free method to synthesize observations that may contain future information, as well as a data selection approach to eliminate unqualified synthetic noise. The remaining synthetic observations and real observations then serve as the auxiliary data to achieve a clustering-based temporal association task for representation learning. LFS allows the agent to access and learn observations that have not yet appeared in advance, so as to quickly understand and exploit them when they occur later. In addition, LFS does not rely on rewards or actions, which means it has a wider scope of application (e.g., learning from video) than recent advanced auxiliary tasks. Extensive experiments demonstrate that our LFS exhibits state-of-the-art RL sample efficiency on challenging continuous control and enables advanced visual pre-training based on action-free video demonstrations.
Advancing Object Goal Navigation Through LLM-enhanced Object Affinities Transfer
Mar 15, 2024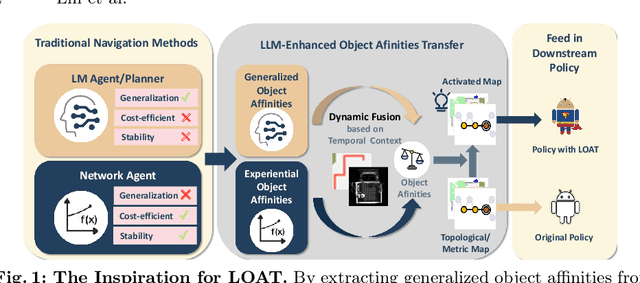
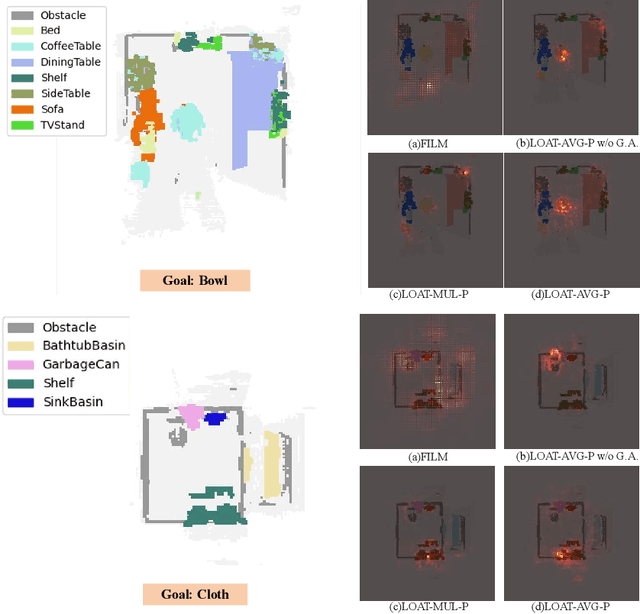
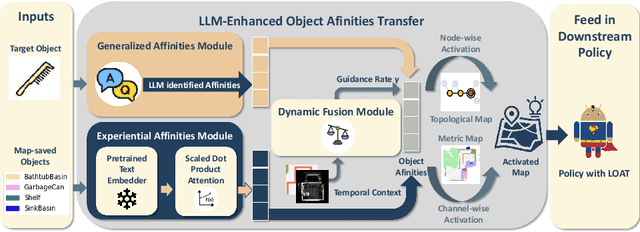
In object goal navigation, agents navigate towards objects identified by category labels using visual and spatial information. Previously, solely network-based methods typically rely on historical data for object affinities estimation, lacking adaptability to new environments and unseen targets. Simultaneously, employing Large Language Models (LLMs) for navigation as either planners or agents, though offering a broad knowledge base, is cost-inefficient and lacks targeted historical experience. Addressing these challenges, we present the LLM-enhanced Object Affinities Transfer (LOAT) framework, integrating LLM-derived object semantics with network-based approaches to leverage experiential object affinities, thus improving adaptability in unfamiliar settings. LOAT employs a dual-module strategy: a generalized affinities module for accessing LLMs' vast knowledge and an experiential affinities module for applying learned object semantic relationships, complemented by a dynamic fusion module harmonizing these information sources based on temporal context. The resulting scores activate semantic maps before feeding into downstream policies, enhancing navigation systems with context-aware inputs. Our evaluations in AI2-THOR and Habitat simulators demonstrate improvements in both navigation success rates and efficiency, validating the LOAT's efficacy in integrating LLM insights for improved object goal navigation.
RoboGPT: an intelligent agent of making embodied long-term decisions for daily instruction tasks
Nov 27, 2023Robotic agents must master common sense and long-term sequential decisions to solve daily tasks through natural language instruction. The developments in Large Language Models (LLMs) in natural language processing have inspired efforts to use LLMs in complex robot planning. Despite LLMs' great generalization and comprehension of instruction tasks, LLMs-generated task plans sometimes lack feasibility and correctness. To address the problem, we propose a RoboGPT agent\footnote{our code and dataset will be released soon} for making embodied long-term decisions for daily tasks, with two modules: 1) LLMs-based planning with re-plan to break the task into multiple sub-goals; 2) RoboSkill individually designed for sub-goals to learn better navigation and manipulation skills. The LLMs-based planning is enhanced with a new robotic dataset and re-plan, called RoboGPT. The new robotic dataset of 67k daily instruction tasks is gathered for fine-tuning the Llama model and obtaining RoboGPT. RoboGPT planner with strong generalization can plan hundreds of daily instruction tasks. Additionally, a low-computational Re-Plan module is designed to allow plans to flexibly adapt to the environment, thereby addressing the nomenclature diversity challenge. The proposed RoboGPT agent outperforms SOTA methods on the ALFRED daily tasks. Moreover, RoboGPT planner exceeds SOTA LLM-based planners like ChatGPT in task-planning rationality for hundreds of unseen daily tasks, and even other domain tasks, while keeping the large model's original broad application and generality.