 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025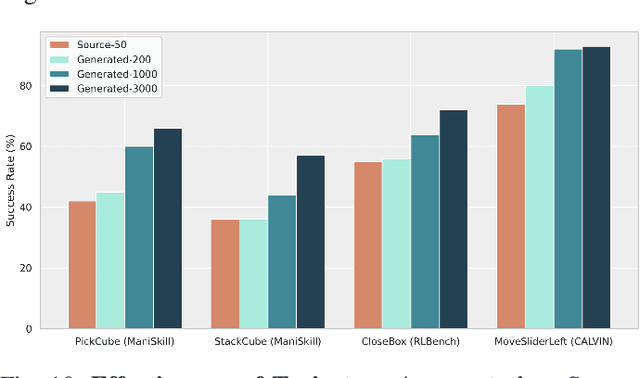



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Mar 25, 2025While recent vision-language-action models trained on diverse robot datasets exhibit promising generalization capabilities with limited in-domain data, their reliance on compact action heads to predict discretized or continuous actions constrains adaptability to heterogeneous action spaces. We present Dita, a scalable framework that leverages Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Departing from prior methods that condition denoising on fused embeddings via shallow networks, Dita employs in-context conditioning -- enabling fine-grained alignment between denoised actions and raw visual tokens from historical observations. This design explicitly models action deltas and environmental nuances. By scaling the diffusion action denoiser alongside the Transformer's scalability, Dita effectively integrates cross-embodiment datasets across diverse camera perspectives, observation scenes, tasks, and action spaces. Such synergy enhances robustness against various variances and facilitates the successful execution of long-horizon tasks. Evaluations across extensive benchmarks demonstrate state-of-the-art or comparative performance in simulation. Notably, Dita achieves robust real-world adaptation to environmental variances and complex long-horizon tasks through 10-shot finetuning, using only third-person camera inputs. The architecture establishes a versatile, lightweight and open-source baseline for generalist robot policy learning. Project Page: https://robodita.github.io.
GAPartManip: A Large-scale Part-centric Dataset for Material-Agnostic Articulated Object Manipulation
Nov 27, 2024Effectively manipulating articulated objects in household scenarios is a crucial step toward achieving general embodied artificial intelligence. Mainstream research in 3D vision has primarily focused on manipulation through depth perception and pose detection. However, in real-world environments, these methods often face challenges due to imperfect depth perception, such as with transparent lids and reflective handles. Moreover, they generally lack the diversity in part-based interactions required for flexible and adaptable manipulation. To address these challenges, we introduced a large-scale part-centric dataset for articulated object manipulation that features both photo-realistic material randomizations and detailed annotations of part-oriented, scene-level actionable interaction poses. We evaluated the effectiveness of our dataset by integrating it with several state-of-the-art methods for depth estimation and interaction pose prediction. Additionally, we proposed a novel modular framework that delivers superior and robust performance for generalizable articulated object manipulation. Our extensive experiments demonstrate that our dataset significantly improves the performance of depth perception and actionable interaction pose prediction in both simulation and real-world scenarios.
Diffusion Transformer Policy
Oct 21, 2024



Recent large visual-language action models pretrained on diverse robot datasets have demonstrated the potential for generalizing to new environments with a few in-domain data. However, those approaches usually predict discretized or continuous actions by a small action head, which limits the ability in handling diverse action spaces. In contrast, we model the continuous action with a large multi-modal diffusion transformer, dubbed as Diffusion Transformer Policy, in which we directly denoise action chunks by a large transformer model rather than a small action head. By leveraging the scaling capability of transformers, the proposed approach can effectively model continuous end-effector actions across large diverse robot datasets, and achieve better generalization performance. Extensive experiments demonstrate Diffusion Transformer Policy pretrained on diverse robot data can generalize to different embodiments, including simulation environments like Maniskill2 and Calvin, as well as the real-world Franka arm. Specifically, without bells and whistles, the proposed approach achieves state-of-the-art performance with only a single third-view camera stream in the Calvin novel task setting (ABC->D), improving the average number of tasks completed in a row of 5 to 3.6, and the pretraining stage significantly facilitates the success sequence length on the Calvin by over 1.2. The code will be publicly available.
D3RoMa: Disparity Diffusion-based Depth Sensing for Material-Agnostic Robotic Manipulation
Sep 25, 2024



Depth sensing is an important problem for 3D vision-based robotics. Yet, a real-world active stereo or ToF depth camera often produces noisy and incomplete depth which bottlenecks robot performances. In this work, we propose D3RoMa, a learning-based depth estimation framework on stereo image pairs that predicts clean and accurate depth in diverse indoor scenes, even in the most challenging scenarios with translucent or specular surfaces where classical depth sensing completely fails. Key to our method is that we unify depth estimation and restoration into an image-to-image translation problem by predicting the disparity map with a denoising diffusion probabilistic model. At inference time, we further incorporated a left-right consistency constraint as classifier guidance to the diffusion process. Our framework combines recently advanced learning-based approaches and geometric constraints from traditional stereo vision. For model training, we create a large scene-level synthetic dataset with diverse transparent and specular objects to compensate for existing tabletop datasets. The trained model can be directly applied to real-world in-the-wild scenes and achieve state-of-the-art performance in multiple public depth estimation benchmarks. Further experiments in real environments show that accurate depth prediction significantly improves robotic manipulation in various scenarios.
TextPSG: Panoptic Scene Graph Generation from Textual Descriptions
Oct 10, 2023



Panoptic Scene Graph has recently been proposed for comprehensive scene understanding. However, previous works adopt a fully-supervised learning manner, requiring large amounts of pixel-wise densely-annotated data, which is always tedious and expensive to obtain. To address this limitation, we study a new problem of Panoptic Scene Graph Generation from Purely Textual Descriptions (Caption-to-PSG). The key idea is to leverage the large collection of free image-caption data on the Web alone to generate panoptic scene graphs. The problem is very challenging for three constraints: 1) no location priors; 2) no explicit links between visual regions and textual entities; and 3) no pre-defined concept sets. To tackle this problem, we propose a new framework TextPSG consisting of four modules, i.e., a region grouper, an entity grounder, a segment merger, and a label generator, with several novel techniques. The region grouper first groups image pixels into different segments and the entity grounder then aligns visual segments with language entities based on the textual description of the segment being referred to. The grounding results can thus serve as pseudo labels enabling the segment merger to learn the segment similarity as well as guiding the label generator to learn object semantics and relation predicates, resulting in a fine-grained structured scene understanding. Our framework is effective, significantly outperforming the baselines and achieving strong out-of-distribution robustness. We perform comprehensive ablation studies to corroborate the effectiveness of our design choices and provide an in-depth analysis to highlight future directions. Our code, data, and results are available on our project page: https://vis-www.cs.umass.edu/TextPSG.
GAPartNet: Cross-Category Domain-Generalizable Object Perception and Manipulation via Generalizable and Actionable Parts
Nov 10, 2022



Perceiving and manipulating objects in a generalizable way has been actively studied by the computer vision and robotics communities, where cross-category generalizable manipulation skills are highly desired yet underexplored. In this work, we propose to learn such generalizable perception and manipulation via Generalizable and Actionable Parts (GAParts). By identifying and defining 9 GAPart classes (e.g. buttons, handles, etc), we show that our part-centric approach allows our method to learn object perception and manipulation skills from seen object categories and directly generalize to unseen categories. Following the GAPart definition, we construct a large-scale part-centric interactive dataset, GAPartNet, where rich, part-level annotations (semantics, poses) are provided for 1166 objects and 8489 part instances. Based on GAPartNet, we investigate three cross-category tasks: part segmentation, part pose estimation, and part-based object manipulation. Given the large domain gaps between seen and unseen object categories, we propose a strong 3D segmentation method from the perspective of domain generalization by integrating adversarial learning techniques. Our method outperforms all existing methods by a large margin, no matter on seen or unseen categories. Furthermore, with part segmentation and pose estimation results, we leverage the GAPart pose definition to design part-based manipulation heuristics that can generalize well to unseen object categories in both simulation and real world. The dataset and code will be released.